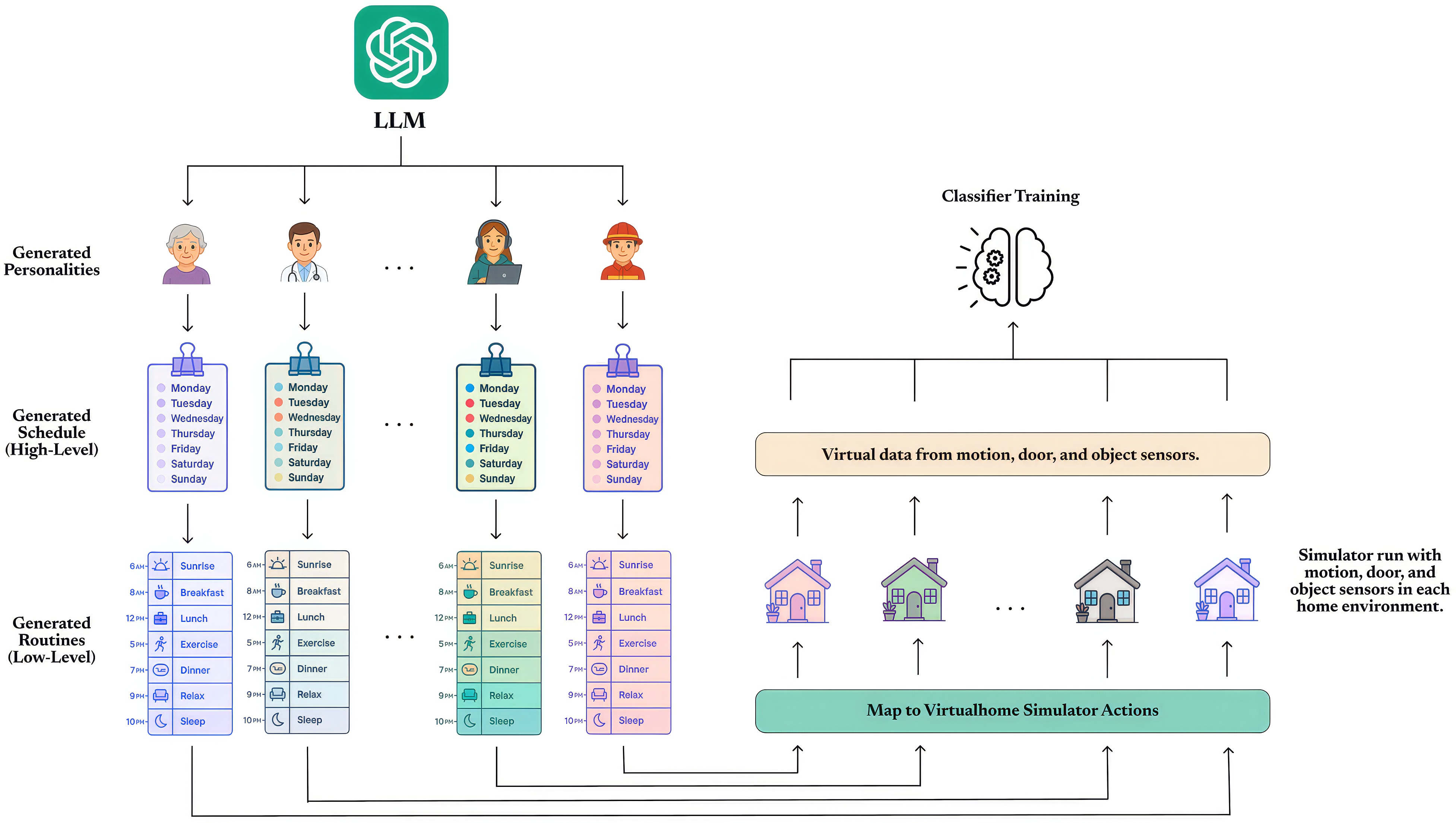
- The paper introduces a scalable simulation pipeline that uses LLM-driven persona, routine, and action generation to produce realistic virtual sensor data.
- It employs a multi-stage prompting strategy and an extended VirtualHome simulator to generate context-aware activity sequences with valid sensor events.
