- The paper introduces continual learning strategies that address catastrophic forgetting in engineering regression tasks by applying surrogate models to complex simulations.
- It benchmarks methods including Experience Replay, EWC, and GEM across nine datasets, highlighting Replay’s balance of accuracy and runtime efficiency.
- The experimental analysis reveals engineering-specific challenges such as dynamic design criteria and input shifts, guiding future scalable, memory-efficient CL approaches.
Continual Learning Strategies for 3D Engineering Regression Problems: A Benchmarking Study
Introduction and Motivation
This paper systematically investigates the application of continual learning (CL) strategies to regression tasks in engineering, specifically focusing on surrogate modeling for computationally intensive simulations such as CFD and FEA. The motivation arises from the dynamic nature of engineering data pipelines, where new designs and constraints continuously emerge, rendering static retraining paradigms inefficient and impractical. Catastrophic forgetting—where models lose previously acquired knowledge when exposed to new data—is a critical challenge in this context. The study introduces CL to engineering regression, benchmarks established CL methods, and proposes regression-specific CL scenarios tailored to realistic engineering workflows.
Continual Learning in Engineering Regression
The paper identifies a gap in the CL literature: most prior work targets classification tasks, leaving regression—especially in engineering—underexplored. To address this, the authors propose three regression CL scenarios:
- Bin Incremental: Experiences are defined by binning the target variable, simulating incremental expansion of a model’s valid prediction range.
- Input Incremental: Experiences are defined by shifts in the input distribution, reflecting concept drift or changing operating conditions.
- Multi-target Incremental: Experiences correspond to the introduction of new output targets, relevant for evolving design criteria.

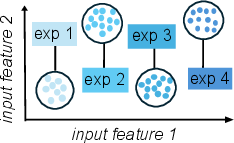

Figure 1: Bin Incremental scenario partitions the target space into bins, each forming a distinct experience for incremental learning.
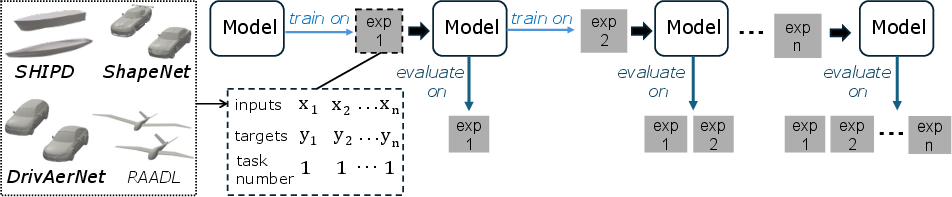
Figure 2: Continual learning model training scheme, with incremental training and evaluation on all experiences seen so far.

