- The paper demonstrates that LLMs can closely match human scoring on L2 writing assessments, differing by at most one point on a 10-point scale.
- The methodology involves prompting LLMs to generate feedback on nine analytic criteria using literature reviews annotated by human experts.
- The study highlights LLM-generated comments as more nuanced and detailed, suggesting scalable solutions for L2 English writing assessment.
Introduction
LLMs have increasingly demonstrated potential in automating complex tasks traditionally performed by human experts. This paper investigates the capability of LLMs to conduct multi-dimensional analytic writing assessments, specifically focusing on L2 (second language) English writing by graduate students. The primary goal is to assess whether LLMs can provide reliable and informative scores and feedback comments across multiple predefined analytic criteria.
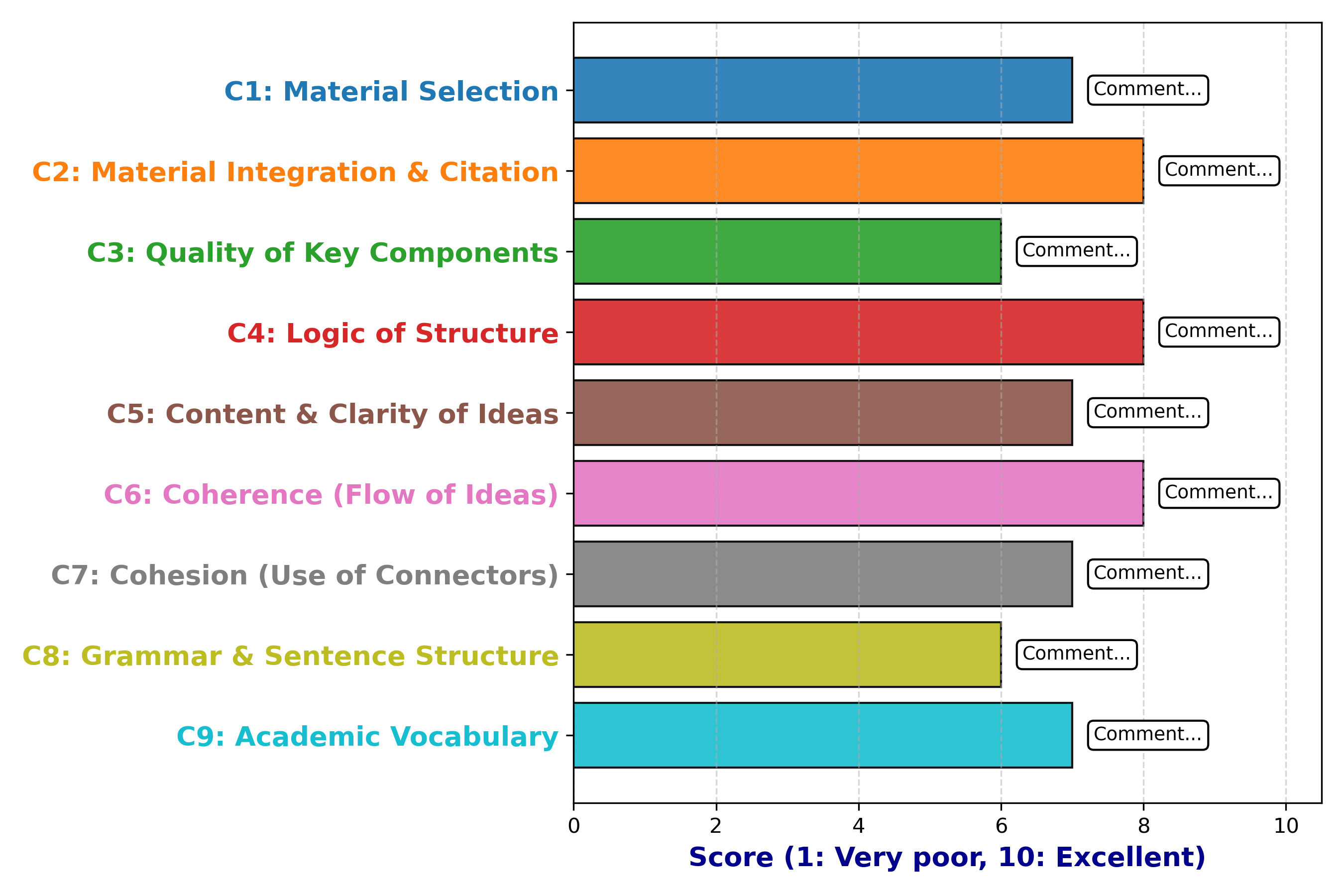
Figure 1: Multi-dimensional analytic assessments, where each assessment contains a score and a comment.