- Empirical results demonstrate improved HAR performance and data efficiency, with pretraining on virtual data markedly enhancing accuracy and F1 scores.
AgentSense: LLM-Driven Virtual Sensor Data Generation for Smart Home Human Activity Recognition
Introduction and Motivation
The development of robust Human Activity Recognition (HAR) systems for smart homes is fundamentally constrained by the scarcity of large-scale, diverse, and well-annotated sensor datasets. The heterogeneity of home layouts, sensor deployments, and user behaviors further exacerbates the challenge, as generalizable HAR models require exposure to a wide range of activity patterns and environmental contexts. Manual data collection and annotation in real homes is expensive, time-consuming, and often infeasible at scale. "AgentSense: Virtual Sensor Data Generation Using LLM Agents in Simulated Home Environments" (2506.11773) addresses this bottleneck by introducing a scalable, simulation-based pipeline that leverages LLMs to generate diverse human personas, routines, and fine-grained action sequences, which are then enacted in an extended VirtualHome simulator instrumented with virtual ambient sensors.
LLM-Driven Persona and Routine Generation
AgentSense employs a multi-level prompting strategy with LLMs to synthesize realistic and diverse human behaviors. The pipeline consists of three stages:
- Persona Generation: LLMs are prompted to create detailed personality profiles, varying in age, occupation, health status, lifestyle, and habits. This step ensures behavioral diversity and supports the simulation of a broad spectrum of daily routines.
- High-Level Routine Generation: For each persona, the LLM generates a daily schedule, conditioned on the day of the week and the available rooms in the simulated environment. The routines are contextually grounded, with activities mapped to specific locations and time intervals.
- Low-Level Action Decomposition: Each high-level activity is decomposed into a sequence of atomic actions compatible with the VirtualHome simulator. The LLM is constrained to a predefined action-object schema, and outputs are post-processed to ensure strict adherence to the simulator's ontology.
This multi-stage approach enables the generation of plausible, context-aware activity sequences that reflect both inter- and intra-personal variability.
Virtual Sensor Data Generation in X-VirtualHome
The VirtualHome simulator is extended (X-VirtualHome) to support the simulation of privacy-preserving ambient sensors, including motion, door, and device activation sensors. The integration is as follows:
- Motion Sensors: Virtual motion sensors are programmatically placed in each room based on room size. The agent's 3D trajectory is tracked, and motion events are triggered when the agent enters a sensor's detection radius. The resulting ON/OFF events closely mimic real-world motion sensor behavior.
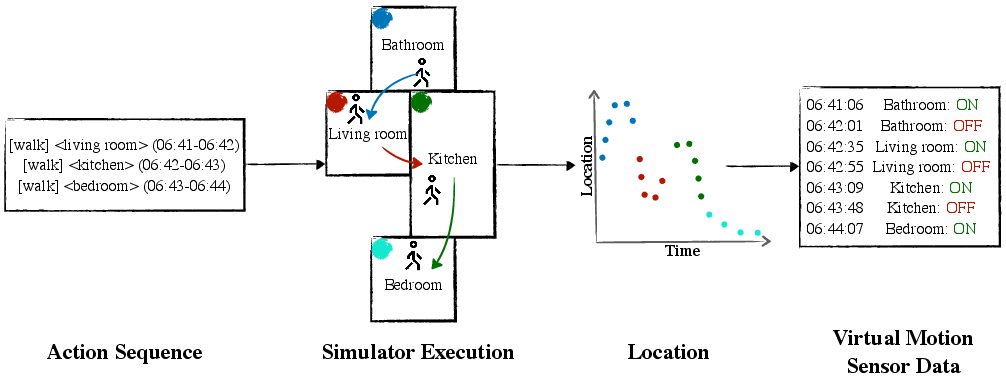
Figure 1: Virtual motion sensor data generation via LLM-driven action execution in X-VirtualHome, with synthetic sensors placed in each room and event metadata recorded for modeling.
- Door and Device Sensors: The simulator's environment graph is monitored for state transitions (e.g., door open/close, appliance on/off). These transitions are logged as virtual sensor events, providing fine-grained, time-stamped data streams.
