- The paper introduces a two-stage approach that integrates self-supervised learning with multiple instance learning to enhance CT image classification.
- The methodology employs PCRL pre-training and an attention mechanism to effectively address spurious correlations in image patches.
- The approach outperforms traditional baselines by significantly improving accuracy and F1 scores in challenging diagnostic tasks.
Multi-instance Learning as Downstream Task of Self-Supervised Learning-based Pre-trained Model
This study presents a novel approach to improving Multiple Instance Learning (MIL) in challenging contexts where the number of instances within a bag can complicate learning processes. By employing a self-supervised learning-based pre-trained model, the study aims to overcome difficulties in brain hematoma CT image classification, which is particularly encumbered by spurious correlations.
Introduction
Multiple Instance Learning (MIL) has traditionally been used in contexts like histopathology image analysis, where a single image is treated as a bag with instances representing patches of the image. Although deep learning has allowed MIL to scale to hundreds or thousands of instances per bag, challenges arise with excessively large numbers of instances, such as the 256 patches required for brain hematoma CT images. These difficulties are compounded by the so-called spurious correlation problem associated with classification tasks like hypodensity marker classification.
To address these challenges, this paper proposes a pipeline where MIL is the downstream task of self-supervised learning (SSL). In this two-stage approach, an SSL model is first trained to extract meaningful features from image patches, which are then used in the MIL context. The method showed improvements in classification metrics such as accuracy and F1 score, demonstrating its efficacy in mitigating the complications of handling large numbers of instances in MIL.
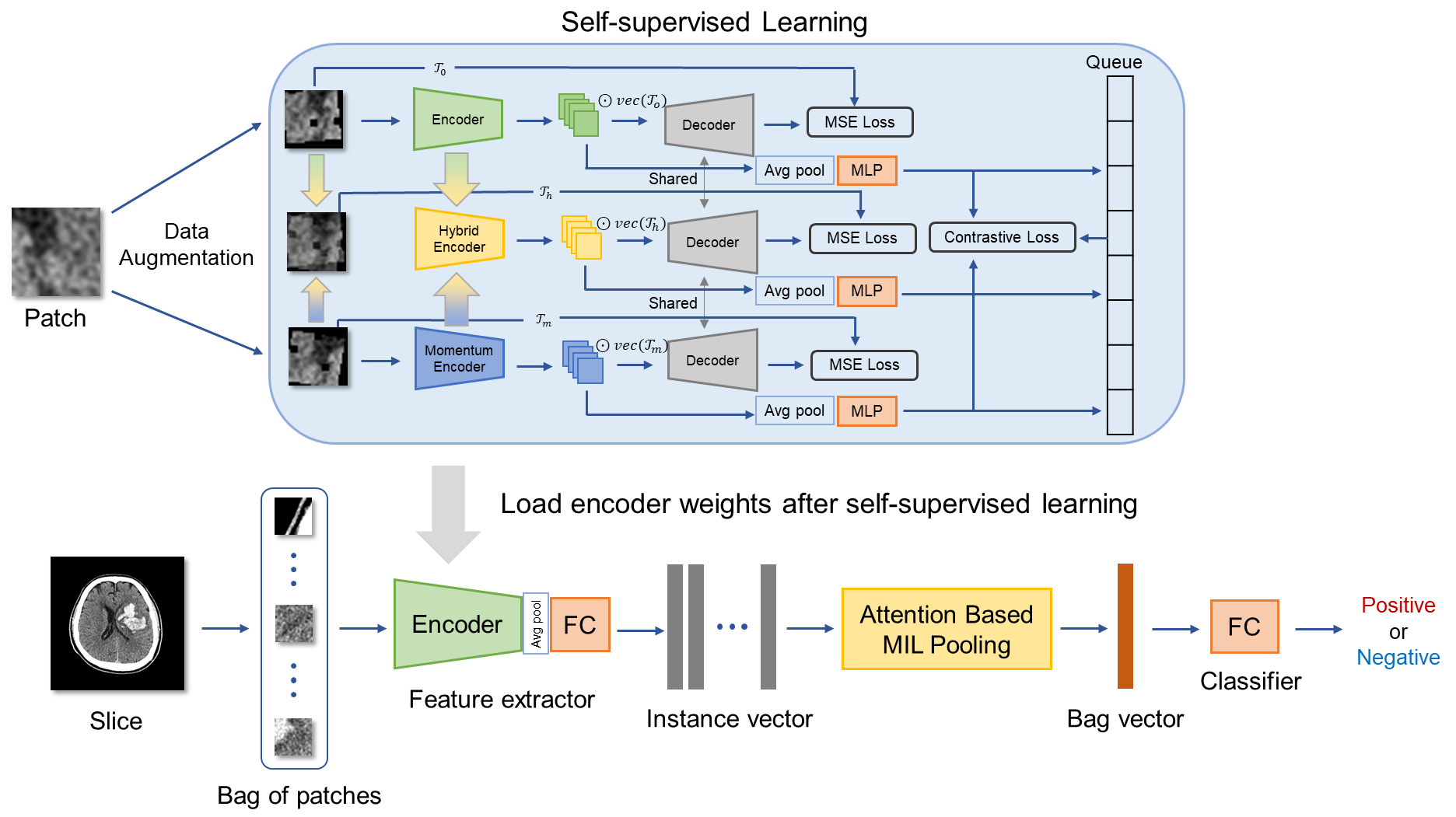
Figure 1: Overview of our method illustrating the two-stage process of self-supervised learning followed by deep multi-instance learning.
Methodology
