- The paper introduces AutoCas, a novel framework that leverages autoregressive LLMs to predict information cascades in social networks with enhanced accuracy.
- The paper employs a unique cascade tokenization method, combining local and global embeddings with prompt learning to model dynamic diffusion patterns.
- The paper demonstrates significant performance improvements over traditional methods, reducing prediction errors such as MSLE and MAPE across various social platforms.
AutoCas: Autoregressive Cascade Predictor in Social Networks via LLMs
Introduction
The paper introduces AutoCas, a framework employing LLMs to predict information cascade popularity in social networks. AutoCas capitalizes on the autoregressive modeling capabilities of LLMs to handle the sequential and dynamic nature of information diffusion across vast and complex networks. This model is particularly relevant in the domain of social computing, where predicting the spread and popularity of information has significant applications in marketing, misinformation control, and content recommendation.
Cascade Popularity Prediction
AutoCas addresses the challenge of modeling information cascades, defined as the process through which information disseminates through a network of users. Traditional methods often fall short due to the intricate, evolving dynamics of user interactions and content diffusion. AutoCas reformulates these diffusion processes using autoregressive modeling, recognizing the sequential dependencies characteristic of cascades. This approach aligns well with LLMs, which excel at predicting subsequent elements in a sequence based on historical data.
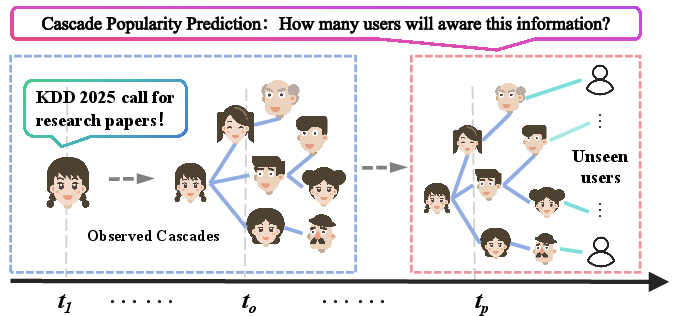
Figure 1: Illustration of cascade popularity prediction. Given an information item, the target is to model its diffusion process and predict how many users will be aware of it.
Methodology
1. Cascade Tokenization
One of the key innovations in AutoCas is the tokenization of cascade data. Unlike natural language, cascade data involves complex interactions that require special treatment. AutoCas first extracts local embeddings from the cascade graph and global embeddings from the broader network context. These embeddings are fused to create cascade token sequences which summarize the propagation state at various time periods within the cascade timeline.
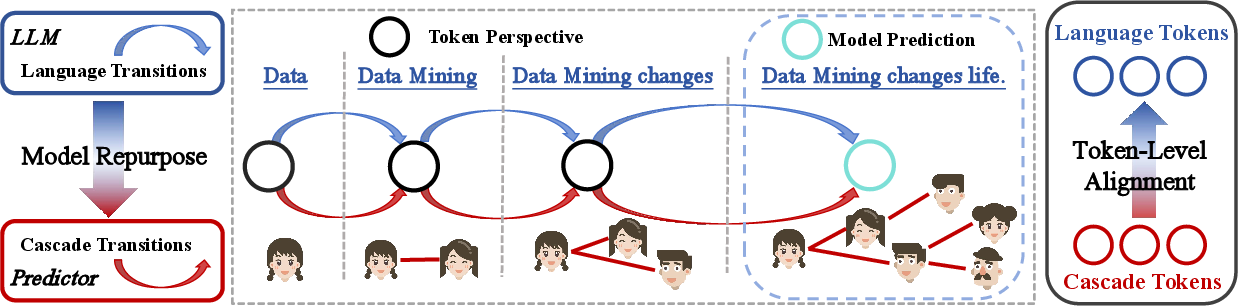
Figure 2: The motivation of adapting LLMs for cascade modeling, illustrating the parallels between text generation and cascade diffusion in sequence modeling.
2. Autoregressive Modeling
AutoCas leverages the autoregressive framework by using projected cascade tokens as input to a fixed pre-trained LLM. The LLM's parameters remain frozen, preserving its learning capacity while allowing AutoCas to efficiently adapt to the task through lightweight layers on top of the model. This design choice minimizes computational costs and optimizes scalability, as it doesn't require retraining the entire model for different cascade instances or prediction horizons.
