BitsAI-CR: Automated Code Review via LLM in Practice
Abstract: Code review remains a critical yet resource-intensive process in software development, particularly challenging in large-scale industrial environments. While LLMs show promise for automating code review, existing solutions face significant limitations in precision and practicality. This paper presents BitsAI-CR, an innovative framework that enhances code review through a two-stage approach combining RuleChecker for initial issue detection and ReviewFilter for precision verification. The system is built upon a comprehensive taxonomy of review rules and implements a data flywheel mechanism that enables continuous performance improvement through structured feedback and evaluation metrics. Our approach introduces an Outdated Rate metric that can reflect developers' actual adoption of review comments, enabling automated evaluation and systematic optimization at scale. Empirical evaluation demonstrates BitsAI-CR's effectiveness, achieving 75.0% precision in review comment generation. For the Go language which has predominant usage at ByteDance, we maintain an Outdated Rate of 26.7%. The system has been successfully deployed at ByteDance, serving over 12,000 Weekly Active Users (WAU). Our work provides valuable insights into the practical application of automated code review and offers a blueprint for organizations seeking to implement automated code reviews at scale.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces BitsAI-CR, a smart tool that helps software engineers review code using LLMs. Code review is like proofreading and testing your homework before turning it in—it catches mistakes, improves clarity, and keeps things secure. But doing it by hand can be slow and tiring, especially in big companies. BitsAI-CR is designed to make code reviews faster, more accurate, and more useful in real-world software teams.
Key questions the researchers wanted to answer
The paper focuses on solving three big problems with AI code review:
- How can we make AI-generated review comments technically accurate and trustworthy?
- How can we ensure the comments are actually helpful, not just technically correct but unimportant?
- How can we continuously improve the system over time using real user feedback?
How the system works: Methods in simple terms
Think of BitsAI-CR as a two-part assistant with a “train, check, learn” loop:
The two-stage review pipeline
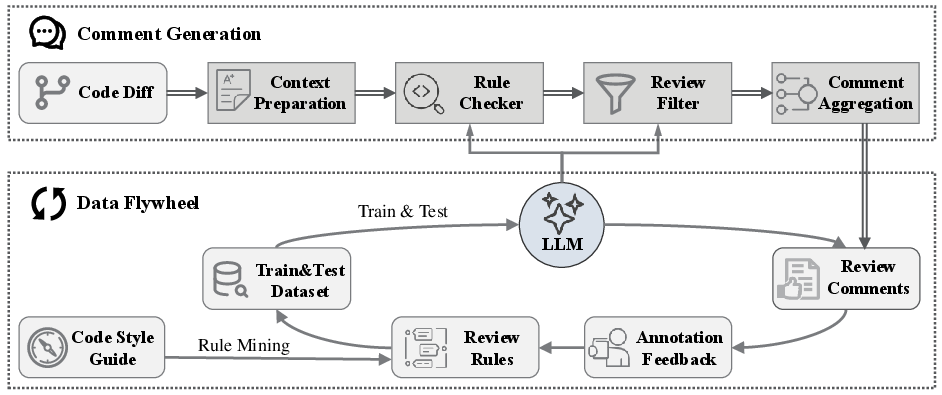
- RuleChecker: This is the “first inspector.” It scans code changes and uses a library of 219 clear, detailed rules to spot potential problems (like confusing names, logic mistakes, security risks, or performance issues).
- ReviewFilter: This is the “double-checker.” It reviews what RuleChecker flagged and keeps only the comments that are actually correct and useful. This helps reduce AI mistakes or “hallucinations” (when the AI makes something up).
To prepare the code for review, the system:
- Organizes code changes into manageable chunks.
- Adds helpful context so the AI sees the whole function, not just a tiny snippet.
- Marks which lines were added, deleted, or unchanged, so it knows exactly what changed.
There’s also a Comment Aggregation step that combines similar suggestions, so developers don’t get spammed with repeated messages.
The rule library (taxonomy)
The system uses a structured set of review rules grouped into broad areas:
- Code defects (logic errors, handling mistakes, missing checks)
- Security vulnerabilities (like SQL injection, XSS)
- Maintainability and readability (clear naming, comments, duplicated code)
- Performance issues (inefficient loops, unnecessary work)
This “rule map” helps train the AI, measure its performance, and make targeted improvements.
The data flywheel: A continuous improvement loop
This is like practicing a sport with feedback:
- Collect real review comments and developer reactions (likes/dislikes).
- Measure how often flagged code actually gets changed later.
- Improve the training data and rules based on what works and what doesn’t.
- Repeat weekly to keep getting better.