The proposed methodology integrates self-supervised learning as a pre-training stage for MIL tasks. The process begins with dividing CT slices into 256 patch images, which are each treated as instances within a bag. The feature extractor in the MIL model is pre-trained using a combination of contrastive learning and reconstruction tasks, aiming to develop a robust internal representation of image features.
Self-supervised Learning Stage
The self-supervised learning stage adopts Preservational Contrastive Representation Learning (PCRL) to encode rich data representations. This involves applying various data augmentations to the image patches (Figure 2), enhancing the model's capacity to discern fine-grained textures that distinguish hematoma presence and severity. The model learns to prioritize features relevant to hematoma detection, addressing the spurious correlation problem more effectively.

Figure 2: Examples of data augmentation on patch images showing transformations like rotation and horizontal flipping.
Attention-based MIL
The downstream MIL model leverages an attention mechanism to pool instance features, with attention weights guiding the aggregation process. This attention-based pooling allows the model to focus on patches more critical for the classification task (Equations \ref{MIL_pooling1} and \ref{MIL_pooling2}). The pre-trained feature extractor aids in emphasizing diagnostically relevant patches within each CT slice.
Experiments
The experimental setup involves comparing the proposed method against a baseline and other models pre-trained in different contexts, such as ImageNet. Performance metrics, including accuracy, precision, recall, and F1 scores, were evaluated for both hematoma detection and hypodensity classification tasks.
Results Summary
The proposed self-supervised pre-training approach (conditions C and D) outperformed the baseline across all key metrics. Specifically, it showed notable improvements in tasks that involve large numbers of instances and spurious correlations. Transfer learning scenarios particularly benefited from pre-training, with substantial gains in precision and F1 scores for the challenging hypodensity classification task.
