- The paper presents ZSinvert, a zero-shot inversion method that leverages adversarial decoding to rapidly reconstruct text from embeddings without model-specific training.
- It employs a three-stage process—seed generation, paraphrase refinement, and offline correction—to optimize semantic similarity even in noisy conditions.
- Evaluation shows ZSinvert achieves an F1 score above 50 and cosine similarity over 90%, highlighting both its efficiency and potential security risks in embedding sharing.
Universal Zero-Shot Embedding Inversion
Introduction
The paper "Universal Zero-shot Embedding Inversion" (2504.00147) addresses the problem of reconstructing text from embeddings, a critical issue in both NLP and security. Traditional methods, like vec2text, require extensive training resources and are less effective under noisy conditions. The authors propose ZSinvert, a zero-shot inversion method that leverages adversarial decoding, making it faster and more efficient without model-specific training. This method can universally apply to any text embedding, recovering key semantic information.
Methodology
ZSinvert introduces a novel approach for embedding inversion that does not require a separate model for each embedding type. It utilizes adversarial decoding to generate text from embeddings efficiently. The method comprises three key stages:
- Initial Seed Generation: It begins with an open-ended prefix prompt to generate diverse initial sequences, employing adversarial decoding to maximize embedding similarity.
- Paraphrase-based Refinement: The generated seeds are refined using a specific prefix prompt to explore semantically similar paraphrases, governed by a beam search algorithm that optimizes cosine similarity with the target embedding.
- Correction using an Offline Model: This step employs a correction model trained offline to enhance the quality of the inversion by taking multiple candidate outputs and producing a more accurate reconstruction.
ZSinvert is designed to be query-efficient, utilizing a minimal number of queries to the embedding encoder, unlike traditional methods, which are query-intensive and less adaptable to noise (Figure 1).
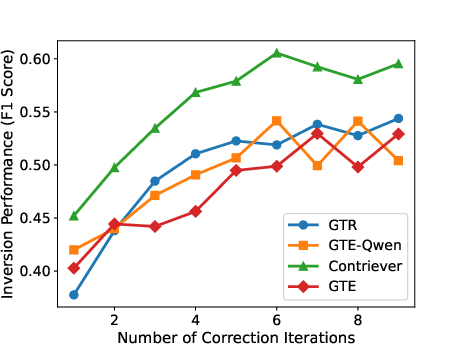
Figure 1: Text inversion performance increases as we increase the number of correction iterations. The correction model is only trained on contriever candidate inversions, but it transfers to all other encoders.
Evaluation
The authors assess ZSinvert's performance using datasets like MS-Marco and the Enron email corpus across several encoders such as Contriever, GTE, and GTR. The results indicate that while vec2text produces more lexically precise inversions, ZSinvert achieves high semantic similarity with the original text, boasting an F1 score above 50 and cosine similarity over 90%. Specifically, ZSinvert is able to achieve significant improvements in semantic recovery, even in the presence of embedding noise.
Furthermore, ZSinvert demonstrates resilience against noise in embeddings. The ability to maintain efficacy with noisy embeddings is crucial, as adding noise is commonly proposed as a defense mechanism against inversion.
Implications and Future Directions
From a security perspective, the paper underscores the potential threat posed by embedding inversion, suggesting that embeddings should be treated with the same level of confidentiality as the original documents. It calls for caution when sharing embeddings with third-party services or storing them in vector databases.
Theoretically, ZSinvert can drastically reduce the resources required for embedding inversion, broadening its accessibility to less sophisticated adversaries. Future research could explore embedding inversion techniques that do not require query access, potentially using alternative means to infer semantics.
Conclusion
ZSinvert offers a significant advancement in the field of text embedding inversion by providing a universal, zero-shot method that remains robust even under noisy conditions. It presents a compelling case for the careful handling of embeddings in NLP applications, highlighting both the technical innovation and the inherent security risks associated with this technology. The method's efficiency and adaptability could reshape how sensitive information encoded in embeddings is managed and protected in practical applications.
