- The paper’s main contribution is the formal proof that attention output variance decays with increasing sequence length, leading to significant distribution shifts.
- It shows that applying layer normalization immediately after attention outputs effectively mitigates these shifts, stabilizing model performance on longer sequences.
- Empirical results on algorithmic tasks confirm that normalization interventions enhance out-of-distribution accuracy, even when training occurs on much shorter sequences.
Introduction
The paper "On Vanishing Variance in Transformer Length Generalization" (2504.02827) addresses a persistent limitation of Transformer architectures: robust generalization to sequence lengths longer than those encountered during training. Despite their centrality in deep learning across domains, Transformers often fail at length generalization, challenging the understanding of their underlying reasoning abilities. This work presents both theoretical and empirical foundations for the phenomenon of vanishing variance in attention outputs as sequence length increases and analyzes the efficacy of normalization strategies in mitigating associated distribution shift and generalization failure.
Vanishing Variance in Attention Outputs
The central theoretical contribution is a formal proof that, under reasonable assumptions (i.i.d. sequence elements and zero-mean value projections), for a fixed query and output dimension the variance across the attention outputs decays to zero as sequence length tends to infinity. This vanishing variance leads to a distribution shift for the attention outputs when Transformers are exposed to longer sequences at inference time—a scenario typical in algorithmic and language modeling settings.
Empirical experiments confirm that this decay is not merely a theoretical artifact but persists in frontier models such as Llama-3.2-1B, even when assumptions like strict independence are relaxed (e.g., in real text with positional encodings).
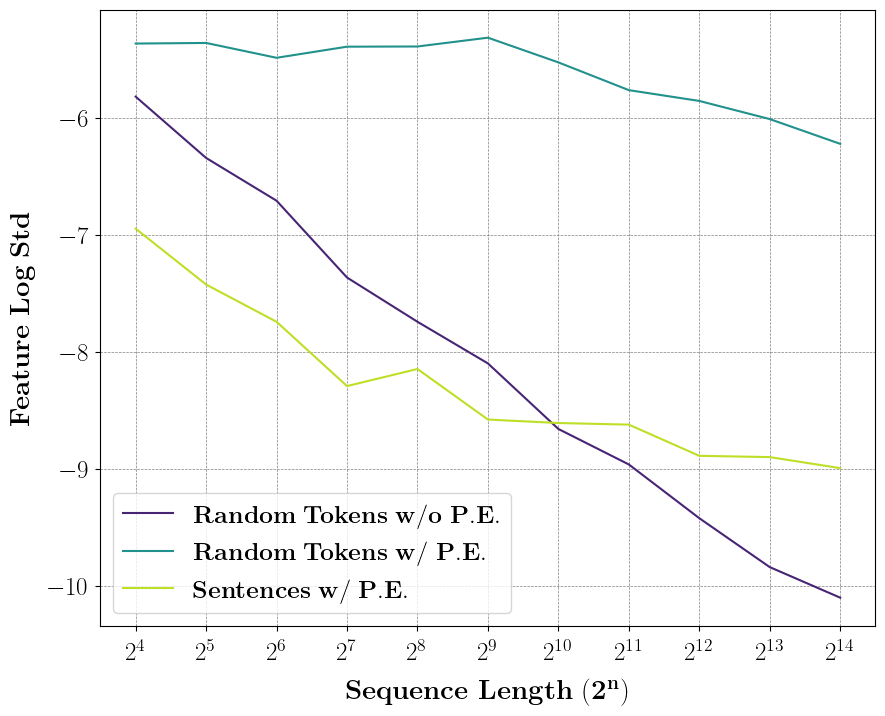
Figure 1: Standard deviation of a fixed component in attention outputs from the first layer of Llama-3.2-1B as a function of sequence length, illustrating σ∝N−0.5 scaling in the i.i.d. token regime and a clear downward trend with position encodings and real sentences.
By analyzing the variance of attention outputs for multiple synthetic data regimes (i.i.d. tokens, random tokens with and without positional encoding, and natural text), the study shows a consistent decrease in output variance, culminating in sharply reduced model accuracy on long sequences.
