Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
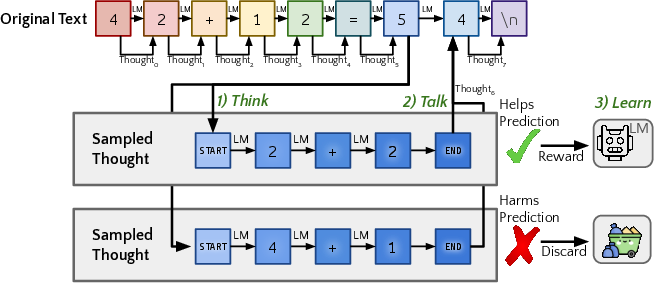
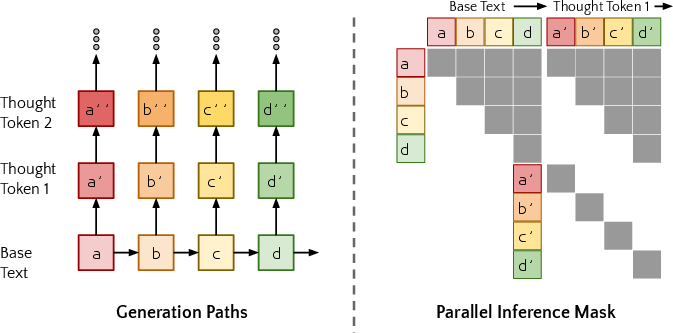
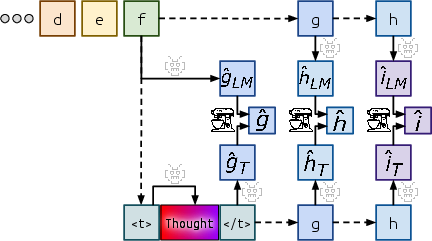
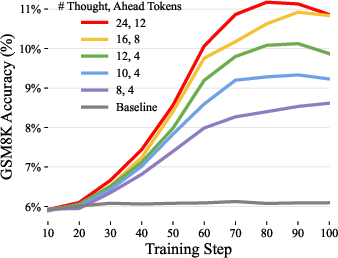
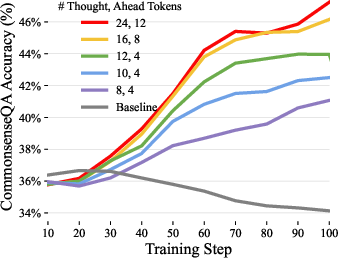
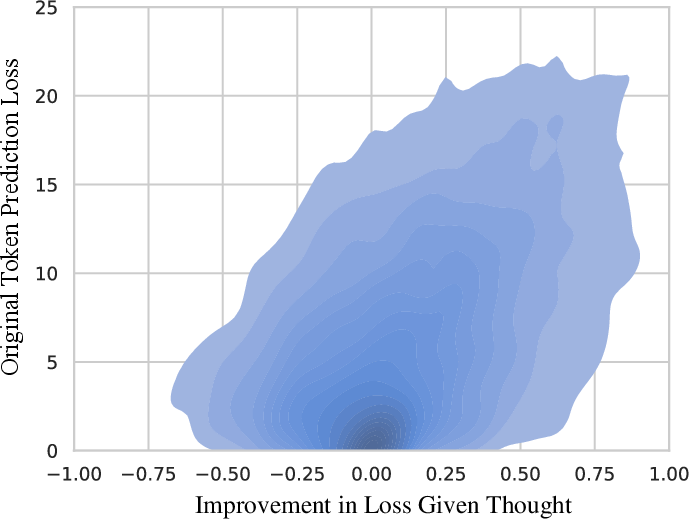
Abstract: When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text. For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer. This is a highly constrained setting -- ideally, a LLM could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain future text, improving their predictions. We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought's start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM's ability to directly answer difficult questions. In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%$\rightarrow$10.9%) and CommonsenseQA (36.3%$\rightarrow$47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way.
- Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017.
- Fireact: Toward language agent fine-tuning. arXiv preprint arXiv:2310.05915, 2023.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Training Verifiers to Solve Math Word Problems. arXiv, 2021. _eprint: 2110.14168.
- Strategic reasoning with language models. arXiv preprint arXiv:2305.19165, 2023.
- Are we modeling the task or the annotator? an investigation of annotator bias in natural language understanding datasets. arXiv preprint arXiv:1908.07898, 2019.
- Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023.
- Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
- Language models can teach themselves to program better. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=SaRj2ka1XZ3.
