- The paper introduces OnlineBEV, which employs a recurrent framework and the Motion-Guided BEV Fusion Network (MBFNet) to align historical and current BEV features.
- It utilizes a heatmap-based HTC-loss for temporal consistency and achieves state-of-the-art performance on benchmarks with 63.9% NDS.
- The method demonstrates robust feature fusion under dynamic and adverse conditions while optimizing memory usage through efficient temporal aggregation.
OnlineBEV: Recurrent Temporal Fusion in Bird's Eye View Representations for Multi-Camera 3D Perception
Introduction
OnlineBEV innovatively addresses the limitation in multi-view camera-based 3D perception, particularly in scenarios where temporal aggregation of sequential BEV features is desired. Conventional methods often face challenges in handling feature alignment due to dynamic scene changes, affecting performance. OnlineBEV employs a novel temporal 3D perception approach utilizing a recurrent structure, significantly improving feature combination efficiency while containing memory usage. The architecture's core innovation centers on temporal alignment through the Motion-Guided BEV Fusion Network (MBFNet), leveraging historical and current BEV feature alignment, guided by motion features.
Architecture and Key Innovations
The architecture of OnlineBEV is depicted in (Figure 1). It aggregates historical with current BEV features using a recurrent framework. Before this aggregation, MBFNet performs temporal feature alignment, which is facilitated by the Motion Feature Extractor (MFE) and the Motion-Guided BEV Warping Attention (MGWA). This alignment is crucial for offsetting the spatial changes in dynamic scenes caused by object motion.
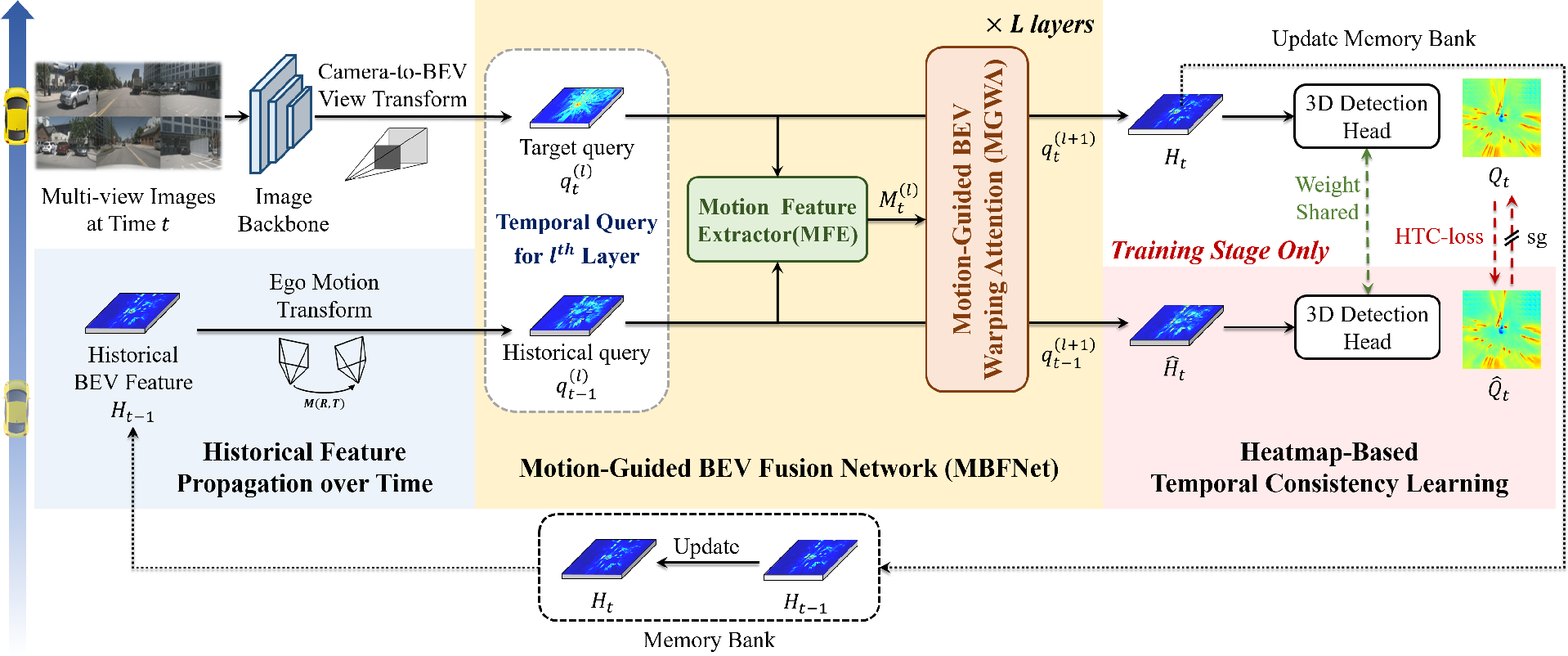
Figure 1: The overall architecture of OnlineBEV showing feature aggregation through recurrent structure and alignment via MBFNet.
OnlineBEV introduces temporal consistency learning through a heatmap-based loss (HTC-loss), which aids in aligning features by penalizing discrepancies between historical and target BEV features. This innovative approach allows OnlineBEV to utilize temporal information more robustly, with significant performance improvements demonstrated on nuScenes benchmarks. The model achieves a notable 63.9% NDS on the nuScenes test set, surpassing SOLOFusion.
Motion-Guided BEV Fusion Network (MBFNet)
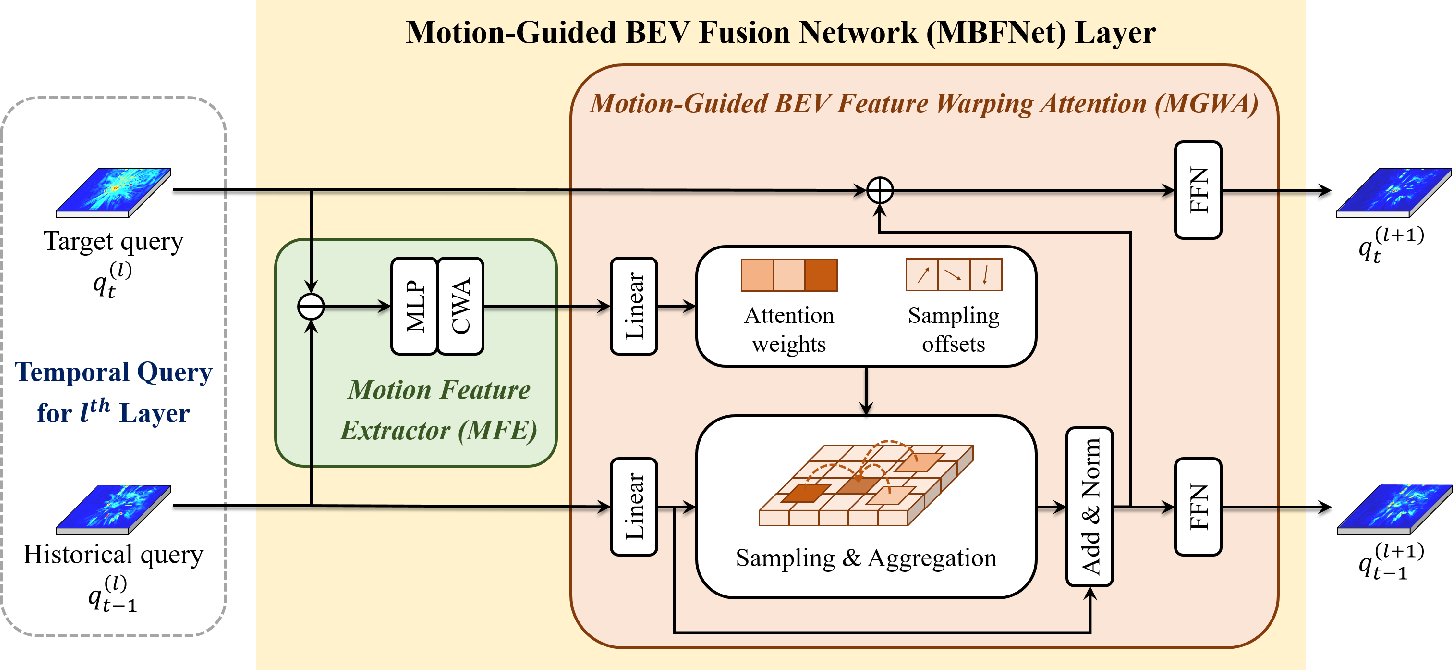
Figure 2: Structure of MBFNet, incorporating MFE and MGWA for feature alignment and fusion.
MBFNet consists of two modules: MFE, which generates motion features, and MGWA, which deploys deformable attention mechanisms. The MFE captures spatial changes by computing differential encoding between historical and current BEV queries, while MGWA utilizes these motion features to achieve precise feature alignment through deformable attention mechanisms. The aligned historical features then merge with current features, producing a fused BEV representation.
Experimental Results
OnlineBEV was evaluated against multiple methods using the nuScenes and Argoverse 2 datasets. Tables 1 and 2 detail performance comparisons, illustrating OnlineBEV's superior detection metrics achieved with reduced computational cost. Notably, OnlineBEV demonstrated remarkable robustness under image corruption conditions, maintaining higher mAP and NDS compared to contemporaries. An ablation study further clarified the contributions of recurrent fusion, MBFNet, and HTC-loss to the overall architecture’s efficacy.
Robustness and Efficiency
The robustness of OnlineBEV in handling real-world challenges like motion blur and occlusions is highlighted in Table 3, confirming its performance advantage under adverse conditions. This is attributed to effective temporal and spatial realignment of features across time. Additionally, the model's recurrent structure allows for substantial frame aggregation without proportional increases in memory usage, a significant improvement over parallel fusion strategies.
Conclusion
OnlineBEV demonstrates a significant advancement in multi-camera 3D perception by effectively leveraging temporal information through innovative feature alignment strategies. Future work may involve integrating explicit motion information, utilizing real-world data from LiDAR or radar sensors for enhanced feature alignment supervision. Such developments promise further refinement in temporal fusion methodologies, enhancing the robustness and adaptability of 3D perception systems in dynamic environments.