Methodology
The paper utilizes a corpus of literature reviews composed by L2 graduate students. These reviews are annotated by human experts based on nine analytic criteria, including material selection, citation practices, grammatical accuracy, and logical structure, among others. Several prominent LLMs were prompted to assess the same corpus under various controlled conditions. The evaluation framework proposed in this paper involves automatically generating feedback comments using LLMs and comparing their quality with human-generated comments.
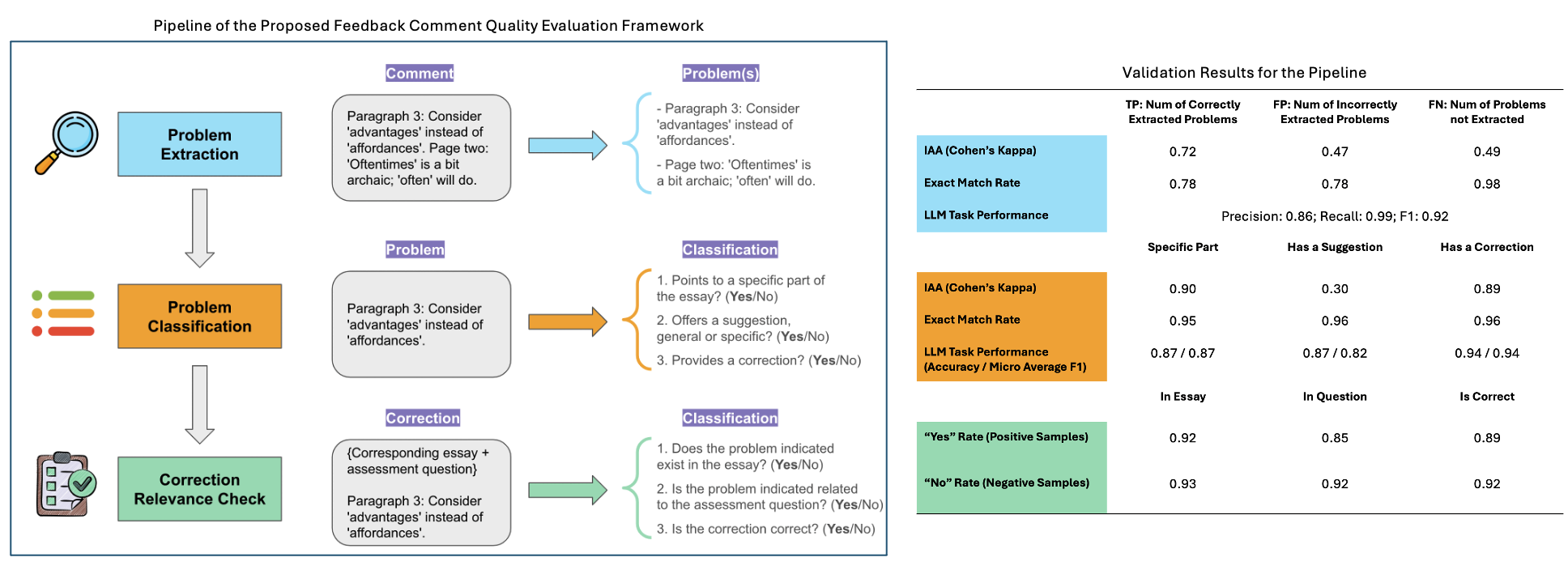
Figure 2: Left: Pipeline of the proposed feedback comment quality evaluation framework.Right: Validation results for the pipeline, showcasing high inter-annotator agreement and exact match rates.
