- The paper introduces SynDisco, a framework utilizing synthetic discussions by LLMs to evaluate six online moderation strategies.
- The paper demonstrates that an RL-inspired 'Moderation Game' strategy improves discussion quality by reducing toxicity more effectively than traditional guidelines.
- The paper finds that using smaller LLMs produces more diverse discussions compared to larger, heavily aligned models, highlighting crucial trade-offs.
Scalable Evaluation of Online Facilitation Strategies via Synthetic Simulation of Discussions
Introduction
The research presents a methodology using synthetic simulations by LLMs for evaluating online moderation strategies, aiming to address the challenges of involving human participants in moderation experiments. The study evaluates six different moderation configurations, offering a comprehensive evaluation of synthetic LLM-driven discussions as a viable alternative to human involvement in moderation research. The introduced approach includes the development of a framework named "SynDisco" for simulating discussions, accompanied by the release of the Virtual Moderation Dataset (VMD).
Methodology
The methodology relies on synthetic experiments conducted by LLMs to evaluate different moderation strategies. Synthetic discussions are defined mathematically, utilizing sets of users and comments to simulate discussions with or without moderation. These comments are generated recursively by LLM user-agents, employing specific instructions varied by role and strategy. Six moderation strategies, including both real-life inspired and experimental approaches, are tested to determine their effectiveness (Figure 1).
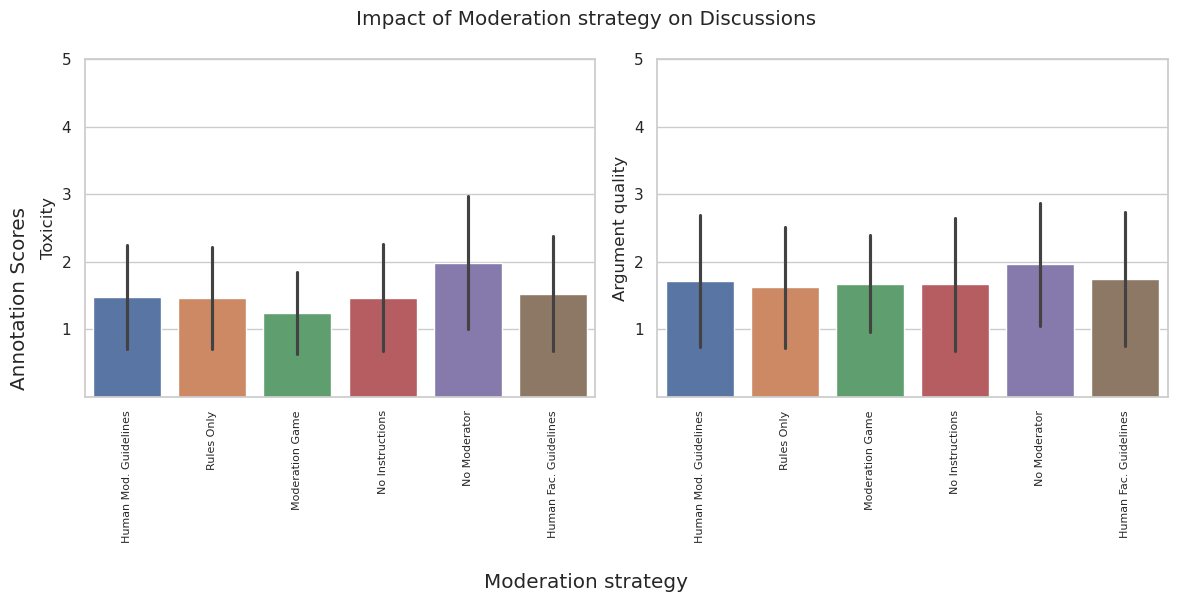
Figure 1: Effects of moderation strategy for toxicity and argument quality. Error bars represent the 95% confidence interval.
The evaluation employs a statistical framework to compare moderation strategies, fundamentally relying on comment-level measures of toxicity and argument quality. Measures are annotated by LLMs to assess the effectiveness of each strategy. SynDisco is designed to efficiently manage synthetic discussions, annotation, and randomization tasks, ensuring reliable experimentation over hundreds of synthetic discussions.
Results
The experiments reveal that the proposed RL-inspired "Moderation Game" strategy notably improves synthetic discussions, outperforming other moderation configurations, including those derived from real-life guidelines (Figure 2). Surprisingly, established moderation guidelines do not significantly outperform basic or out-of-the-box baseline strategies, particularly in terms of reducing toxicity.
