- The paper introduces FOCUS, a dual-process framework that integrates fast intuition and deliberate analysis to enhance Visual Question Answering performance.
- It employs a novel self-consistency method to evaluate question complexity, reducing cognitive load and focusing on relevant visual inputs.
- Experimental results demonstrate up to 44% faster inference and improved accuracy, highlighting FOCUS's cost-efficient and scalable approach.
Enhancing Visual Question Answering through Dual Process Integration
Introduction
"Fast or Slow? Integrating Fast Intuition and Deliberate Thinking for Enhancing Visual Question Answering" proposes FOCUS, a novel methodology to overcome limitations in multimodal LLMs (MLLMs) used for Visual Question Answering (VQA). By drawing from Dual Process Theory, which differentiates between instinctive and deliberate cognitive modes, the paper addresses the inefficiencies in current approaches that indiscriminately annotate all detected objects, resulting in cognitive overload and computational inefficiency.
Methodology
FOCUS Framework
The FOCUS framework integrates two cognitive strategies: fast intuitive judgments (System 1) and deliberate analytical reasoning (System 2). The method starts by evaluating question complexity to dynamically adjust the approach:
- Question Complexity Evaluation: The complexity of each question is assessed, determining whether it requires fast intuitive responses or a more measured, deliberate approach. This is achieved through a novel self-consistency method with high temperature settings to gauge model confidence.
- Conceptualizing before Observation: For questions classified as complex, FOCUS uses a "conceptualizing before observation" strategy. This involves extracting key elements through LLMs and applying a segmentation model to focus on relevant visual inputs, effectively reducing unnecessary computational load.
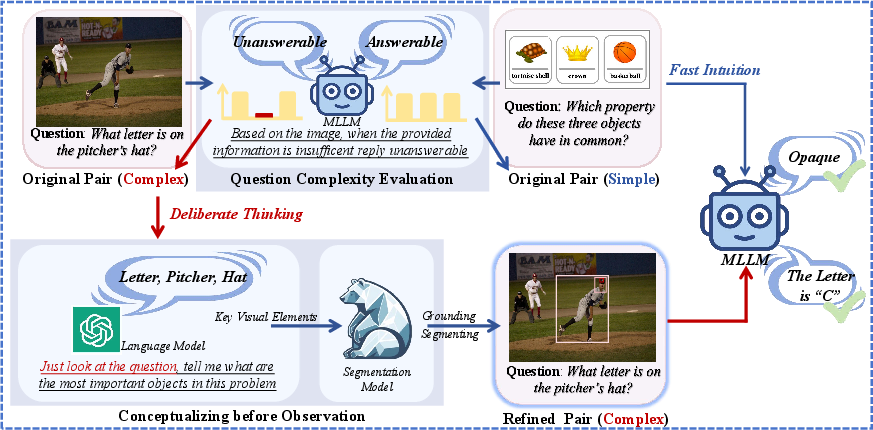
Figure 1: Overview of our model pipeline. (1) Question complexity evaluation for MLLM-based behavior to determine which questions require deliberate thinking. (2) Conceptualizing before observation, helping the model identify the most important visual information in the image.
Experimental Results and Analysis
The proposed method was evaluated using diverse MLLMs and datasets such as ScienceQA, TextVQA, VizWiz, and MME. The results demonstrated substantial improvements over prior methods, including SoM, highlighting both performance gains and reduced inference times.
Performance Metrics
Results showed that FOCUS consistently outperformed state-of-the-art techniques across multiple benchmarks, achieving notable improvements in accuracy and computational efficiency.
Ablation Studies
Ablation studies validated the merits of combining fast intuition with deliberate thinking. Uniform strategies applied across all questions were found to be suboptimal compared to FOCUS's adaptive strategy.
Visual Attention and Cost Analysis
Visual attention analysis indicated that FOCUS substantially enhances attention focusing on relevant image sections, as depicted in the attention visualization for LLaVA-1.5.