Results
The paper presents substantial findings demonstrating that LLMs can generate reasonably correlated scores with human assessments, often differing by no more than one point on a 10-point scale for most criteria. Critically, LLMs consistently provide comments that identify problems, often more elaborately than human assessors under specific interaction conditions. For example, LLMs are found to be particularly effective in generating detailed feedback when each assessment question is asked independently, highlighting their capability for nuanced analysis (Figure 3).
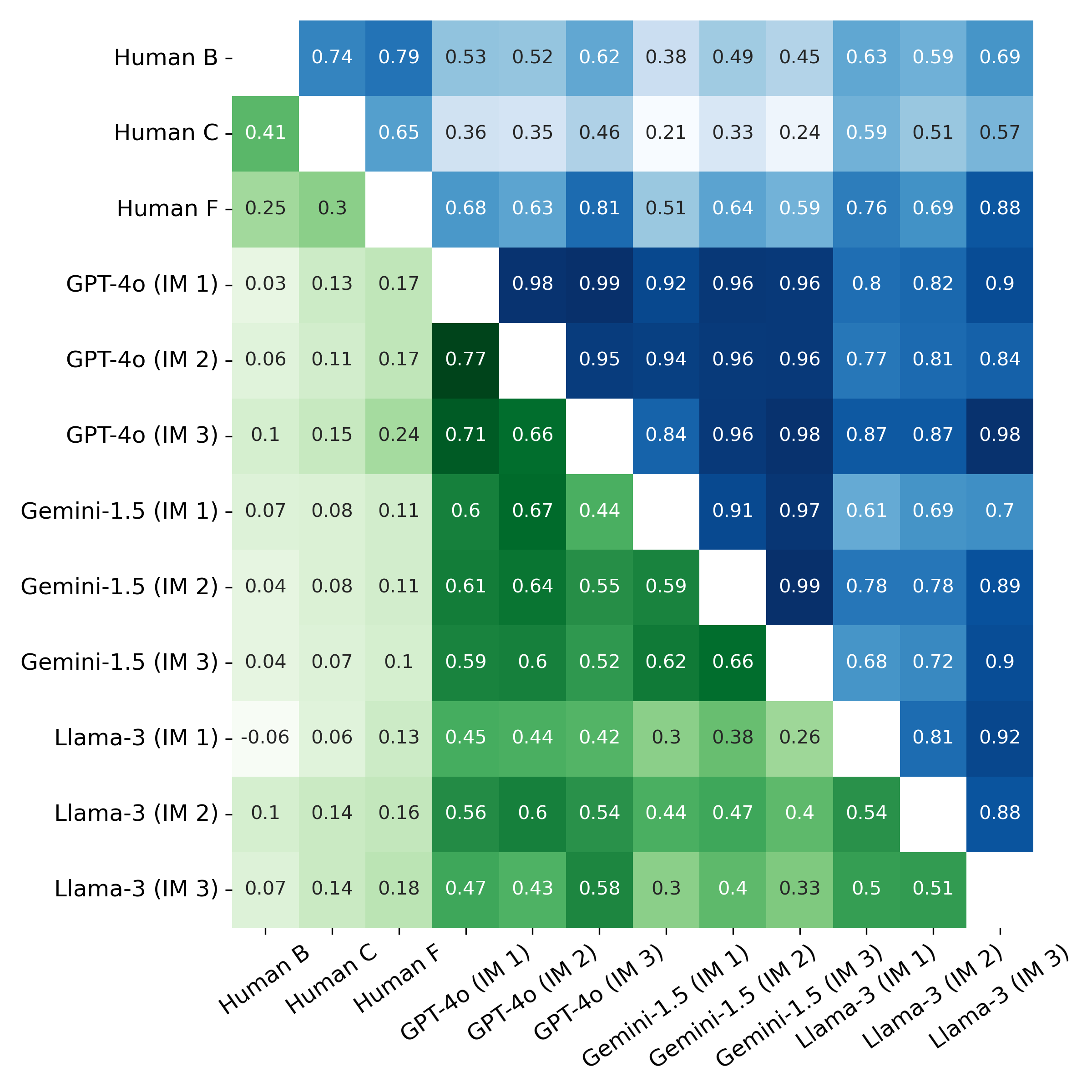
Figure 4: Heatmaps of overall QWK and AAR1 among assessors, indicating varying degrees of agreement across criteria.
