Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Abstract: Multimodal LLMs (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items summarize what remains missing, uncertain, or unexplored in the paper, with concrete directions for future research and validation.
- Clinical validation: No prospective or retrospective clinician-in-the-loop studies, reader studies, or outcome-based evaluations demonstrating utility, safety, or impact in real clinical workflows.
- Hallucination measurement: Absence of standardized hallucination/factuality metrics (e.g., RadGraph F1, CheXpert labeler consistency, clinical entity/relationship correctness) and radiologist adjudication for both VQA and report generation.
- Uncertainty and calibration: No mechanisms or evaluations of confidence calibration, selective abstention, or deferral-to-human policies—critical for high-stakes medical use.
- Robustness to acquisition variability: Unassessed robustness across institutions, devices, vendors, imaging protocols, windowing/normalization for CT, and common artifacts (motion, noise, occlusions, compressed/low-resolution scans).
- 3D volumetric and temporal reasoning: The pipeline reduces 3D volumes to 2D slices; no evaluation on volumetric tasks (lesion volumetry, sequence-level reasoning), longitudinal comparisons with priors, or progression tracking.
- Real-world OCR representativeness: Synthetic OCR tasks based on school exam images may not reflect clinical OCR challenges (DICOM overlays, annotations, hand-written notes, scanned forms, non-Latin scripts, variable layouts).
- Safety alignment and guardrails: No explicit refusal policies, safety filters, or evaluation on avoiding harmful recommendations, especially in patient-facing dialogue or decision support contexts.
- Bias and fairness auditing: No analyses of performance across demographics (age, sex, skin tone), institutions, geographic regions, or modalities; no mitigation strategies or fairness reporting.
- Data provenance, consent, and licensing: Limited discussion on data governance (consent, licensing, jurisdictional compliance), especially for scraped dialogue datasets and synthesized data derived from proprietary models.
- Faithfulness of chain-of-thought: CoT traces are LLM-generated and “validated” by another LLM; no human/clinical verification of step-wise correctness, guideline adherence, or causal faithfulness.
- RLVR details and efficacy: The RL component is preliminary (∼65K samples) with missing details on reward design, verifiability scope (beyond multiple-choice), sample efficiency, and ablations against SFT-only baselines.
- Scaling RL to non-verifiable tasks: Open question on how to define verifiable rewards for free-form generation (e.g., radiology reports), multi-image reasoning, and complex differential diagnoses.
- Multilingual coverage: Aside from inclusion of LLaVA-Med-zh, there is no systematic evaluation across languages, code-switching, or cross-lingual medical terminology and abbreviations.
- Clinically meaningful report evaluation: Unclear whether report generation was scored with clinically grounded metrics (finding-level correctness, impression accuracy, critical findings, actionable recommendations) or accepted by radiologist review.
- Beyond vision+text modalities: No integration or evaluation with waveforms (ECG/EEG), genomics, lab panels, temporal vitals, or audio (auscultation), which are central to comprehensive clinical reasoning.
- Deployment constraints: No analysis of inference latency, memory/compute requirements, throughput, or on-premise feasibility (e.g., hospital hardware, privacy-preserving inference).
- Data leakage and dedup coverage: Deduplication focuses on exact duplicates (perceptual hashing with Hamming distance 0) and known benchmarks; no assessment of near-duplicates or semantic leakage across training and evaluation sets.
- Extent of expert involvement: “Doctor preference” elicitation is described, but the number, specialties, inter-rater agreement, and validation of synthesized captions against expert ground truth are not reported.
- Synthetic data dependency: Heavy reliance on GPT-4o/Gemini distillation and synthetic captions/VQA may propagate upstream biases or errors; no quantification of synthetic-vs-human data contributions or their differential impact.
- Statistical rigor of SOTA claims: Lacks confidence intervals, significance testing, or consistent evaluation protocols across proprietary baselines; reproducibility of claims needs stronger methodological transparency.
- EHR/PACS integration: No discussion on interfacing with DICOM metadata, PACS systems, EHR context, or how structured clinical information informs multimodal reasoning.
- High-resolution pathology (WSI) handling: No approach to gigapixel tile-based processing, slide-level aggregation, or evaluation on real whole-slide imaging tasks.