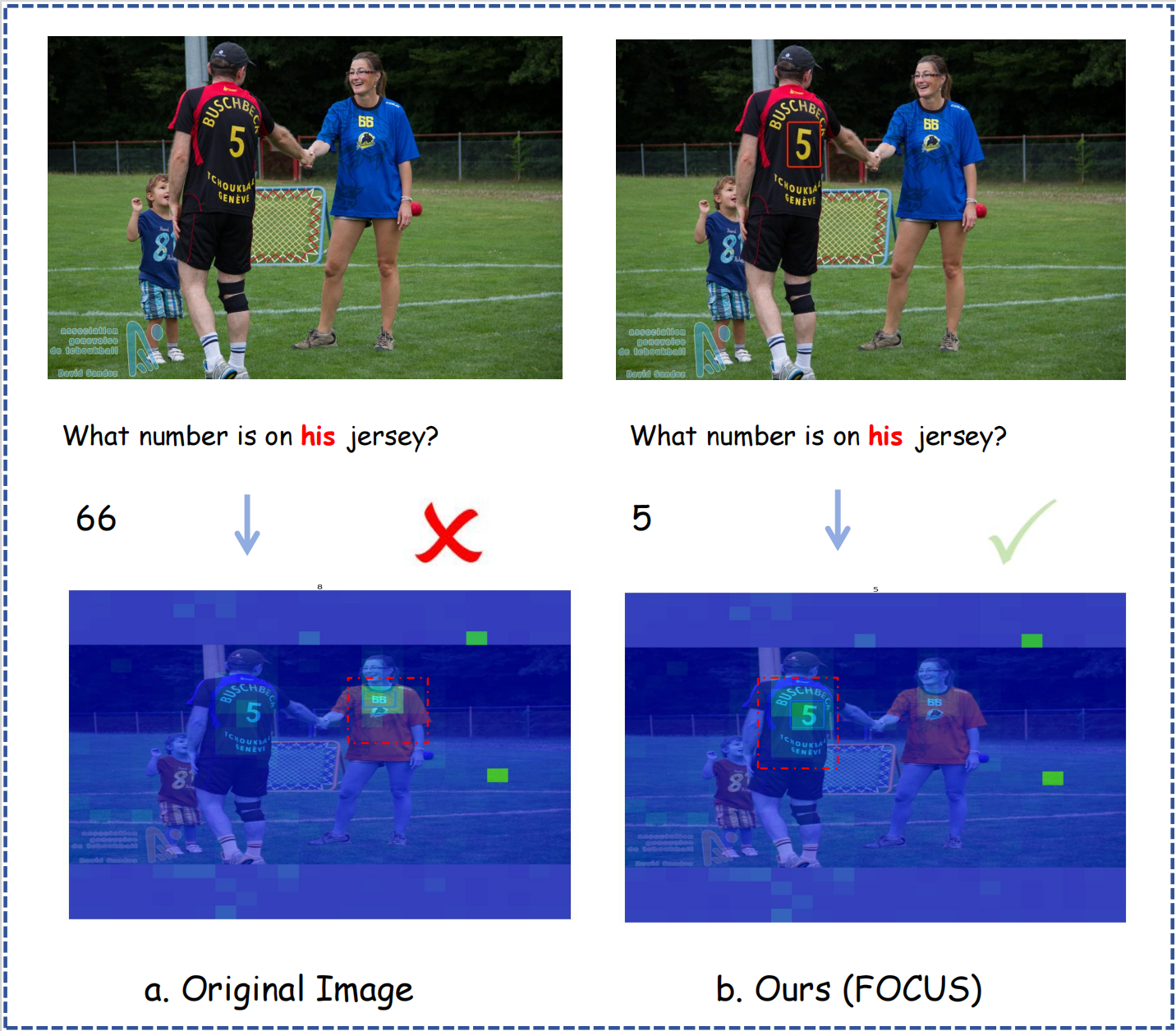
Figure 2: Visual attention visualization in LLaVA-1.5. The green areas indicate higher attention weights.
In terms of cost, FOCUS was shown to reduce inference times by approximately 44% compared to SoM, underscoring its cost-efficient advantages in real-world applications.
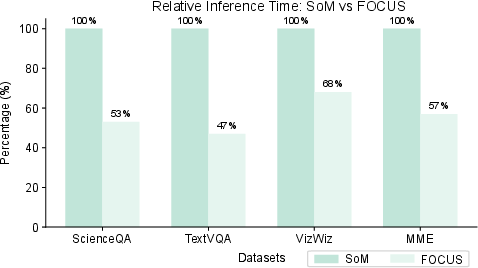
Figure 3: Relative inference time comparison
Limitations and Future Directions
While offering significant improvements, FOCUS relies on external tools for fine-grained visual inputs, which may introduce dependencies. Future research could explore tighter integration with model architecture and training processes to mitigate these limitations.
Conclusion
FOCUS presents a scalable solution that enhances MLLMs' reasoning capabilities in VQA by adaptively integrating dual cognitive strategies. This approach not only improves performance metrics but also offers a balanced trade-off between computational cost and accuracy, marking a notable advancement in the field of multimodal AI research.