Distribution Shift and Layer Normalization
This vanishing variance translates concretely into a significant distribution shift in the activations fed into downstream MLP layers. For models trained on short sequences, attention output features become sharply concentrated around their mean as input length increases, reducing their informativeness and hampering the inductive bias needed for extrapolation.
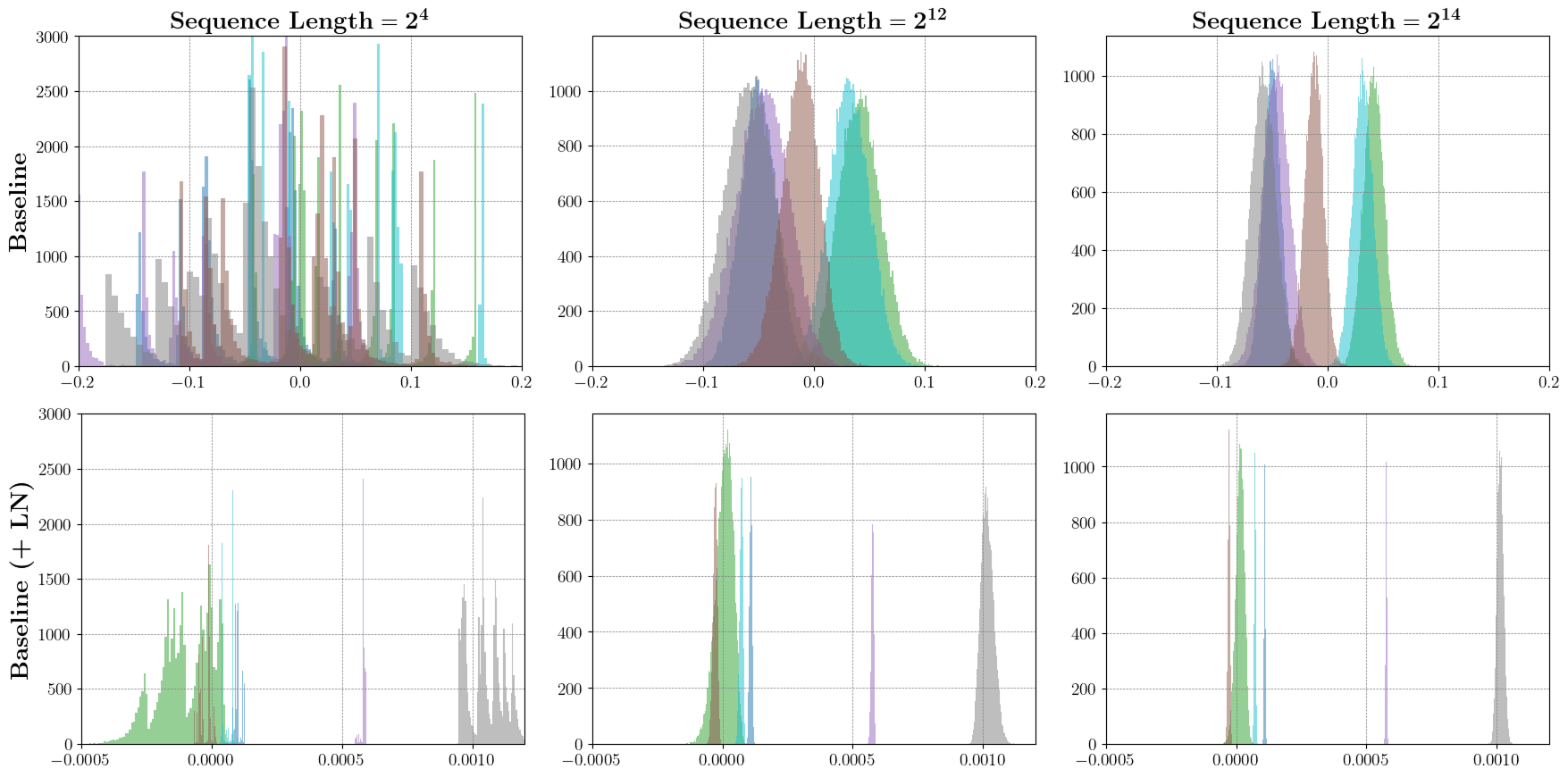
Figure 2: Histogram of five attention output feature components across batches, visualizing concentration and variance reduction as sequence length grows.
