- The paper introduces AS-ASR, a targeted framework that reduces aphasic speech WER by over 30% through hybrid fine-tuning and GPT-4 transcript enhancement.
- It leverages Whisper-tiny-en for real-time edge deployment, balancing performance on both aphasic and fluent speech without heavy resource demands.
- The study underscores the importance of data composition trade-offs in optimizing ASR performance for clinical and wearable AIoT applications.
AS-ASR: A Lightweight Framework for Aphasia-Specific Automatic Speech Recognition
Introduction
The paper presents AS-ASR, a lightweight automatic speech recognition (ASR) framework specifically designed for aphasic speech, leveraging the Whisper-tiny model for deployment on resource-constrained edge devices. Aphasia, a language disorder resulting from neurological damage, introduces significant variability and disfluency in speech, posing substantial challenges for conventional ASR systems. Mainstream models, including Whisper, are predominantly trained on fluent speech and exhibit poor generalization to pathological speech, often yielding incomplete or misleading transcriptions. The AS-ASR framework addresses these limitations through targeted fine-tuning, hybrid data composition, and transcript enhancement, aiming to deliver robust, real-time ASR for clinical and wearable applications.
Model Selection and Edge Deployment Considerations
AS-ASR utilizes Whisper-tiny-en, the smallest variant in the Whisper family, comprising approximately 39M parameters and requiring only 1GB VRAM. This model is optimized for English tasks and achieves inference speeds an order of magnitude faster than Whisper-large, making it suitable for real-time operation on edge platforms such as Jetson Nano. Despite its compactness, Whisper-tiny-en demonstrates competitive performance when fine-tuned on aphasic speech, balancing recognition accuracy and resource efficiency.
Hybrid Data Fine-Tuning and Dataset Construction
The framework employs a hybrid training strategy, systematically varying the ratio of aphasic (AphasiaBank) and normal (TED-LIUM v2) speech data. This approach enables the model to learn both pathological and standard acoustic-linguistic patterns, enhancing generalization across diverse speech conditions. The aphasic corpus is curated from five sub-corpora within AphasiaBank, matched in size to TED-LIUM v2 to facilitate controlled cross-domain comparisons.
A key innovation is the use of GPT-4 for transcript enhancement. Raw aphasic transcripts, often noisy and fragmented, are refined using GPT-4 prompts that enforce fluency while preserving speaker intent. This process improves supervision quality during training, though it introduces a risk of over-correction, potentially masking diagnostically relevant features.
Experimental Setup and Baseline Comparisons
Data partitioning is consistent across mixing ratios, with 80% for training, 10% for validation, and 10% for testing. Fine-tuning is conducted on a high-performance GPU cluster using mixed-precision training and gradient checkpointing to optimize throughput and memory usage. The primary evaluation metric is Word Error Rate (WER), computed as:
WER=NS+D+I×100%
where S is substitutions, D deletions, I insertions, and N the total words in reference transcripts.
Baseline-1 assesses the zero-shot performance of Whisper-tiny-en on TED-LIUM, AphasiaBank, and a merged set. Baseline-2 compares WER across Whisper model sizes on aphasic speech, revealing that larger models do not consistently outperform smaller ones in this domain. Notably, Whisper-base-en yields higher WER than Whisper-tiny-en, underscoring the importance of domain-specific adaptation over model scale.
Fine-Tuning Results and Data Ratio Analysis
Fine-tuning Whisper-tiny-en on hybrid data yields substantial improvements in aphasic speech recognition, reducing WER by over 30% compared to the zero-shot baseline, while maintaining performance on standard speech. The model achieves WERs of 0.430 (dev) and 0.454 (test) on aphasic speech, versus 0.808 and 0.755 for the baseline. On clean TED-LIUM speech, WER remains stable at 0.116, indicating no degradation due to domain adaptation.