- Backpack language models. arXiv preprint arXiv:2305.16765, 2023.
- Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071, 2022.
- Training chain-of-thought via latent-variable inference. Advances in Neural Information Processing Systems, 36, 2024.
- V-star: Training verifiers for self-taught reasoners. arXiv preprint arXiv:2402.06457, 2024.
- Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301, 2023.
- Large language models can self-improve. arXiv preprint arXiv:2210.11610, 2022.
- Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Discrete prompt compression with reinforcement learning. arXiv preprint arXiv:2308.08758, 2023.
- Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp. arXiv preprint arXiv:2212.14024, 2022.
- Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023.
- Large Language Models are Zero-Shot Reasoners, 2022. URL https://arxiv.org/abs/2205.11916.
- Can language models learn from explanations in context? arXiv preprint arXiv:2204.02329, 2022.
- Learning to reason and memorize with self-notes. Advances in Neural Information Processing Systems, 36, 2024.
- The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
- Automated statistical model discovery with language models. arXiv preprint arXiv:2402.17879, 2024.
- Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726, 2022.
- Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- Compressing context to enhance inference efficiency of large language models. arXiv preprint arXiv:2310.06201, 2023.
- Crystal: Introspective reasoners reinforced with self-feedback. arXiv preprint arXiv:2310.04921, 2023.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Self-refine: Iterative refinement with self. Feedback, 2023.
- Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp. 1928–1937. PMLR, 2016.
- Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36, 2024.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- Feedback loops with language models drive in-context reward hacking. arXiv preprint arXiv:2402.06627, 2024.
- Openwebmath: An open dataset of high-quality mathematical web text. arXiv preprint arXiv:2310.06786, 2023.
- Training chain-of-thought via latent-variable inference. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Certified reasoning with language models. arXiv preprint arXiv:2306.04031, 2023.
- Generative Language Modeling for Automated Theorem Proving. CoRR, abs/2009.03393, 2020. URL https://arxiv.org/abs/2009.03393. _eprint: 2009.03393.
- Why think step by step? reasoning emerges from the locality of experience. Advances in Neural Information Processing Systems, 36, 2024.
- Autoact: Automatic agent learning from scratch via self-planning. arXiv preprint arXiv:2401.05268, 2024.
- Phenomenal yet puzzling: Testing inductive reasoning capabilities of language models with hypothesis refinement. arXiv preprint arXiv:2310.08559, 2023.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Explain yourself! leveraging language models for commonsense reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4932–4942, 2019.
- Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Programming Puzzles. In Thirty-fifth Conference on Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=fe_hCc4RBrg.
- Reflexion: Language agents with verbal reinforcement learning. arXiv preprint arXiv:2303.11366, 2023.
- Unsupervised commonsense question answering with self-talk. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4615–4629, 2020.
- Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv preprint arXiv:1712.01815, 2017.
- Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937, 2018.
- Function vectors in large language models. arXiv preprint arXiv:2310.15213, 2023.
- Solving math word problems with process-and outcome-based feedback. Neural Information Processing Systems (NeurIPS 2022) Workshop on MATH-AI, 2022.
- Hypothesis search: Inductive reasoning with language models. arXiv preprint arXiv:2309.05660, 2023.
- Chain-of-thought reasoning without prompting. arXiv preprint arXiv:2402.10200, 2024.
- Language modelling as a multi-task problem. arXiv preprint arXiv:2101.11287, 2021.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2021a.
- Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021b.
- Emergent Abilities of Large Language Models, October 2022a. URL http://arxiv.org/abs/2206.07682. arXiv:2206.07682 [cs].
- Chain of Thought Prompting Elicits Reasoning in Large Language Models, 2022b. URL https://arxiv.org/abs/2201.11903.
- Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- React: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR 2023), 2022.
- Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Parsel: Algorithmic reasoning with language models by composing decompositions, 2023a.
- Self-taught optimizer (stop): Recursively self-improving code generation. arXiv preprint arXiv:2310.02304, 2023b.
- Chain-of-thought reasoning is a policy improvement operator. arXiv preprint arXiv:2309.08589, 2023.
- In-context principle learning from mistakes. arXiv preprint arXiv:2402.05403, 2024.
- Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493, 2022.
- Hop, union, generate: Explainable multi-hop reasoning without rationale supervision. arXiv preprint arXiv:2305.14237, 2023.
- Teaching algorithmic reasoning via in-context learning. arXiv preprint arXiv:2211.09066, 2022.
- Large language models can learn rules. arXiv preprint arXiv:2310.07064, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.