The global mean and global variance of the feature vectors also exhibit a pronounced drift and decay, respectively, as sequence length deviates from the model's training regime.
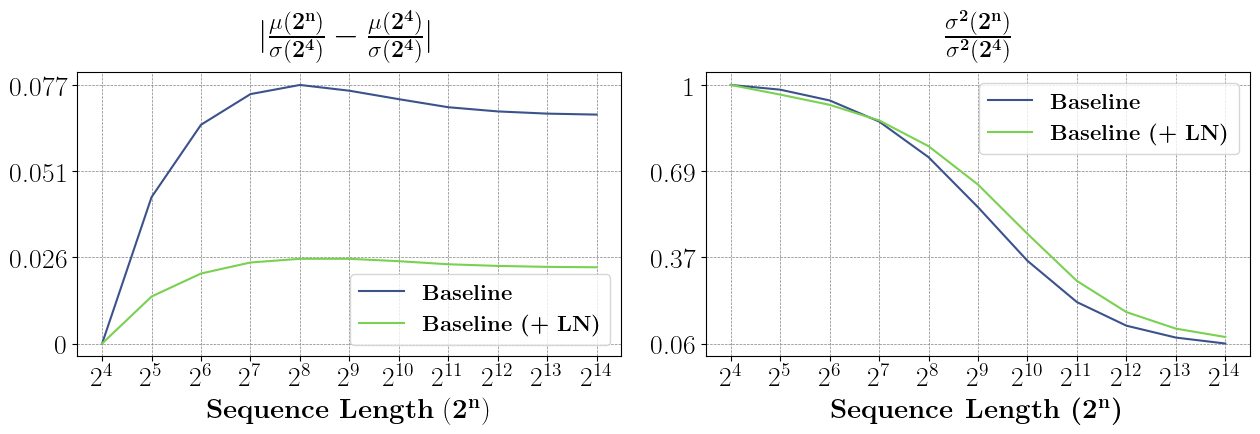
Figure 3: (Left) Drift in global mean normalized by training variance with increasing sequence length; (Right) decay in global variance, both showing the stabilizing effect of layer normalization.
The analysis demonstrates that standardization and, in particular, layer normalization applied immediately after the attention outputs stabilizes not only per-component statistics but the global distributional characteristics of the attention output vectors. This reduces the distribution shift, keeping the inputs fed to the MLP within the distribution experienced during training.
Experimental Validation and Ablation
On the argmax retrieval and dictionary lookup tasks—selected for their order invariance and algorithmic nature—layer normalization consistently improves out-of-distribution (OOD) generalization to sequence lengths up to 214, even when the in-distribution training length is only 24 or 28.
Furthermore, the gains from normalization are largely independent of test-time adaptation or architectural changes to the softmax function, highlighting the orthogonality and general utility of this intervention.