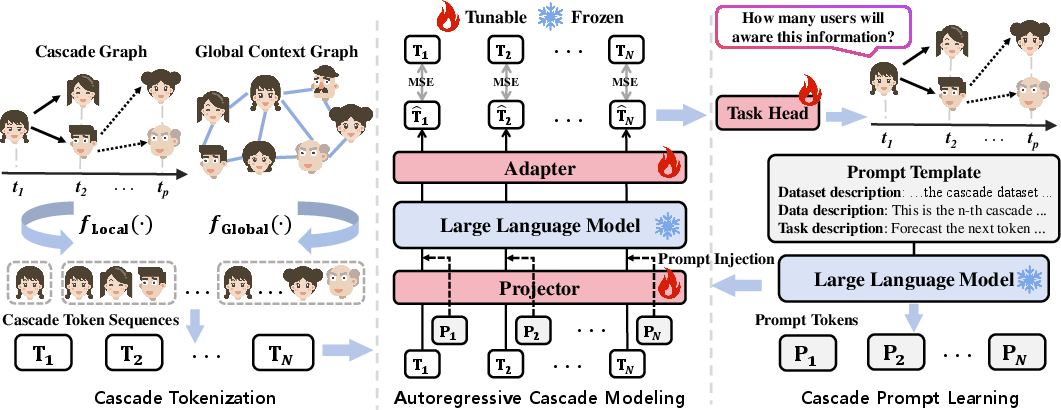
Figure 3: The overview framework of AutoCas, highlighting local and global embeddings extraction, autoregressive modeling, and prompt integration.
3. Prompt Learning
To enhance the LLM's adaptability, AutoCas incorporates prompt learning, tailoring textual prompts that guide the LLM in understanding task-specific contexts. These prompts are informed by the temporal and structural specifics of the cascade data, ensuring that the model's predictions are grounded in relevant context-driven cues.
Experimental Evaluation
AutoCas was evaluated on datasets from platforms like Weibo, Twitter, and APS. The results demonstrated significant performance improvements over existing methods, with marked reductions in prediction error metrics such as MSLE and MAPE. AutoCas exhibited scalability, benefiting from the underlying LLM as model parameters increased, aligning with the scaling laws observed in language modeling.
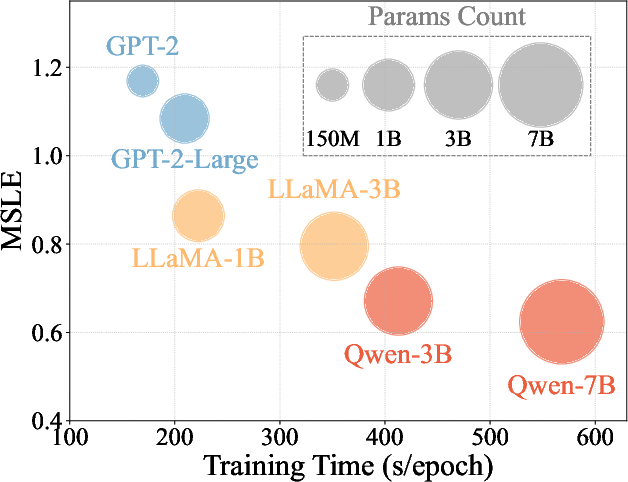
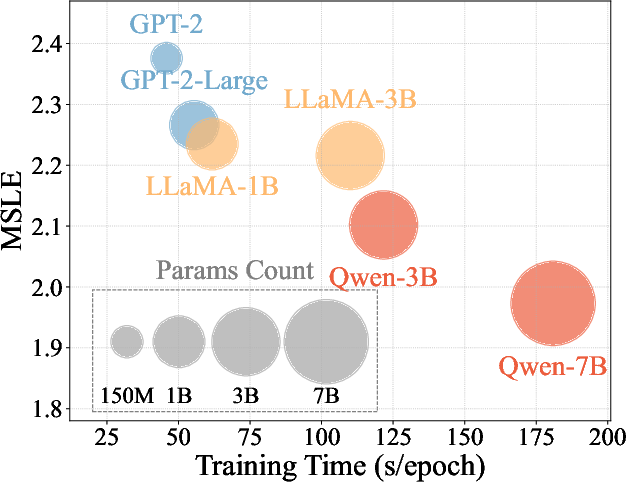
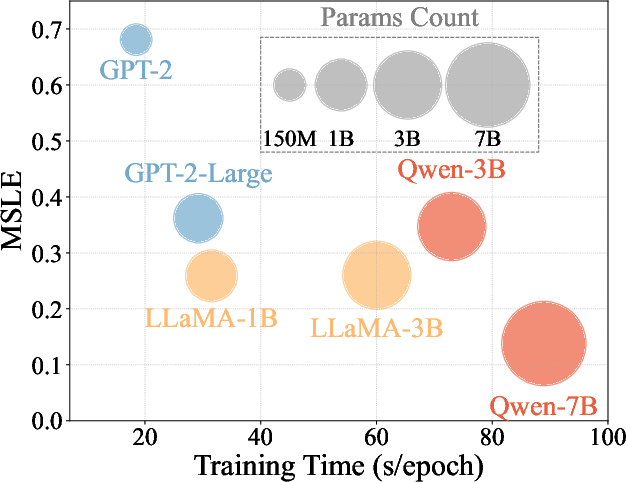
Figure 4: Performance and training efficiency comparison of AutoCas with different LLMs, assessing scalability across datasets.
Conclusion
The integration of LLMs into cascade modeling presents a robust approach to dealing with the complexities of information diffusion in social networks. AutoCas leverages the sequential nature of cascades and the autoregressive capabilities of LLMs, offering a sophisticated tool for popularity prediction tasks. Future research may explore broader applications of this approach, potentially extending beyond social networks into other domains requiring sequential prediction capabilities.