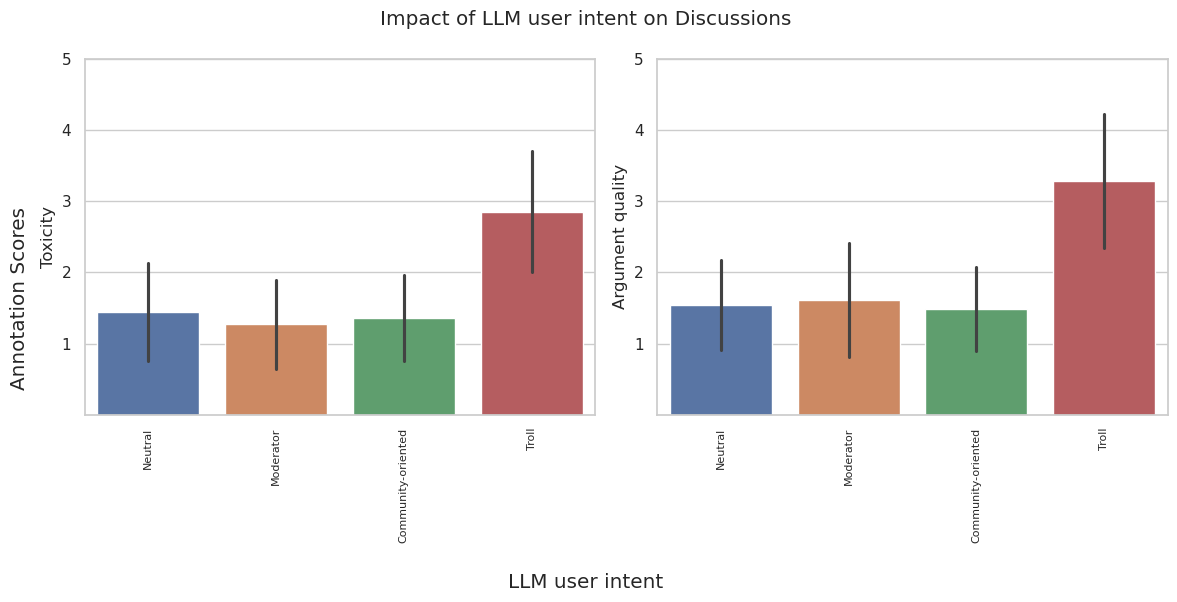
Figure 2: Effects of LLM user-intent for toxicity and argument quality. Error bars represent the 95% confidence interval.
LLM moderators demonstrate a tendency toward over-intervention, which is unrepresentative of human moderators and may require addressing in future fine-tuning sessions. Results also highlight the negative impact of LLM user-agents with trolling intentions on the quality and toxicity of discussions.
In examining model diversity, smaller LLMs, such as Qwen-2.5, result in more varied discussions compared to larger LLMs like LLaMa-3.1, which tend toward stereotypically polite behavior and less diverse linguistic expressions (Figure 3). This suggests that intense alignment procedures in larger models may limit variability in synthetic discussions.
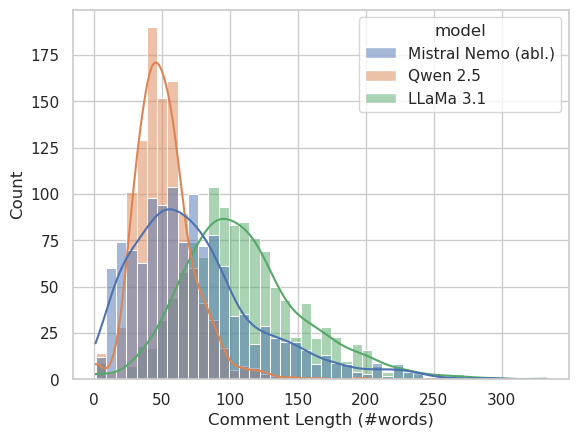
Figure 3: Histogram of the length of comments (number of words) produced by various LLMs.
Technical Implementation
The technical implementation utilizes three open-source LLMs with varying parameters and specifications for generating and annotating discussions. Different models are employed for user-agents and annotation, with the LLaMa-3.1 model being specifically used for synthetic annotation due to its reliable toxicity assessment.
Virtual Moderation Dataset
The resulting VMD dataset consists of a broad array of synthetic discussions and annotations, providing extensive data for further research. This dataset can be utilized to explore the behaviors of different LLMs under various moderation strategies and to further analyze the efficacy of synthetic simulations of online moderation.
Conclusion
The research successfully demonstrates the potential for using LLMs to simulate online discussions with different moderation strategies, significantly reducing the need for human involvement in moderation experiments. It highlights the promising performance of LLMs, particularly in moderation roles, while pointing out areas where further refinement and understanding are necessary.
Future work involves exploring correlations between synthetic simulations and real-world moderation outcomes to understand synthetically replicated discussion dynamics and their potential application in training human moderators. Additionally, more advanced moderator models, possibly including reinforcement learning steps or RAG-based models, could be developed and compared with baseline models to gain deeper quantitative insights.