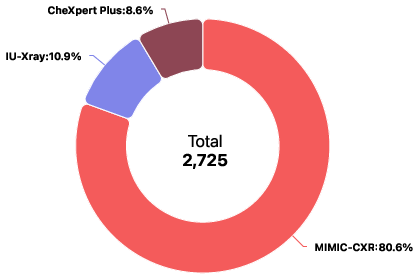
- Modality balancing and sampling strategy: Although modality distribution is shown, there is no analysis of sampling strategies, potential overfitting to dominant modalities, or performance trade-offs across long-tail modalities.
- Multi-turn clinical dialogue: Training includes single-turn dialogues; real-world clinical interactions are multi-turn and context-rich; evaluation on multi-turn consistency, memory, and safety is missing.
- Adversarial robustness and security: No testing against adversarial prompts, jailbreaks, or intentionally misleading medical inputs that could induce unsafe outputs.
- General-domain data mixing ablations: Insufficient analysis of how general-domain data affects medical task performance (catastrophic forgetting vs. transfer), and whether curriculum or domain-weighting improves outcomes.
- Pre-/post-processing standardization: No explicit handling of modality-specific preprocessing (e.g., HU windowing for CT, intensity normalization for MRI), which impacts performance and generalization.
- Continual learning and drift: No strategy for updating the model under distribution shift (new scanners, protocols) while preventing forgetting, or for continuous safety monitoring.
- Transparency and reproducibility: Limited release details on full training mixtures, cleaning scripts, synthesis prompts, RL reward code, and MedEvalKit evaluation configs to enable independent replication.
- Regulatory readiness: No pathway or plan for clinical certification (e.g., FDA/CE), risk management, post-market surveillance, or alignment with medical device regulations.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to measure their impact on model performance. "Through comprehensive ablation studies, we further confirm the importance of data quality and medical knowledge coverage on overall performance"
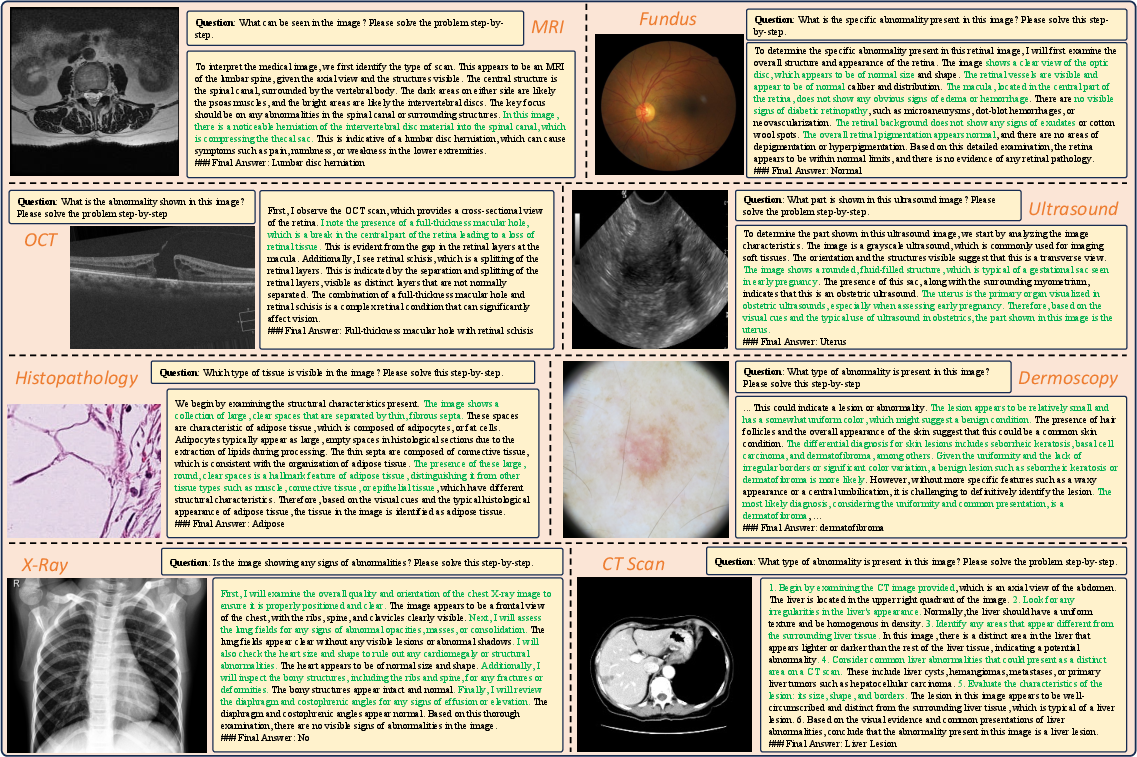
- Anatomical recognition: Identifying anatomical structures in medical images. "VQA samples for tasks such as diagnosis, anatomical recognition, and modality classification"
- Bounding boxes: Rectangular annotations that localize objects or regions in images. "Bounding boxes are directly overlaid on the original images"
- Chain-of-thought (CoT): Explicit step-by-step reasoning traces generated alongside answers. "chain-of-thoughts (CoTs) reasoning samples"
- Data contamination: Overlap between training and evaluation data that can inflate reported performance. "To prevent data contamination, we perform strict image and text deduplication"
- Dermoscopy: Imaging of skin lesions using a dermatoscope. "PAD-UFES-20~\citep{PACHECO2020106221} for Dermoscopy"
- End-to-end fine-tuning: Updating all model components jointly during training on task data. "are unfrozen to allow end-to-end fine-tuning"
- Fundus: Retinal imaging of the interior surface of the eye. "Fundus & BRESET~\citep{nakayama2023brazilian}"