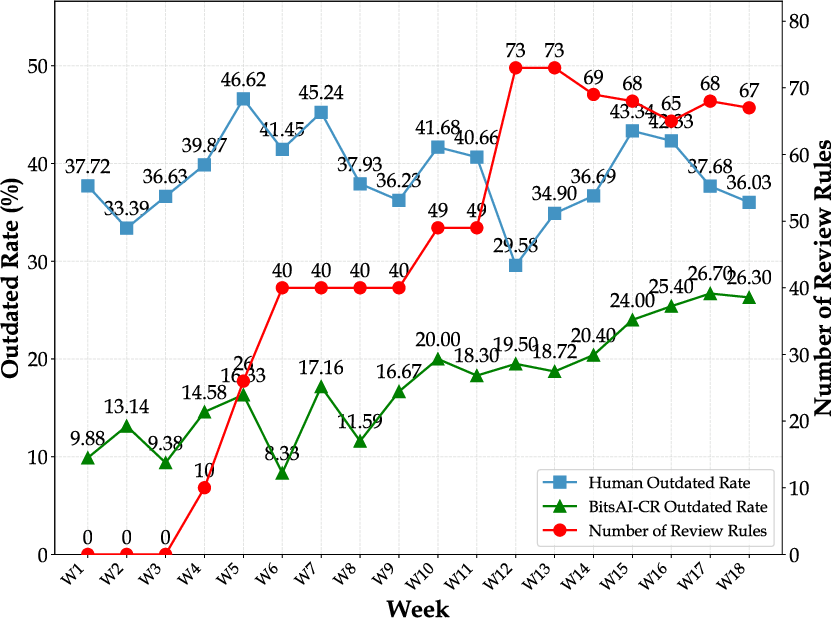
A key metric they use is the “Outdated Rate.” In simple terms: if the AI comments on some lines and those lines get changed later, that comment is considered “outdated”—which is a good sign that the developer acted on it. This helps measure whether comments lead to real fixes, not just whether they’re technically correct.
Main findings and why they matter
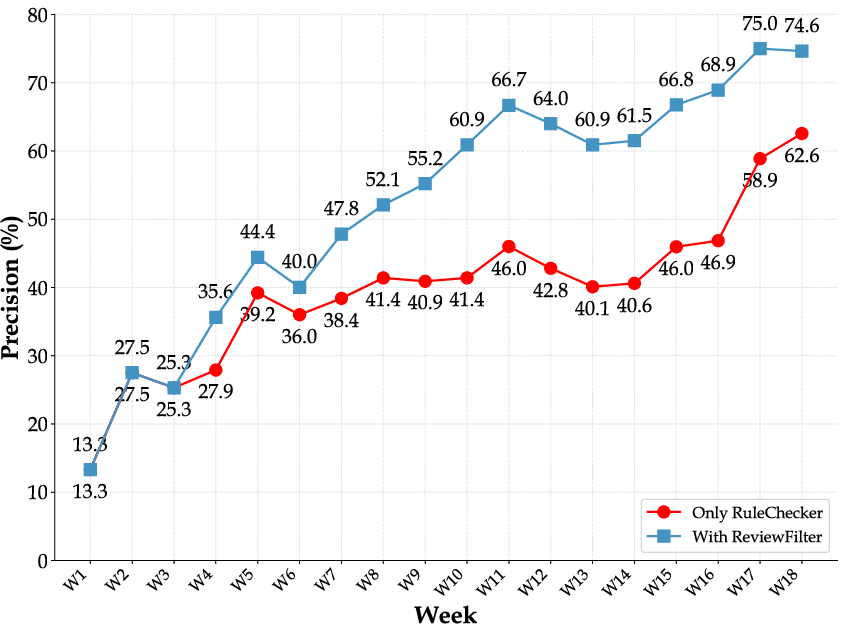
- Higher accuracy: With the two-stage pipeline, BitsAI-CR reached 75% precision, meaning 3 out of 4 comments were correct and useful.
- Real-world impact: In the Go programming language (widely used at ByteDance), the Outdated Rate reached 26.7%. That means a solid chunk of flagged code got improved after the AI’s suggestion. Human reviewers at ByteDance have a 35–46% Outdated Rate, so the AI is getting closer to human effectiveness.
- Large-scale use: The system serves over 12,000 weekly active users inside ByteDance.
- Better design choices: For the ReviewFilter, a “Conclusion-First” style worked best—give a quick “Yes/No” decision first, then a short reason. This boosted precision while keeping the system fast.
- Smarter training with rules: Training the AI using the rule taxonomy greatly improved results compared to training on random review data.
- Practical improvements over time: By removing rules that were technically correct but not useful in practice, the system steadily improved both precision and Outdated Rate.
What this means: Impact and future benefits
BitsAI-CR shows that AI can make code review faster and more helpful in big software teams:
- Developers spend less time on low-value comments and more time fixing real issues.
- Teams can maintain code quality and security at scale, even with lots of changes.
- The system’s continuous learning loop means it gets better the more people use it.
- Other organizations can use this framework as a blueprint to build their own reliable AI-assisted code review systems.
In short, this research demonstrates a practical, trustworthy way to use AI for code review: catch useful issues, reduce noise, and grow smarter over time with real-world feedback.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of open issues the paper leaves unresolved, framed to guide future research and engineering work:
- Causal impact of Outdated Rate: No randomized or quasi-experimental evidence that code edits are caused by BitsAI-CR’s comments. Conduct A/B tests (with/without comments, randomized per MR or per rule) to estimate causal uptake and effect sizes.
- Validity of Outdated Rate as a proxy: Outdated is triggered if any flagged line changes, which can reflect unrelated edits (refactors, merges, formatting). Develop stricter linkage (e.g., semantic diff alignment, edit intent classification, commit message/topic modeling) and report precision/recall of “true acceptance” of suggestions.
- Missing productivity and quality outcomes: No measurement of time-to-merge, review latency, reviewer/author effort, number of review rounds, post-merge defects, reverts, or production incidents. Add operational and quality KPIs to quantify end-to-end value.
- Limited external validity: Results are from a single enterprise, using proprietary tools, data, and models. Assess generalizability across organizations, repositories, domains, and development cultures; provide replication studies or public benchmarks.
- Reproducibility constraints: Proprietary LLM (Doubao), embeddings, datasets, and pipelines prevent independent verification. