- The paper introduces a novel cross-modality masked learning framework that integrates 3D CT images and clinical records to predict survival for ICI-treated NSCLC patients.
- It employs dedicated visual and tabular branches using transformers with masked pretraining and fine-tuning, achieving superior CI scores of 0.701 for PFS and 0.705 for OS.
- The study demonstrates that optimized mask ratios and effective cross-modality fusion significantly enhance prognostic accuracy, setting a new benchmark in multimodal learning.
Cross-Modality Masked Learning for Survival Prediction in ICI Treated NSCLC Patients
Introduction
The study addresses the challenge of survival prediction for non-small cell lung cancer (NSCLC) patients undergoing immunotherapy, specifically using immune checkpoint inhibitors (ICIs). The work presents a novel framework that leverages multi-modal data, integrating 3D computed tomography (CT) images and clinical records. The primary innovation is the cross-modality masked learning approach, aiming to enhance feature fusion between different data modalities, ultimately improving prognostic accuracy.
Methodology
The proposed model operates with two dedicated branches for handling diverse modalities: a visual branch using a 3D visual transformer for CT images, and a tabular branch leveraging a graph-based transformer for clinical data. Each branch undergoes a two-stage training process involving initial pretraining with masked learning, followed by task-specific fine-tuning using a survival prediction objective.
- Visual Branch: Utilizes a Slice-Depth Transformer to extract CT image features, implementing slice-based attention and depth-based attention mechanisms to capture spatial and contextual information. The modality-specific encoder operates on masked image patches to encourage robust feature learning.
- Tabular Branch: Employs a graph-based transformer inspired by T2G-Former, encoding clinical variables as graph nodes and modeling their interactions through adaptable attention mechanisms. The masked learning setup involves random masking of clinical variables, with specialized variable-specific masked embeddings aiding in efficient reconstruction.
- Cross-Modality Completion: This process integrates features across branches by reconstructing masked modalities using intact features from the alternative modality, thereby enhancing inter-modality information alignment (Figure 1).
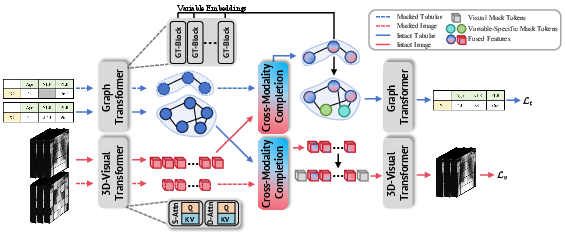
Figure 1: During pretraining, both intact and masked versions of each modality are input into their respective branches. In the multi-modal completion process, the masked modality integrates features from the intact version of the other modality, which are then passed into the decoder for reconstruction.
Experiments and Results
The study presents results on a significant dataset comprising 2,128 NSCLC patient records. Performance evaluation involves progression-free survival (PFS) and overall survival (OS) predictions, measured using the Concordance Index (CI). The proposed method outperforms competitive baselines, including models like the Cox proportional hazards model, demonstrating the efficacy of the cross-modality masked learning approach.
Conclusion
The methodology provides significant improvements in survival prediction tasks for NSCLC patients undergoing ICI treatment by effectively integrating multimodal data. The cross-modality masked learning strategy ensures that complementary information from both modalities (CT images and clinical data) is exploited, thereby enhancing prognostic accuracy. Future research may explore further adaptations of this framework to other multi-modal datasets and consider extensions to incorporate additional data modalities.
Overall, this work sets a new benchmark in the field of multimodal learning for medical prognosis, particularly in the context of cancer treatment response analysis.