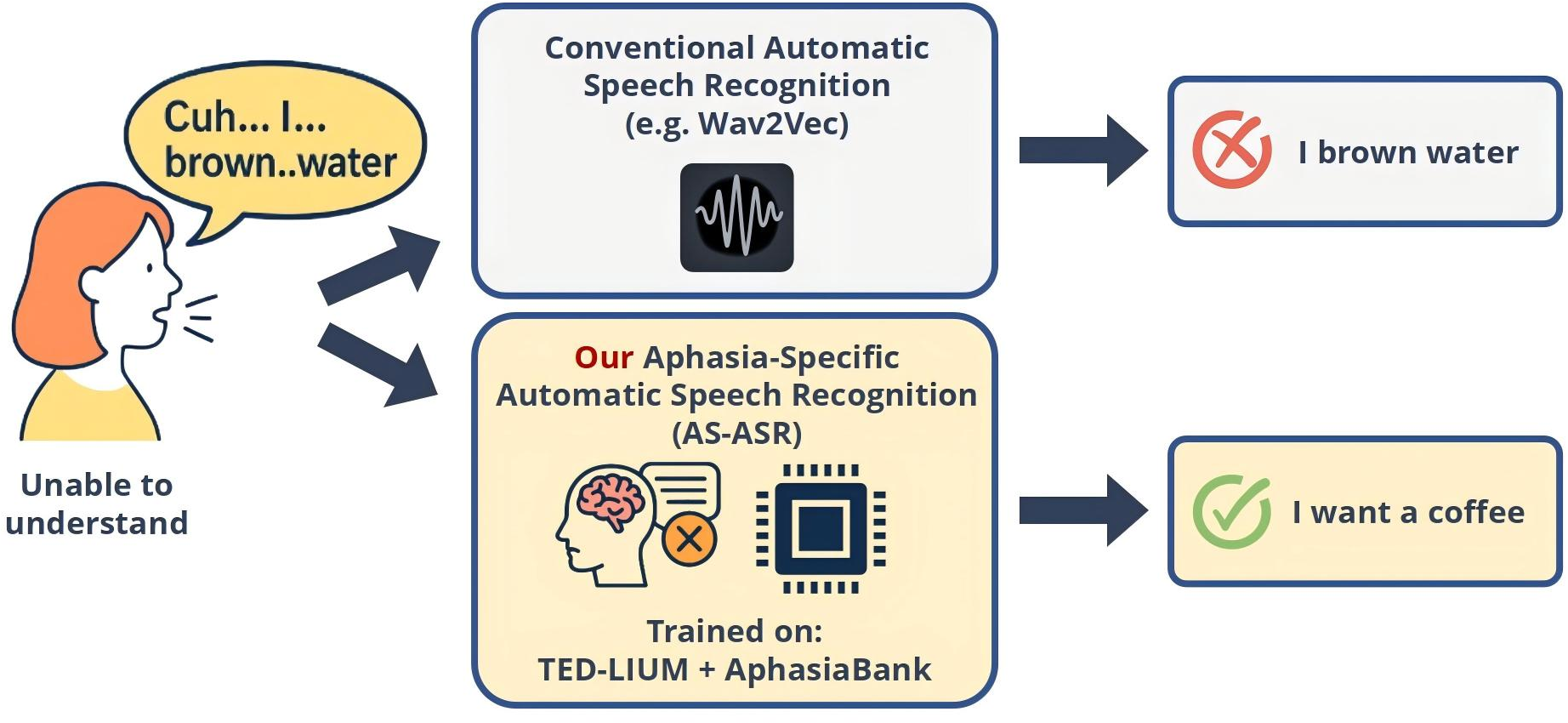
Figure 1: Comparison between conventional and aphasia-specific ASR systems on aphasia speech.
Systematic variation of aphasia-to-normal speech ratios reveals a trade-off: increasing aphasic data improves pathological speech recognition but degrades performance on fluent speech. Balanced configurations (e.g., 50:50 or 70:30) offer a practical compromise, supporting robust recognition across both domains.
(Figure 2)
Figure 2: Impact of Aphasia-to-TED-LIUM ratios on WER performance.
Practical and Theoretical Implications
AS-ASR demonstrates that lightweight ASR models, when fine-tuned with hybrid and enhanced data, can achieve clinically relevant performance on disordered speech while remaining deployable on edge devices. The use of LLMs for transcript enhancement introduces a new paradigm for improving supervision quality in pathological speech recognition, though further validation is needed to ensure clinical interpretability and avoid loss of diagnostic information.
The findings challenge the assumption that larger models inherently yield better results for disordered speech, highlighting the necessity of domain-specific adaptation and data composition strategies. The framework's scalability and efficiency position it as a viable solution for real-world clinical and wearable AIoT applications, where privacy, latency, and resource constraints are paramount.
Future Directions
Future work should incorporate clinician feedback to assess the utility of LLM-enhanced transcripts in clinical workflows. Hardware accelerator design, inspired by prior work on FPGA-based LSTM accelerators, could further reduce inference latency and power consumption, enabling broader adoption in wearable and edge healthcare devices. Expanding the framework to support multilingual and cross-pathology generalization remains an open research avenue, with implications for universal speech disorder recognition.
Conclusion
AS-ASR provides a robust, efficient solution for aphasia-specific speech recognition, leveraging targeted fine-tuning, hybrid data composition, and LLM-based transcript enhancement. The framework achieves significant gains in pathological speech recognition without sacrificing performance on fluent speech, and is optimized for deployment on edge devices. These contributions advance the state of ASR for disordered speech and lay the groundwork for future clinical and AIoT applications.