- Hallucinations: Confident yet incorrect or fabricated model outputs. "heightened susceptibility to hallucinations due to suboptimal data curation processes"
- Histopathology: Microscopic examination of tissue to study disease. "and EBHI-Seg~\citep{shi2023ebhi} for Histopathology"
- Imaging modality: A type of medical imaging (e.g., X-ray, CT, MRI) with distinct acquisition characteristics. "over 12 medical imaging modalities"
- Min-hash locality-sensitive hashing (LSH): A technique for efficient near-duplicate detection via hash-based similarity. "using min-hash locality-sensitive hashing (LSH), retaining only the highest-quality version of each near-duplicate"
- Modality classifier: A model that predicts the imaging modality of an input image. "we train a modality classifier based on BiomedCLIP"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities such as text and images. "Multimodal LLMs (MLLMs) have demonstrated impressive capabilities"
- Optical Character Recognition (OCR): Automatically extracting text from images. "OCR-based instruction datasets enhance the model's ability to interpret textual information embedded within medical images"
- Perceptual hashing: Hashing that maps images to fingerprints reflecting visual similarity. "we apply perceptual hashing with a strict Hamming distance threshold of zero to detect and remove exact duplicate images"
- Radiology reports: Structured narratives describing imaging findings and clinical impressions. "radiology reports that detail clinical findings and impressions"
- Region of Interest (RoI): A specific area in an image relevant to analysis or diagnosis. "RoIs are available as either segmentation masks or bounding boxes"
- Segmentation masks: Pixel-level labels outlining regions or structures in images. "segmentation masks are converted into bounding boxes by computing the minimal enclosing rectangles"
- Self-instruct-based method: Generating training data by prompting models with seed examples to create new instructions or questions. "Self-instruct-based method"
- State-of-the-art (SOTA): The best reported performance to date on a task or benchmark. "state-of-the-art (SOTA) performance"
- Supervised Fine-Tuning (SFT): Training a model on labeled instruction data to improve capabilities. "supervised fine-tuning (SFT) on medical instruction data is effective in injecting medical knowledge into LLMs"
- Vision encoder: The component that converts images into feature representations for the LLM. "a vision encoder"
- Vision-language alignment: Training to map visual features and text into a shared semantic space. "for vision-language alignment and supervised fine-tuning"
- Visual Question Answering (VQA): Answering questions about images, requiring visual understanding and reasoning. "visual question answering (VQA)"
- Whole Slide Image (WSI): High-resolution digitized pathology slide. "A WSI image of carcinogenic DNA damage caused by ultraviolet (UV) radiation"
Collections
Sign up for free to add this paper to one or more collections.

