- The paper introduces SAILViT, a novel vision model that employs a three-stage training pipeline to refine features and bridge modality gaps between vision and language models.
- It demonstrates robust performance by unlocking LLM parameters during the world knowledge infusion stage, significantly enhancing multimodal reasoning.
- Extensive experiments and ablation studies reveal SAILViT’s scalability and competitive results on both multimodal tasks and standard visual recognition benchmarks.
SAILViT: Gradual Feature Refinement for Visual Backbones in MLLMs
This paper introduces SAILViT, a novel vision foundation model designed to enhance the visual comprehension capabilities of Multimodal LLMs (MLLMs). The key innovation lies in a gradual feature refinement training pipeline that addresses the challenges of parameter initialization conflicts and modality semantic gaps that often hinder effective co-training between Vision Transformers (ViTs) and LLMs. The authors demonstrate that SAILViT achieves state-of-the-art performance on a variety of multimodal tasks, showcasing its robustness and generalizability across different parameter sizes, model architectures, training strategies, and data scales.
Addressing Modality Gaps with Gradual Refinement
The core challenge in integrating ViTs with LLMs stems from the inherent differences in their pre-training objectives and data distributions. ViTs are typically pre-trained using image-text pair-based contrastive learning or self-supervised mechanisms, which primarily focus on capturing visual features. However, these pre-training strategies often fall short of providing the nuanced understanding of multimodal data and world knowledge required for complex MLLM tasks. SAILViT addresses this issue through a three-stage training process: coarse-grained alignment, fine-grained alignment, and world knowledge infusion.
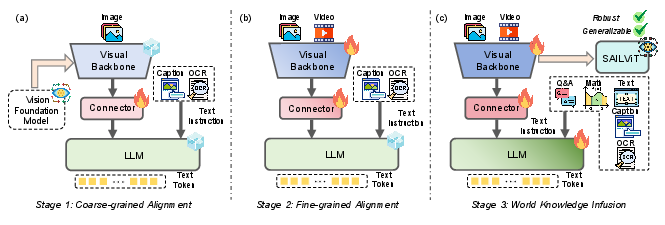
Figure 1: Illustration of the training pipeline for SAILViT by gradual feature refinement.
The coarse-grained alignment stage utilizes an MLP-driven connector to achieve initial adaptation across the modality feature space. This stage serves as a warm-up, establishing fundamental visual perception capabilities and improving subsequent training stability. The fine-grained alignment stage then simultaneously trains the visual backbone and connector, leveraging a richer dataset to enhance the expressiveness and semantic richness of visual elements. Finally, the world knowledge infusion stage unlocks all parameters, enabling joint training on multimodal instruction data to strengthen the multifaceted extraction capability for visual representations.
Empirical Validation of SAILViT's Capabilities
The authors conducted extensive experiments to evaluate the performance of SAILViT across a variety of benchmarks and settings. The results demonstrate that SAILViT consistently outperforms existing visual backbones, such as AIMv2 [fini2024multimodal] and InternViT [chen2024internvl], on the OpenCompass benchmark. Furthermore, SAILViT exhibits strong generalization capabilities, maintaining its performance gains when integrated with different LLMs, including InternLM2.5 [cai2024internlm2], Qwen2.5 [yang2024qwen2], and Qwen3 [qwen3] series models.
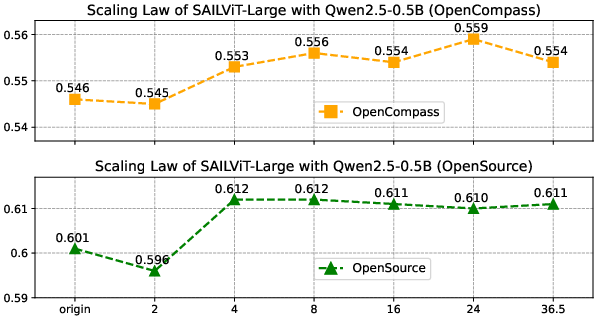
Figure 2: Illustration of the scaling law phenomenon analysis, showing increasing trends as the amount of data increases.
The authors also investigated the scaling behavior of SAILViT, demonstrating that its performance continues to improve as the amount of data in the world knowledge infusion stage increases. This suggests that SAILViT can effectively leverage large-scale multimodal data to learn more robust and generalizable visual representations.
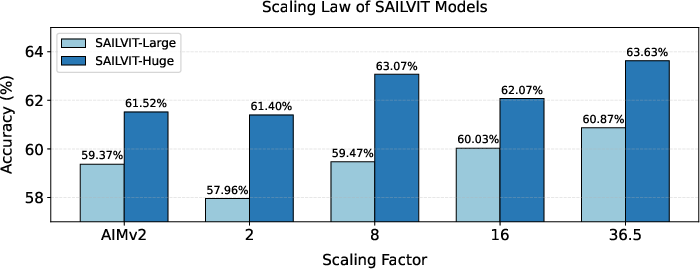
Figure 3: Scaling trend of average gains for SAILViT-Large/Huge, showing that there is still room for continued improvement in SAILViT performance.
Ablation Studies and Analysis
To gain deeper insights into the effectiveness of SAILViT, the authors performed a series of ablation studies, exploring the impact of different training strategies, data compositions, and evaluation regimes. These studies revealed several key findings. First, unlocking the LLM parameters during the world knowledge infusion stage leads to better performance, indicating that joint training is crucial for aligning visual and linguistic representations. Second, a multi-task uniform SFT training approach outperforms step-by-step training, suggesting that integrated knowledge learning is more effective in preventing model forgetting. Finally, SAILViT demonstrates robustness across different evaluation schemes, consistently outperforming alternative visual backbones.
In addition to multimodal tasks, the authors evaluated SAILViT on standard visual recognition tasks, such as ImageNet classification. The results show that SAILViT achieves competitive performance, demonstrating its ability to extract effective visual features for both generic image understanding and multimodal reasoning.
Conclusion and Future Directions
SAILViT represents a significant advancement in the development of visual backbones for MLLMs. The proposed gradual feature refinement training pipeline effectively addresses the challenges of modality gaps and parameter initialization conflicts, resulting in a more robust and generalizable visual representation. The experimental results demonstrate that SAILViT achieves state-of-the-art performance on a variety of multimodal tasks, showcasing its potential to enhance the capabilities of MLLMs.
The authors acknowledge the limitations of their work, including the need to evaluate SAILViT on larger datasets and more complex training strategies. They also propose several avenues for future research, such as exploring the compression of visual information into fewer tokens and investigating the construction of ViTs supporting native resolution. These future directions promise to further advance the field of visual-language understanding and pave the way for more powerful and versatile MLLMs.