- The paper identifies a significant explicit–implicit localization gap, with performance differences often exceeding 10% in culturally nuanced tasks.
- The paper introduces activation patching and steering vectors to pinpoint and guide cultural context within specific model layers.
- The paper demonstrates that a universal cultural vector can enhance cross-lingual transferability and improve culturally appropriate responses.
Localized Cultural Knowledge in LLMs
The paper "Localized Cultural Knowledge is Conserved and Controllable in LLMs" (2504.10191) thoroughly investigates the retention and activation of cultural nuances in multilingual LLMs. It distinguishes between explicit and implicit localization and explores mechanisms for bridging the explicit--implicit localization performance gap observed when LLMs are prompted without specific cultural context.
Explicit vs. Implicit Localization
LLMs, similar to bilingual speakers, tend to default to responses rooted in English-centric paradigms even when operating in other languages. This default behavior indicates an implicit bias stemming from models trained predominantly on English data. The paper introduces the explicit--implicit localization gap, characterized by the performance disparity when models tackle culturally nuanced tasks without explicit context. Providing cultural context in prompts improves localized responses, yet at the cost of increased response homogeneity and stereotyping, challenging the variety and depth of diversity we aim for in model outputs.
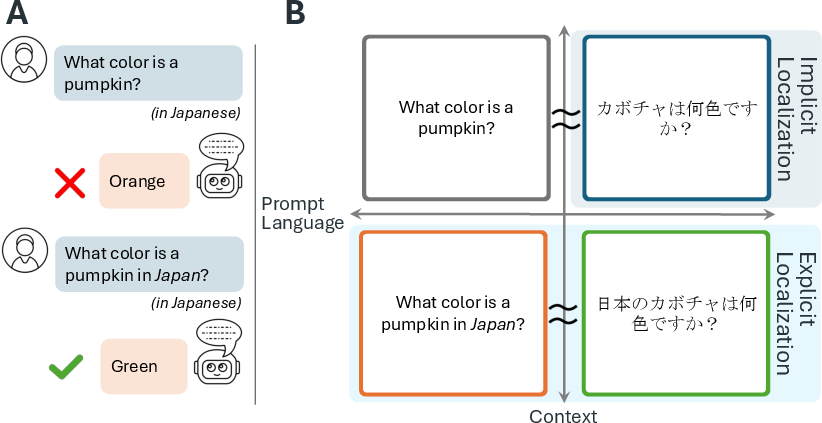
Figure 1: The explicit--implicit localization gap revealed through varied chat interaction settings.
Evaluation Methodology
The experimental framework devised by the researchers consists of a benchmark testing across diverse languages, namely English, Turkish, Russian, French, and Bengali. Different datasets encompass cultural identifiers like names, cities, tasks, and culturally distilled queries. Performance is measured through explicit and implicit setups, highlighting the localization gap.
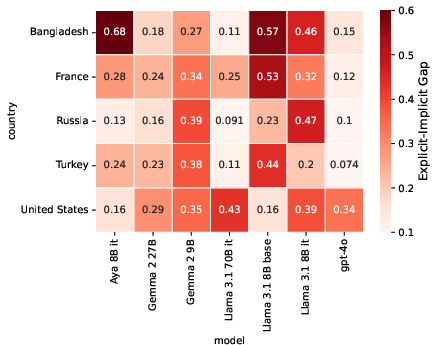
Figure 2: Heatmap showing the explicit--implicit localization gap across models and languages.
Key findings include:
- A significant localization gap, often exceeding 10% performance difference, which accentuates more in smaller models.
- Improved performance when a cultural reference prefix precedes the input query, indicating that even a single culturally relevant token can aid in steering the model's responses.
Mechanistic Interpretability
To understand where cultural nuances are encoded within models, the paper utilizes activation patching. This technique identifies layers within the model where cultural context starts influencing the output probabilities. Notably, layers 23 and 30 are crucial for consolidating a world model which becomes culturally targeted at these specific points.
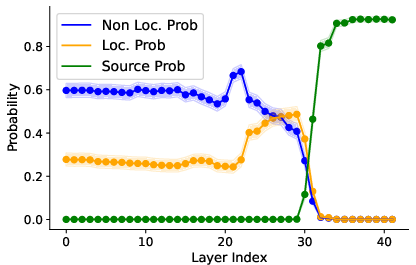
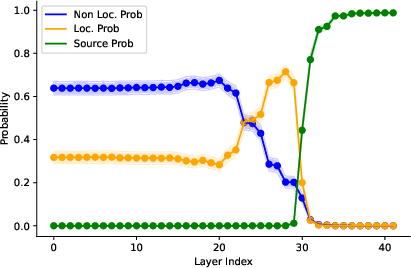
Figure 3: Activation patching results identifying where localized token probabilities peak.
Steering Localization with Activation Vectors
The research introduces steering vectors to address the explicit--implicit localization gap without explicit prompting. By calculating vectors that align model outputs with specific cultural contexts, it effectively guides the model to generate more culturally appropriate answers. These vectors demonstrate cross-linguistic transferability and task generalization capabilities.
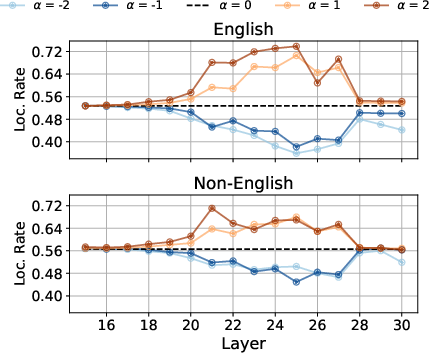
Figure 4: Steering results across several language layers showing improved localization performance.
Universal Cultural Vector
An intriguing component of their investigation is steering using a universal cultural vector. This aims to universally adapt outputs to align with the prompt language, suggesting that even complex cultural nuances can be generalized across languages within LLMs.
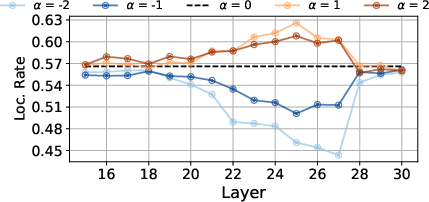
Figure 5: Application of universal steering vectors reveals cross-cultural adaptability improvements.
Implications and Future Work
The results have profound implications for deploying LLMs globally, indicating that while implicit training on language and cultural context provides baseline performance, explicit contextualization remains necessary for capturing depth in local culture. Future research avenues may explore parameter-efficient finetuning methods or enhancing universal steering setups to refine the cultural specificity in models further.
Conclusion
This investigation sheds light on pivotal components of cultural localization, advocating for a balanced, informed approach to leveraging both explicit and implicit mechanisms for context within multilingual applications. It serves as both a practical method for improving model deployment across cultures and a conceptual framework for understanding how LLMs navigate the rich landscape of global cultural knowledge.