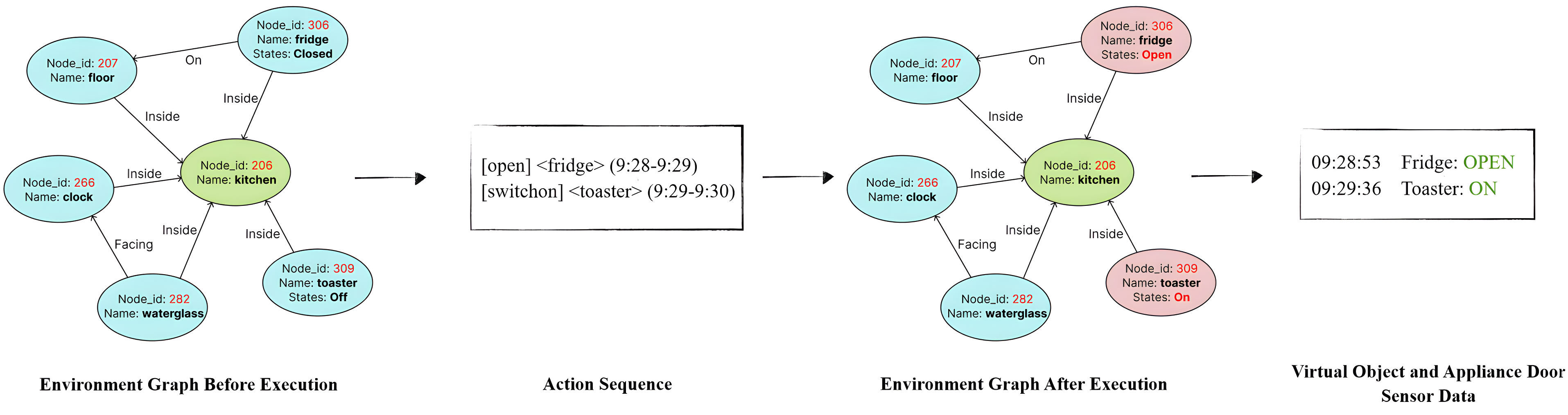
Figure 2: Object and appliance door sensor data generation in X-VirtualHome, with state changes (red nodes) captured as sensor events after LLM-generated action sequences.
- Sensor Data Output: Each simulation run produces a multi-modal dataset comprising time-stamped sensor events, agent trajectories, and full action logs, all annotated with ground-truth activity labels derived via LLM-based mapping to real-world HAR taxonomies.
Data-Driven Evaluation and Empirical Results
AgentSense is evaluated on five benchmark smart home datasets (CASAS Aruba, Milan, Kyoto7, Cairo, and Orange4Home), each with distinct sensor modalities, layouts, and activity sets. The core experimental protocol involves:
- Pretraining: HAR models are first pretrained on the virtual sensor data generated by AgentSense.
- Finetuning: Models are then finetuned on varying amounts of real-world data.
- Evaluation: Performance is measured on held-out real data using accuracy, macro F1, and weighted F1 metrics.
Key findings include:
- Consistent Performance Gains: Across all datasets, models pretrained on virtual data and finetuned with limited real data outperform those trained solely on real data. For example, on the Cairo dataset, accuracy improves from 69.01% (real-only) to 75.61% (virtual+real), and macro F1 increases by over 11 percentage points.
- Data Efficiency: With as little as 5–10% of real data for finetuning, models achieve performance comparable to those trained on the full real dataset, demonstrating the strong transferability of virtual pretraining.