The assessment of feedback comment quality indicates that LLM-generated comments can be precise and potentially more helpful than those generated by humans, given their ability to continuously operate without cognitive fatigue. The paper proposes a novel framework that characterizes comments based on their specificity, helpfulness, and ability to identify problems—a method that offers a finer granularity compared to traditional manual metrics (Figure 2).
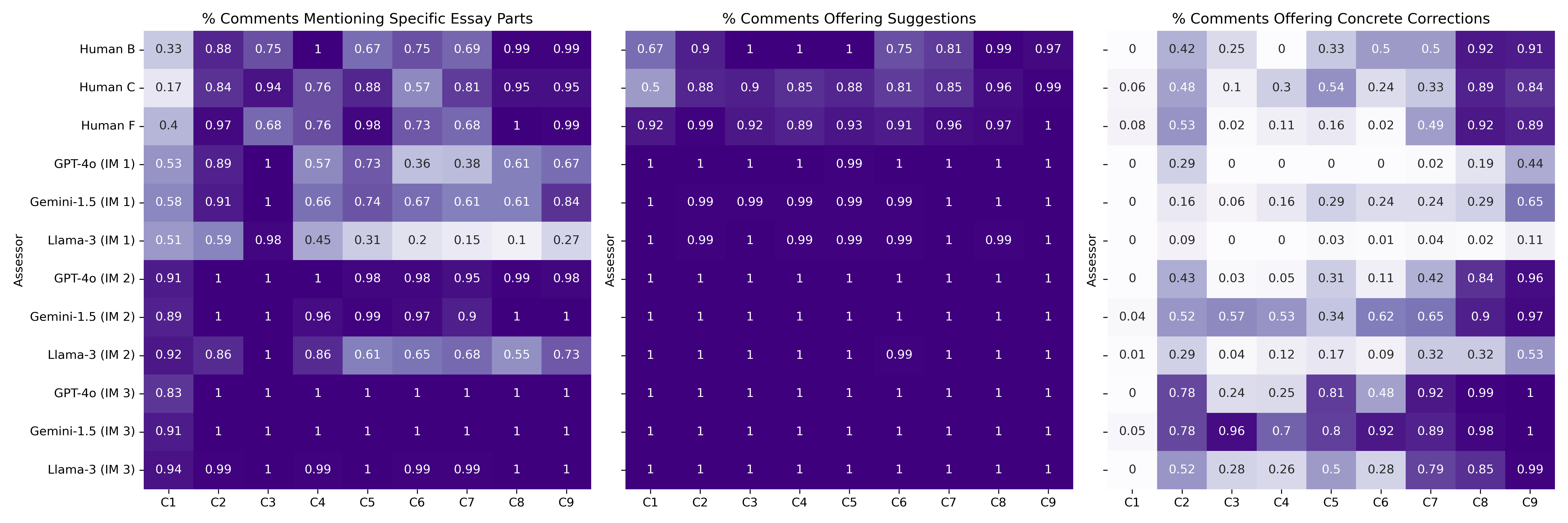
Figure 3: Distribution of comment characteristics across criteria, including specificity and the frequency of corrections offered.
Implications and Future Directions
The findings suggest that LLMs hold promise for integration into educational contexts, particularly for aiding in the self-regulated learning of L2 students. The potential applications extend to forming a basis for scalable solutions in automated writing assessments that provide consistent and informative feedback. Future research could explore enhancing LLM interactions to further improve their feedback specificity and alignment with pedagogical standards.
Conclusion
This case paper provides concrete evidence of the role LLMs can play in performing multi-dimensional analytic writing assessments, demonstrating their ability to match human evaluations in scoring consistency and comment relevancy. The results underscore the potential for adopting LLMs in educational settings to enhance writing assessment efficiency and feedback quality, though further work is needed to refine these models and explore their applicability across diverse writing contexts.
