- The paper presents a novel model that integrates GNNs with knowledge graph embeddings to effectively mitigate information overload in fraud detection.
- The paper employs a Multi-Path Weighted Convolution Network to enhance node representation and improve resilience against hidden label noise.
- The paper demonstrates superior detection performance with higher AUC scores over traditional and state-of-the-art methods on extensive Chinese stock market datasets.
Corporate Fraud Detection in Rich-yet-Noisy Financial Graph
The paper "Corporate Fraud Detection in Rich-yet-Noisy Financial Graph" (2502.19305) addresses the challenge of detecting corporate fraud in large-scale, complex financial graphs. By leveraging Graph Neural Networks (GNN) and Knowledge Graph Embeddings (KGE), the proposed model focuses on mitigating issues of information overload and hidden fraud inherent in the noisy datasets.
Introduction
The paper identifies two critical challenges in corporate fraud detection using financial graphs: information overload and hidden fraud. Information overload occurs due to the dominance of non-company nodes in the graph, creating noise that complicates message passing in GNNs. Hidden fraud refers to undetected fraudulent activities that introduce label noise and affect model accuracy.
The proposed model, Knowledge-enhanced GCN with Robust Two-stage Learning, incorporates KGEs to distill relevant information from support nodes, mitigating information overload. Additionally, it employs a two-stage robust learning method to enhance resilience against label noise from hidden frauds.
Methodology
Knowledge-Enhanced GCN
The model utilizes KGE to convert financial transactions and relationships into a feature space where GNN can effectively process them without succumbing to information overload. The knowledge graph is constructed with important financial entities and relationships, such as company-to-transaction links.
Multi-Path Weighted Convolution Layers
To process the graph data, a Multi-Path Weighted Convolution Network (MW-GCN) is employed. This network accounts for the varying importance of different relational paths in the graph, enhancing node representation quality.
Robust Two-Stage Learning
The model's robustness to hidden fraud is achieved through a two-stage learning framework. Initially, a transition model estimates the likelihood of hidden fraud, capitalizing on instance and neighborhood dependencies. In the second stage, the main model is optimized with a corrected loss function to account for the noise egressed from hidden fraud.
Experimental Results
Dataset
The model is evaluated on three rich datasets from the Chinese stock market, divided into the Main Board Market (MBM), Growth Enterprise Market (GEM), and Small and Medium Enterprise Board Market (SME). Each dataset employs historical financial records over 18 years, incorporating company attributes and relational data.
The proposed model significantly outperforms traditional methods such as XGBoost and DNN, as well as state-of-the-art GNN models like DAGNN and FastGTN. In terms of Area Under the Curve (AUC) scores, it consistently registers higher values, indicating superior fraud detection capabilities.
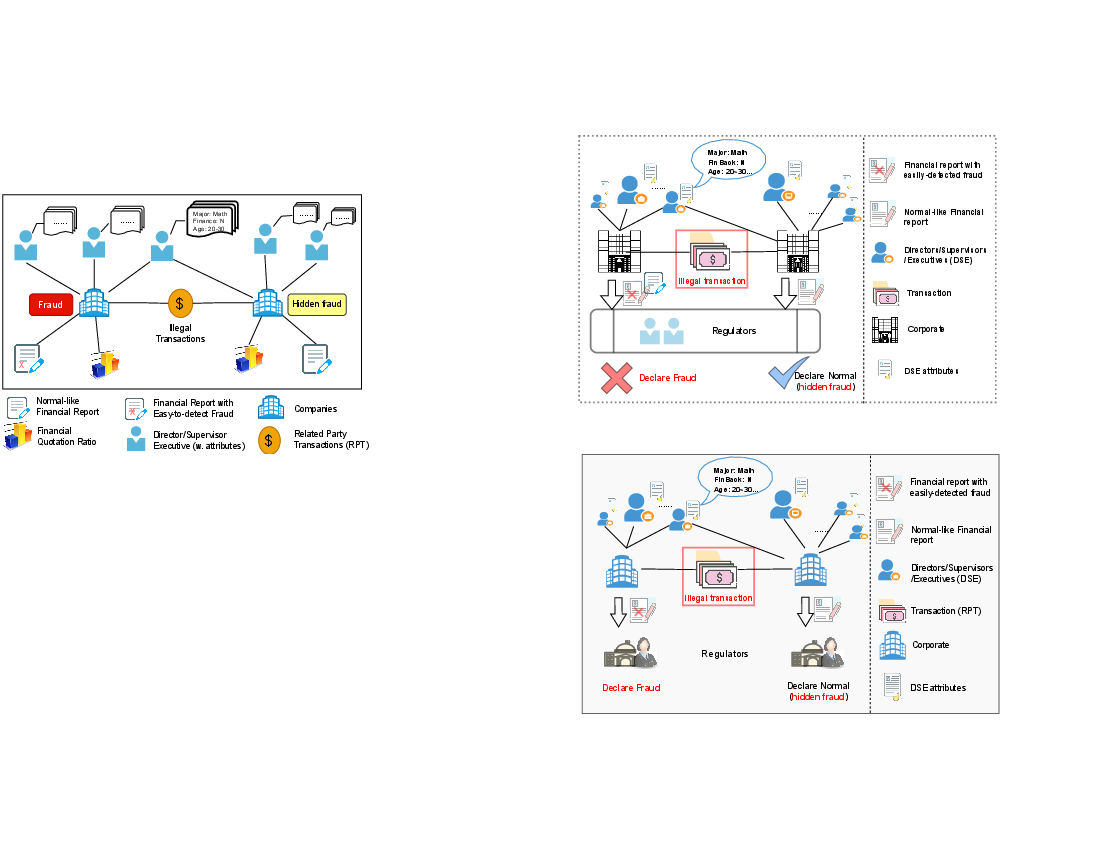
Figure 1: Relations (e.g. illegal transactions) are essential for corporate fraud detection. When a violation goes undetected in the historical record, it is referred to as a hidden fraud case. Such cases become label noises hindering the effectiveness of corporate fraud detection.
Implications and Future Work
The research demonstrates the efficacy of integrating KGE with GCNs to address the dual challenges of information overload and hidden fraud in fraud detection. The structural adaptations cater specifically to financial datasets, enabling more accurate detection in the presence of noisy data.
Future work could explore further refinements in handling class imbalance and the distinct characteristics of specific fraud schemes. Additionally, the adaptability of the model to other industries or graph-based problems represents a potential direction for extending its applicability.
Conclusion
The paper offers a comprehensive solution for corporate fraud detection in complex and noisy financial graphs, significantly improving detection accuracy through innovative use of KGE and robust learning techniques. The approach provides a solid foundation for tackling similar challenges in other domains involving relational data.