- The paper presents a novel three-stage framework that uses planning, verification, and execution to enhance graph-based retrieval.
- It leverages LLMs to generate and validate multi-hop traversal plans, reducing reasoning errors and computational costs.
- Experimental results show a 10-50% performance boost and up to 12.9x cost reduction compared to traditional RAG methods.
GraphRunner: A Multi-Stage Framework for Efficient and Accurate Graph-Based Retrieval
The paper "GraphRunner: A Multi-Stage Framework for Efficient and Accurate Graph-Based Retrieval" presents a novel framework aimed at mitigating the limitations of traditional Retrieval Augmented Generation (RAG) methods when applied to interconnected, structured datasets such as knowledge graphs. GraphRunner leverages LLMs to enhance retrieval accuracy and reduce computational costs.
Introduction and Motivation
Existing RAG approaches have shown efficacy in processing unstructured textual datasets but display significant weakness in structured datasets where understanding relations is crucial. The challenges are magnified by LLMs’ susceptibility to reasoning errors and hallucinations when dealing with iterative graph traversals. Current methods relying on iterative, rule-based traversal, offer limited efficiency due to single-step hop exploration and undetected hallucinations.
In response, GraphRunner is introduced as a three-stage process: planning, verification, and execution. This pipeline includes high-level traversal actions, enabling more efficient multi-hop exploration and mitigating LLM reasoning errors by verifying traversal plans before execution, thus enhancing reliability and cost-efficiency.
GraphRunner Framework
GraphRunner incorporates three main components: the GraphRunner Agent, Traversal Planning Module, and Traversal Plan Verification Module. These components operate collaboratively to execute graph-based retrieval tasks efficiently and accurately.
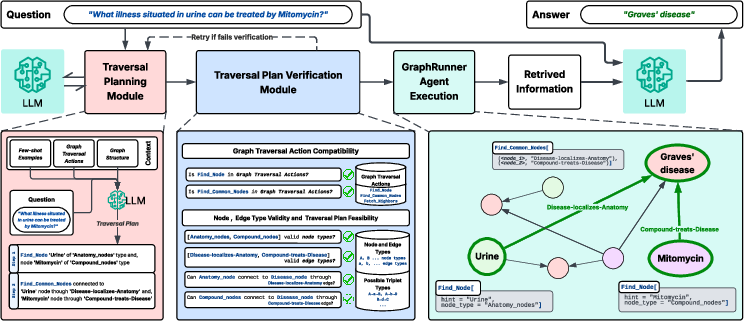
Figure 1: GraphRunner Framework - Given a question, a holistic traversal plan is generated by the Traversal Planning module and verified against the graph and possible traversal actions in the Traversal Plan Verification Module. Once verified, the plan is executed to extract relevant information from the graph by the GraphRunner Agent, which is then used as context to answer the question.
GraphRunner Agent
The core execution component, the GraphRunner Agent, performs graph traversal operations (Figure 2). It employs three high-level traversal actions: Find_Node, Fetch_Neighbors, and Find_Common_Nodes. These actions empower the agent to navigate knowledge graphs efficiently, identifying specific nodes, traversing relationships, and locating shared neighbors.

Figure 2: \begin{figure}[H] \includegraphics[width=0.7\linewidth]{figures/find_nodes.pdf} \end{figure}
Through these actions, the GraphRunner Agent can perform complex multi-hop graph explorations in a single step, streamlining the retrieval process.

Figure 3: \begin{figure}[H] \includegraphics[width=0.7\linewidth]{figures/find_neighbors.pdf} \end{figure}

Figure 4: \begin{figure}[H] \includegraphics[width=0.7\linewidth]{figures/find_common_nodes.pdf} \end{figure}
Traversal Planning and Verification
The Traversal Planning Module generates a holistic traversal plan by using LLMs for sophisticated reasoning over the graph structure, as denoted in Figure 1. This plan encompasses a series of traversal steps, crafted by the LLM, that the agent needs to follow.
The Traversal Plan Verification Module ensures the plan's executability and compatibility with pre-defined actions and the graph’s structure. This crucial stage detects hallucinated plans before execution, circumventing unnecessary computations and enhancing accuracy (Figure 5).
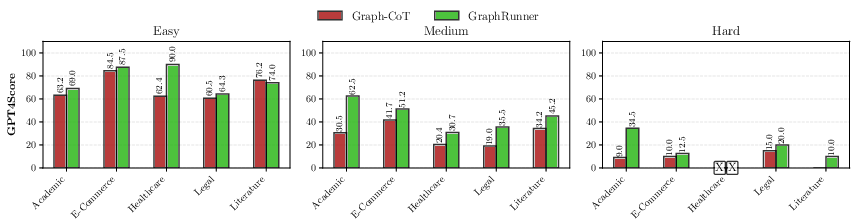
Figure 5: Performance improvements of GraphRunner across all domains and difficulty levels in the dataset, evaluated using GPT4Score. The experiments were conducted using GPT-4. Note that only easy and medium difficulty questions are available for the healthcare domain.
Experimentation and Results
GraphRunner's efficacy was benchmarked against existing methods using the dataset, demonstrating superior performance across all domains and complexity levels. The results showcased significant improvements in accuracy, inference costs, and response generation speed.
Compared to baseline approaches such as Text-based RAG, Graph-based RAG, and Graph-CoT, GraphRunner consistently yielded 10-50% performance improvements based on GPT4Score, as illustrated in Table~\ref{tab:overall} and Figure 5. Moreover, it achieved a reduction in inference costs by up to 12.9 times and a speedup in response generation time by up to 7.1 times (Figure 6).
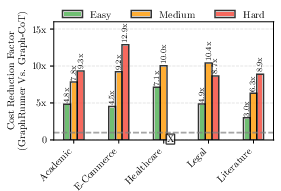
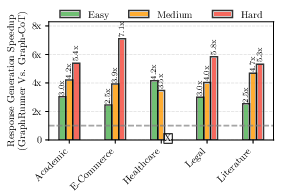
Figure 6: GraphRunner exhibits notable efficiency improvements over across all domains and difficulty levels in the dataset.
The framework's separation of planning and execution stages, combined with high-level traversal actions, significantly underpins these efficiency gains. This methodological innovation limits LLM dependencies, reducing reasoning errors and hallucinations during information retrieval processes.
Limitations and Future Work
A notable limitation of GraphRunner is its reliance on OpenAI’s proprietary GPT-4 API, and its testing confined to a single dataset. Evaluations with open-source LLMs with fine-tuning abilities and diverse datasets would enhance the robustness of the findings. The emergence of datasets with a wider range of question types and corresponding graphs would benefit a more comprehensive assessment of generalization and application potential.
Conclusion
GraphRunner emerges as an advanced framework engineered to elevate the efficiency and accuracy of graph-based retrieval tasks. By adopting a three-stage process of planning, verifying, and executing, and utilizing high-level traversal actions, GraphRunner overcomes the pitfalls of conventional RAG mechanisms, offering improvements in performance metrics and operational efficiency. This research highlights a promising direction for enhancing the interaction between LLMs and knowledge graphs, paving the way for more reliable and effective graph-based AI applications.