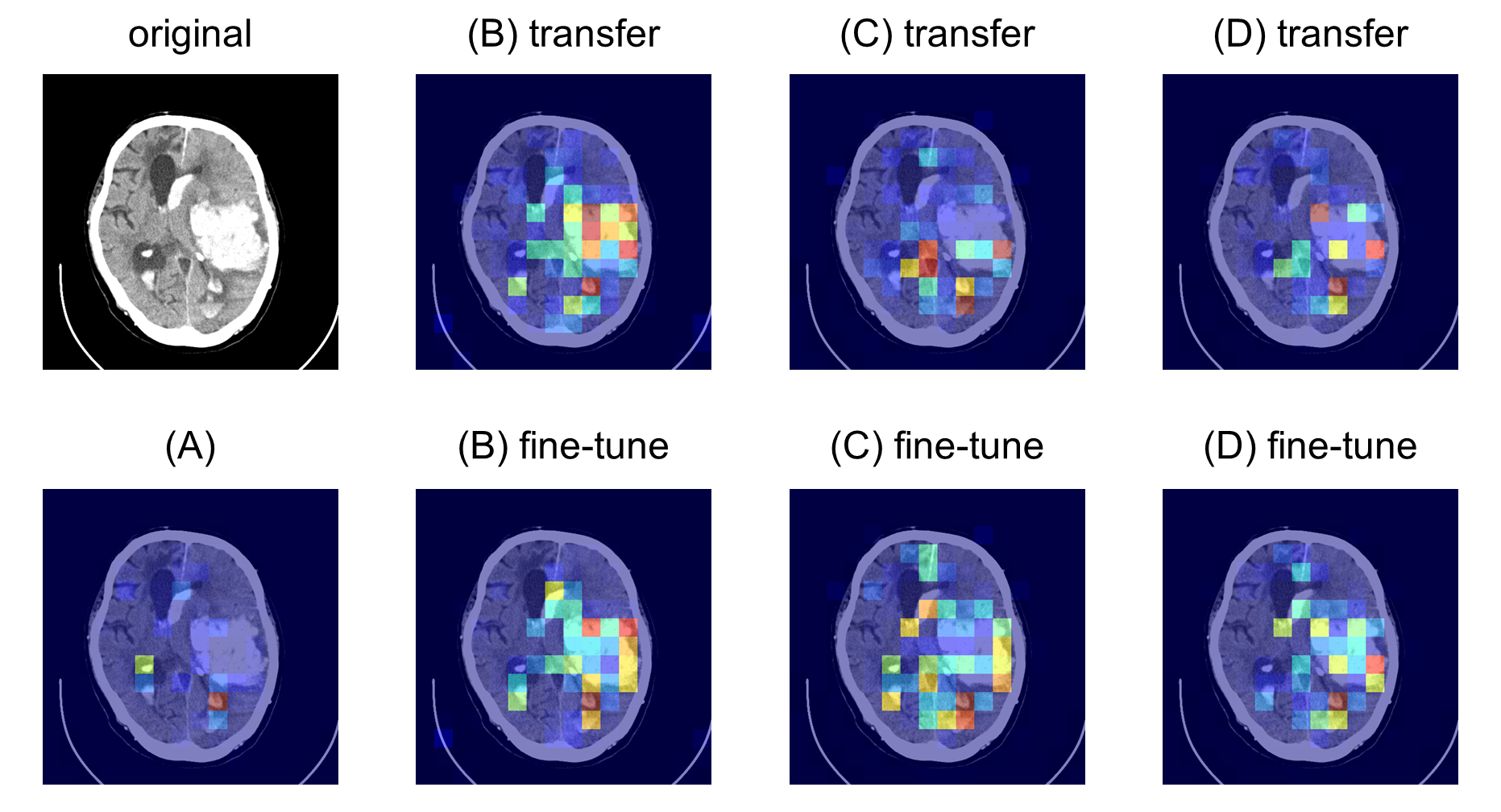
Figure 3: attention maps for hematoma detection showing how the model's focus improved over baseline.
Discussion
The application of self-supervised learning has demonstrated considerable advantages in addressing the inherent complexities of MIL, particularly when dealing with large instance counts per bag. The results suggest that this approach effectively harnesses the capacity to extract relevant features that enhance subsequent classification tasks.
The attention maps elucidate the model's improved ability to localize critical regions within CT slices, highlighting the added value of the SSL pre-training phase (Figures \ref{fig:attention_map_hematoma}, \ref{fig:attention_map_hypodensity1}, \ref{fig:attention_map_hypodensity2}). Future work could explore expanding the dataset used for pre-training and refining precision in medical image classification through further optimized augmentation strategies.
Conclusion
This study's innovative integration of self-supervised learning into the MIL framework substantially enhances classification performance in challenging medical imaging tasks. By demonstrating improvements in both major and fine-grained imaging benchmarks, this methodology paves the way for more robust multi-instance learning applications in medical diagnostics, warranting further exploration into broader use cases and datasets.