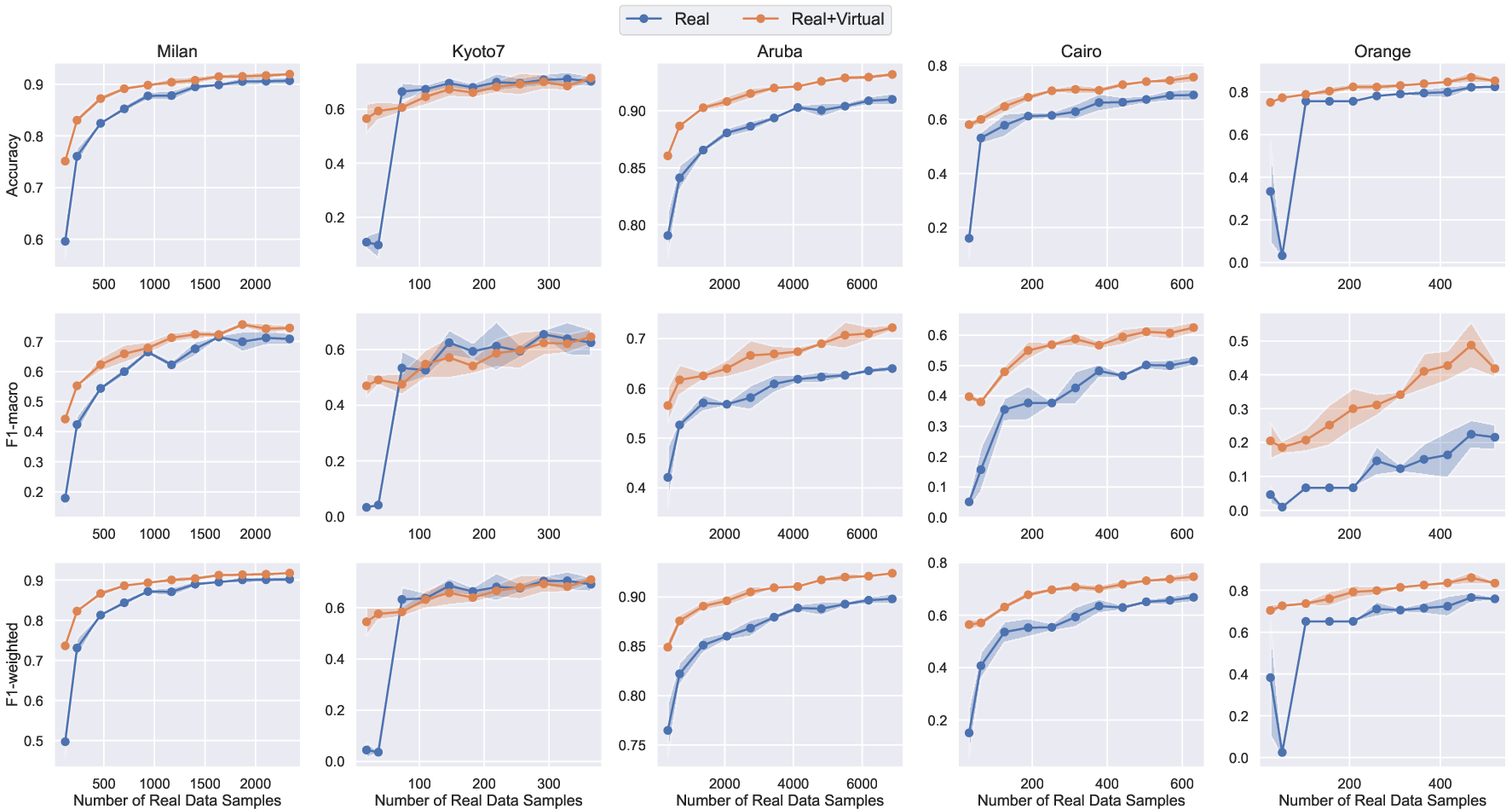
Figure 3: TDOST Basic model performance as a function of real data used for finetuning, with virtual data held constant. Substantial gains are observed in low-data regimes.
- Scalability of Virtual Data: Increasing the amount of virtual data used for pretraining yields monotonic improvements in downstream HAR performance for most datasets, with diminishing returns beyond a certain scale.
