- The paper introduces an adaptive federated LoRA strategy that optimizes convergence time by coupling independent client sampling with dynamic bandwidth allocation.
- It formulates a non-convex optimization problem to determine optimal LoRA sketching ratios and sampling probabilities without requiring bounded gradients.
- Empirical results demonstrate significant reductions in training time and improved efficiency compared to state-of-the-art federated learning methods.
Adaptive Federated LoRA in Heterogeneous Wireless Networks with Independent Sampling
The paper "Adaptive Federated LoRA in Heterogeneous Wireless Networks with Independent Sampling" presents a novel federated learning strategy to efficiently fine-tune LLMs in environments characterized by heterogeneous client capabilities and non-uniform data distribution. The proposed approach seeks to optimize wall-clock convergence time by leveraging independent client sampling and adaptive resource allocation within wireless networks.
Problem Statement and Methodology
Challenges in Federated LoRA
Federated Low-Rank Adaptation (LoRA) is advantageous for distributed fine-tuning due to its reduction in trainable parameters, crucial for edge devices with limited resources. However, existing federated approaches often neglect system and data heterogeneity, leading to inefficient convergence and increased latency. This paper addresses these challenges by introducing independent client sampling coupled with adaptive bandwidth allocation.
Adaptive Client Sampling and Bandwidth Allocation
The paper proposes a federated LoRA strategy that does not require the bounded gradient assumption typical in convergence guarantees. It formulates a non-convex optimization problem to jointly determine LoRA sketching ratios (the proportion of low-rank updates each client contributes) and sampling probabilities. The strategy minimizes wall-clock convergence time through optimal distribution of system bandwidth according to client capabilities, ensuring that slower clients do not become bottlenecks.
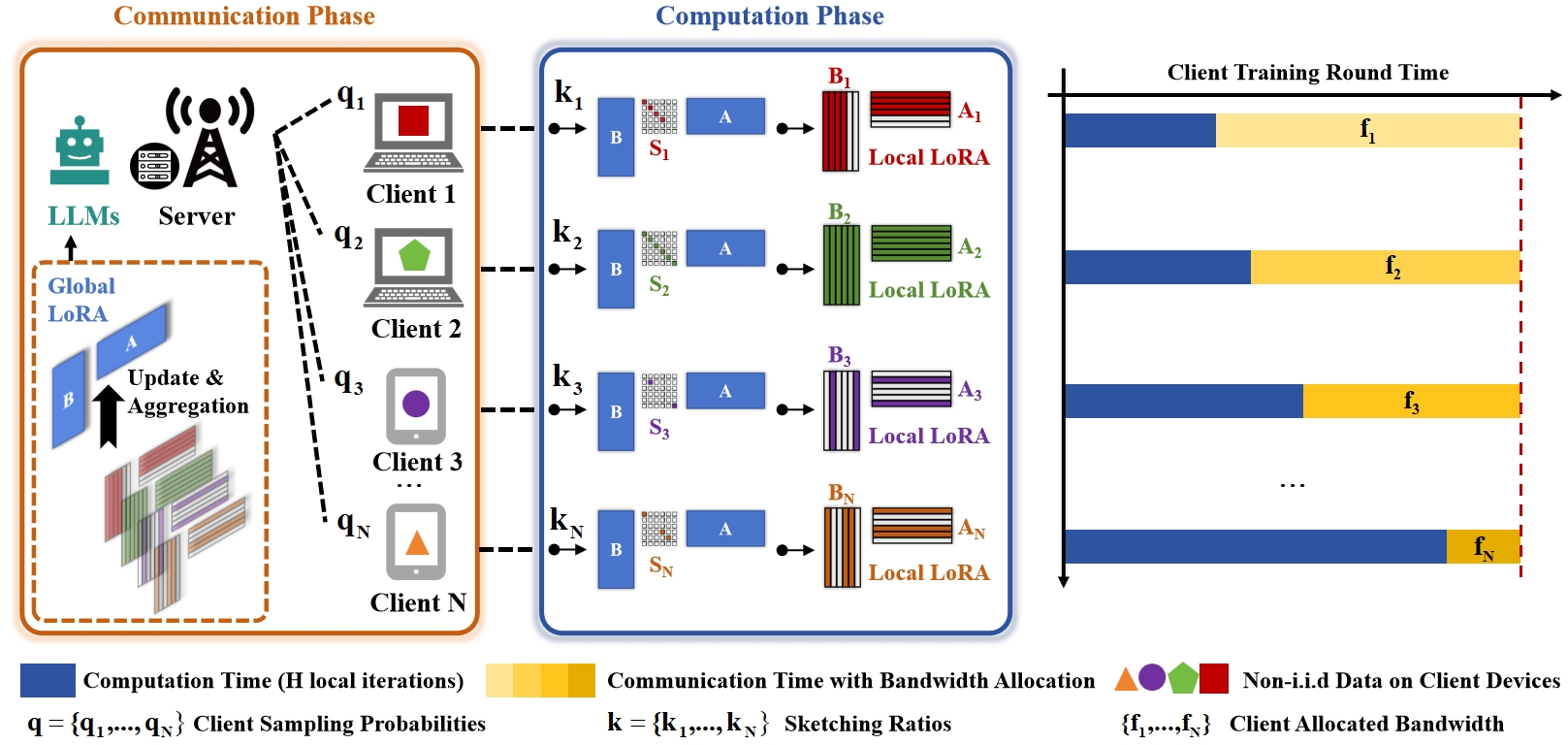
Figure 1: A heterogeneous federated LoRA over wireless networks, where clients possess varying levels of computation, communication capacities, and data distribution.
Algorithm Deployment
An efficient algorithm approximates the solution to the optimization problem, iteratively adjusting client participation frequencies and the proportion of updates each client should focus on. The sketching mechanism introduced allows lower computational overhead by sampling only key update indices, enabling faster iterations especially in resource-constricted environments.