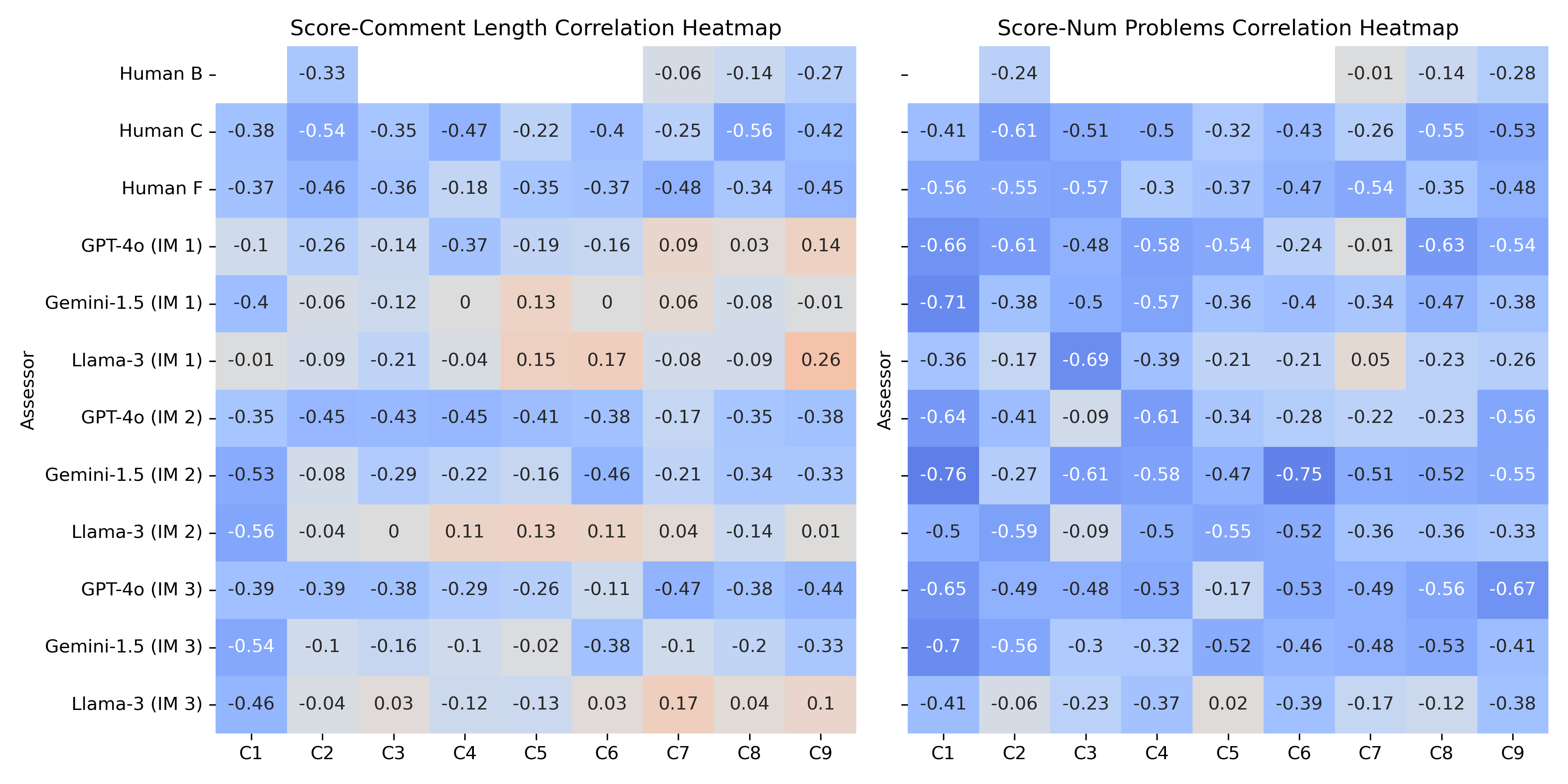
Figure 5: Heatmaps showing correlations between scores and comment characteristics among human and LLM assessments.