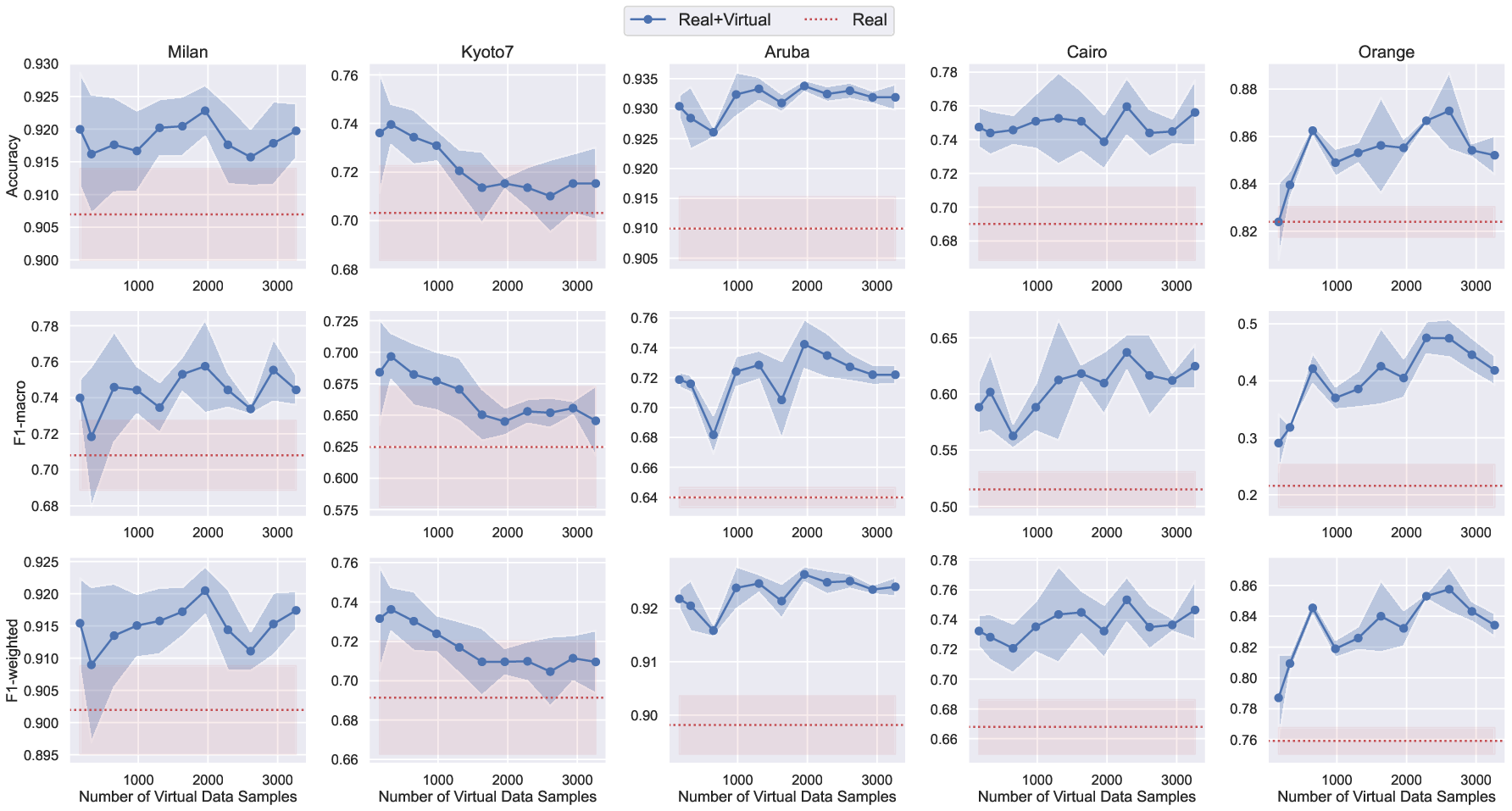
Figure 4: TDOST Basic model performance as a function of virtual data used for pretraining, with real data held constant. Performance saturates as virtual data increases.
- Domain Gap Robustness: Despite differences in layout and sensor configuration between virtual and real environments, the virtual data provides effective pretraining, indicating that the LLM-generated routines capture transferable behavioral structure.