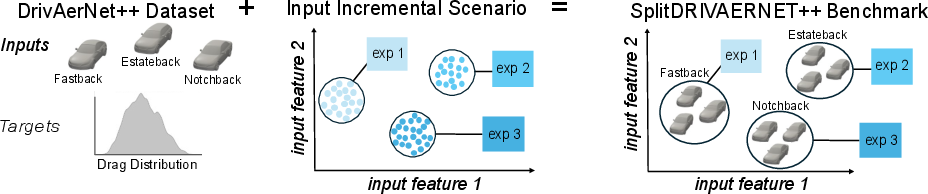
Figure 3: The SplitDRIVAERNET benchmark combines DrivAerNet data with bin incremental scenario, grouping car geometries by drag coefficient bins.
Benchmark Suite and Experimental Setup
The study assembles nine benchmarks from five engineering datasets (SHIPD, DrivAerNet, DrivAerNet++, ShapeNet Car, RAADL), covering naval, automotive, and aerospace domains. Datasets are represented as point clouds and parametric vectors, and surrogate models are implemented using regression PointNet and ResNet architectures. CL strategies evaluated include Experience Replay (ER), Elastic Weight Consolidation (EWC), and Gradient Episodic Memory (GEM), implemented via the Avalanche library. Experiments are constrained by compute resources and memory, with rehearsal strategies limited to 20% of the dataset.
Continual Learning Strategies
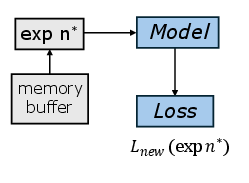
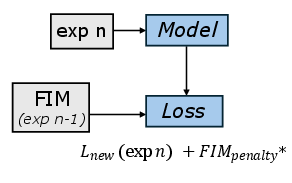
Figure 4: Experience Replay stores and replays samples from previous experiences to mitigate forgetting.
- Experience Replay (ER): Maintains a buffer of past samples, mixing them with new data during training. Offers strong performance and moderate memory cost.
- Elastic Weight Consolidation (EWC): Regularizes parameter updates using the Fisher Information Matrix, penalizing changes to weights important for previous tasks. Low memory, moderate compute overhead.
- Gradient Episodic Memory (GEM): Stores past data and constrains gradient updates to prevent interference, solving a quadratic program for each update. High memory and compute cost.
Evaluation Metrics
Performance is assessed using Mean Percent Error (MPE), Mean Absolute Error (MAE), forgetting ratio (normalized degradation in MAE on previous experiences), and total runtime. The study adapts forgetting metrics from classification to regression, providing a rigorous framework for evaluating CL in engineering.
Results
Bin Incremental Scenario
Replay consistently achieves the lowest MPE and forgetting ratio across all benchmarks, closely matching the performance of joint retraining while reducing runtime by up to 59%. GEM occasionally achieves lower forgetting on specific experiences but suffers from higher overall error and computational cost. EWC is computationally efficient but fails to mitigate forgetting, often matching the naive baseline.

Figure 5: Rank plots of CL strategies for Final MAE, Forgetting Ratio, and Total Run Time across all nine benchmarks.
Incremental MAE and forgetting plots reveal that Replay maintains stability and adaptability, while GEM prioritizes stability at the expense of plasticity, and EWC overfits to recent experiences.
For input distribution shifts, Replay again demonstrates superior resilience, with minimal forgetting and rapid recovery from distributional changes. GEM and EWC lag behind, with EWC particularly prone to catastrophic forgetting. The error spike at the second experience in DrivAerNet++ benchmarks suggests that the degree of input shift critically affects CL strategy performance.
Discussion
Statistical Analysis
Critical difference plots confirm that Replay and GEM are statistically indistinguishable in forgetting resistance, but Replay outperforms GEM in MAE and runtime. EWC and naive incremental training are statistically equivalent in forgetting and error, highlighting the limitations of regularization-based methods in engineering regression.
Stability-Plasticity Trade-off
GEM’s low forgetting on select benchmarks exemplifies the stability/plasticity dilemma: excessive stability impedes adaptation to new experiences. Replay achieves a better balance, leveraging data-driven rehearsal to maintain both stability and plasticity.
Engineering-Specific Challenges
Engineering regression tasks differ from classification CL in their continuous targets and shared structure across experiences, often enabling positive backward transfer. Data representation (point cloud vs. parametric) impacts strategy efficacy, with Replay showing robust performance across modalities.
Future Directions
The study identifies several avenues for future research:
- Memory efficiency: Quantifying and optimizing storage requirements for rehearsal-based methods.
- Forward transfer: Evaluating positive transfer to new tasks and rapid adaptation.
- Multi-target incremental learning: Investigating dynamic architectures for evolving output spaces.
- Scalable replay: Enhancing replay efficiency for large, high-dimensional datasets.
Conclusion
This work introduces continual learning to engineering regression, providing a comprehensive benchmarking suite and rigorous evaluation of CL strategies. Experience Replay emerges as the most effective method, balancing predictive accuracy, forgetting resistance, and computational efficiency. The study highlights the need for scalable, data-driven CL approaches tailored to the unique demands of engineering design, and sets the stage for future research in multi-target incremental learning and memory-efficient strategies.