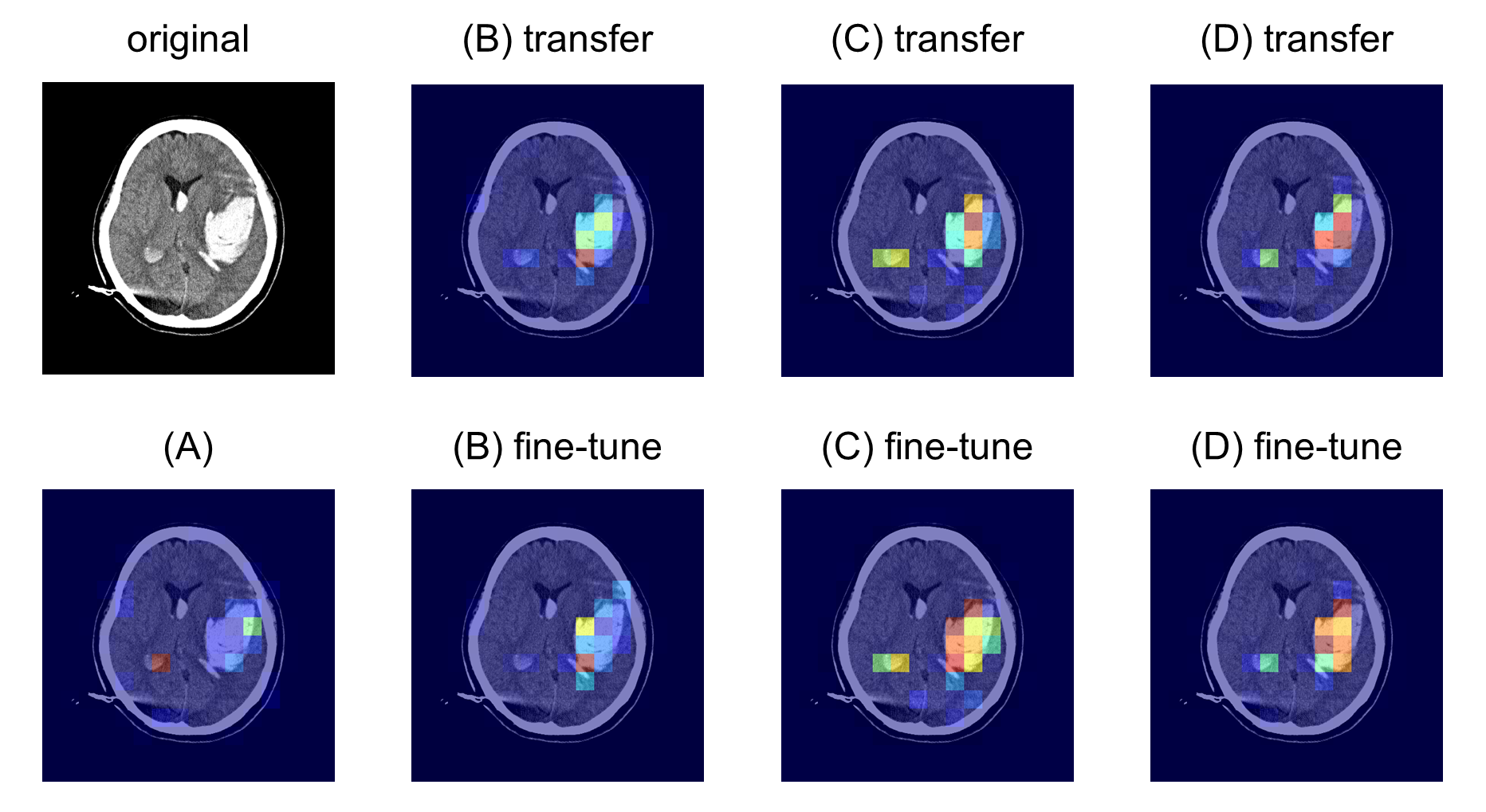
Figure 4: attention map for hypodensity (dataset 2-2) classification showing detailed instance focus within critical regions.