Convergence and Optimization
Convergence Bound
Theoretical convergence analysis is provided, asserting that the proposed federated scheme maintains unbiasedness in global model updates despite stochastic participation. The analysis imposing conditions on client sampling ratios and computational resources underscores the balance between convergence speed and system strain.
Optimization of q and k
The optimization considers trade-offs between convergence rate and per-round latency. Empirical results show significant improvements by dynamically allocating bandwidth to optimize computation-communication efficiency, thus minimizing the wall-clock time.
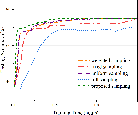
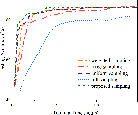
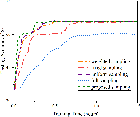
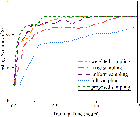
Figure 2: Performance analysis of the optimization of q, showcasing reduced training times compared to existing federated learning strategies.
Experimental Evaluation
Experiments demonstrate substantial reduction in training time across multiple datasets and applications compared to existing methods. The model achieves near-optimal trade-offs between client participation frequency and parameter updates proportional to data availability and client bandwidth capacity.
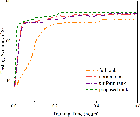
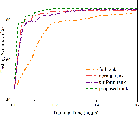
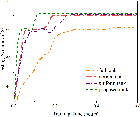
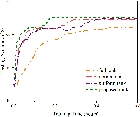
Figure 3: Performance analysis of the optimization of k, evidencing lower computational requirements and faster convergence.
Comparison with State-of-the-Art Methods
Time metrics indicate superior fine-tuning efficiency, where the proposed strategy drastically reduces latency compared to baselines such as HeteroLoRA and FedStackLoRA. The empirical results highlight the impact of adaptive strategies on preserving high accuracy while optimizing resource allocation.
Conclusion
The paper effectively addresses federated learning inefficiencies in heterogeneous wireless networks by proposing robust optimization strategies tailored to practical deployment scenarios. By strategically fine-tuning federated LoRA parameters considering both communication and computational constraints, the methodology facilitates efficient LLM training directly at the edge. Future work may further refine these strategies to accommodate evolving network dynamics and enhance the scalability of federated learning frameworks.