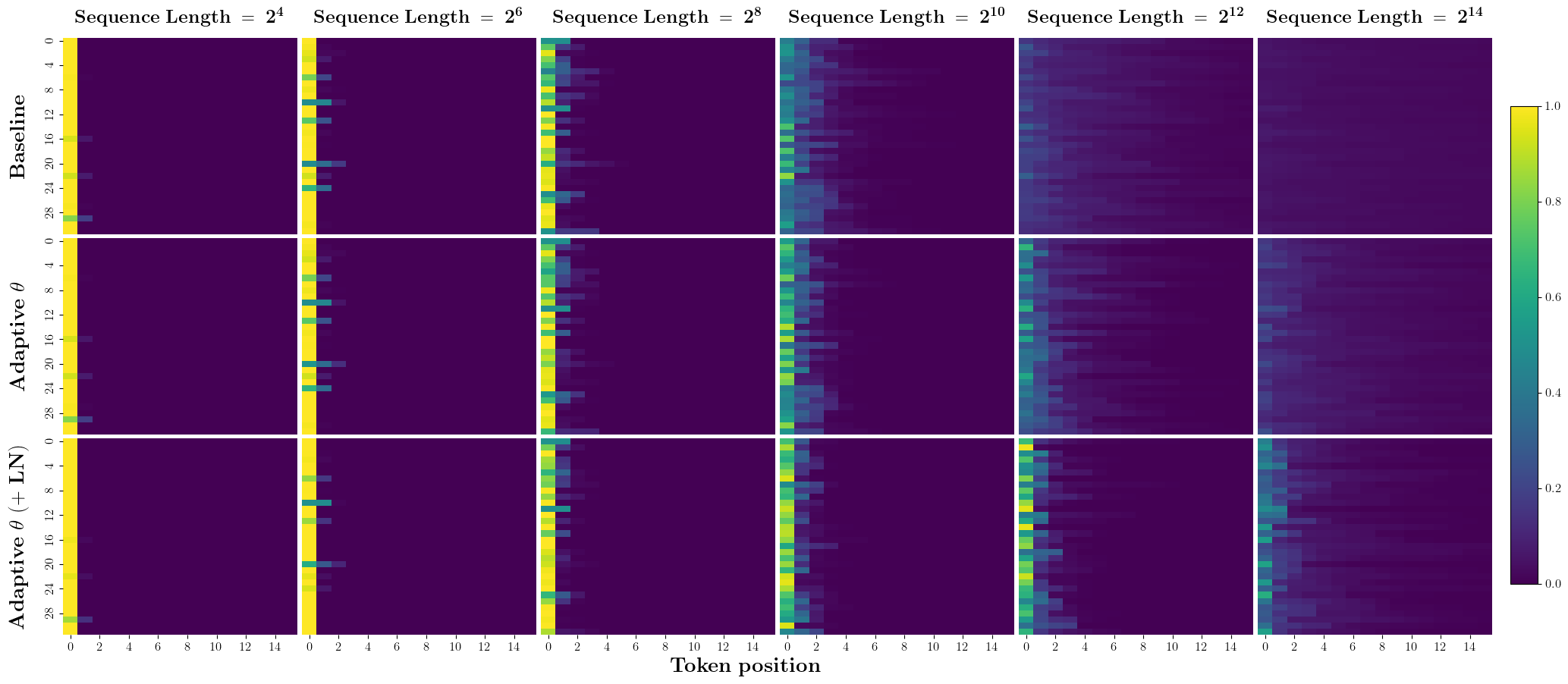
Figure 4: Heatmap showing that layer normalization mitigates attention weight dispersion as sequence length increases, addressing the issue outlined by prior work.
Ablation studies reveal that even non-learnable standardization confers meaningful improvements over the baseline, though layer normalization (with learnable scale and shift) consistently yields the best performance in both tasks, as measured by accuracy and supported by strong statistical evidence (significant p-values reported).
Implications and Future Directions
The findings clarify why even cutting-edge Transformers exhibit brittleness in length generalization despite sophisticated architectures and positional encodings. Norm-based interventions immediately after attention outputs, although not a panacea, address a core limitation associated with the distributional collapse of outputs as sequence length increases.
In practical terms, the results suggest revisiting normalization placement within existing and future model designs, especially for extrapolative use cases such as algorithmic reasoning, mathematical problem solving, or code synthesis. Theoretical implications span a deeper need to design architectures and derivations that are provably invariant—or at least robust—to input length.
Open research directions include extending the analysis to deeper Transformer stacks with multi-head attention, validating on realistic benchmarks such as CLRS, and developing new normalization or architectural mechanisms that fully eliminate vanishing variance or otherwise guarantee invariance to input length.
Conclusion
This paper rigorously identifies, theoretically analyzes, and empirically demonstrates the vanishing variance phenomenon in Transformer attention outputs as a root cause of poor sequence length generalization. Normalization applied directly after attention effectively mitigates—though does not eradicate—the associated distribution shift and improves OOD performance on algorithmic tasks, offering actionable insight for Transformer design and future research on robust extrapolation.