Implementation Considerations
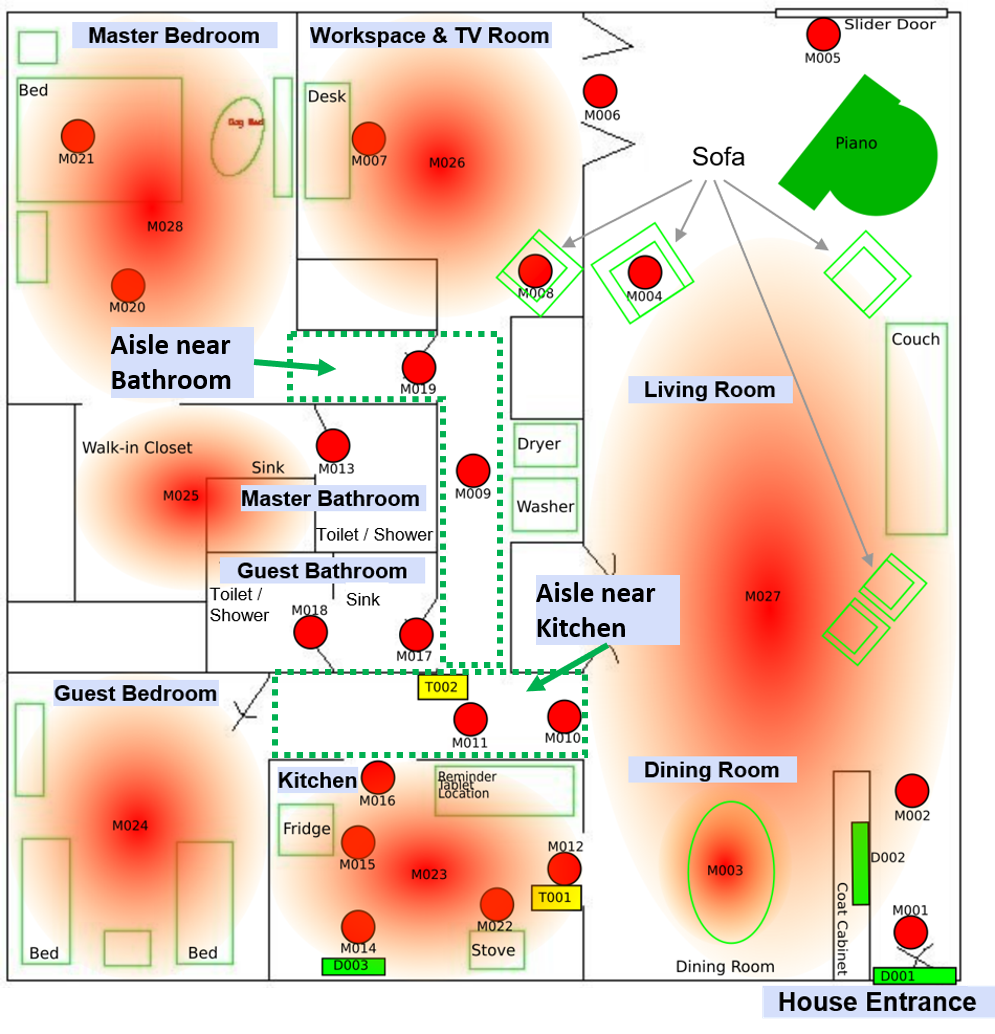
Figure 6: Example VirtualHome layout used for simulating diverse home environments.
Implications and Future Directions
AgentSense demonstrates that LLM-driven simulation pipelines can address the data scarcity and diversity challenges in smart home HAR. The approach enables:
- Rapid Bootstrapping: HAR models can be pretrained and deployed in new homes without requiring a cold-start data collection phase. 3D scans or floorplans can be used to instantiate personalized virtual environments for targeted data generation.
- Sensor Placement Optimization: Virtual experimentation with sensor layouts can inform cost-effective deployment strategies, maximizing recognition accuracy for target activities.
- Multi-Modal Data Synthesis: The framework can be extended to generate synchronized visual, pose, and wearable sensor data, supporting research on multi-modal HAR and cross-modality transfer.
- Generalization and Personalization: By simulating diverse personas and routines, models can be trained to generalize across populations and adapt to individual user behaviors.
Theoretical implications include the validation of LLMs as generative models for structured, context-rich human behavior, and the demonstration that simulation-based pretraining can bridge domain gaps in sensor-based HAR.
Conclusion
AgentSense provides a scalable, flexible, and empirically validated framework for generating richly annotated virtual sensor datasets using LLM agents in simulated home environments. The approach yields substantial improvements in HAR performance, particularly in low-resource settings, and offers a practical pathway toward generalizable, data-efficient, and adaptable smart home activity recognition systems. Future work should explore integration with additional modalities, domain adaptation techniques, and formal evaluation of LLM-generated routines against real-world behavioral data.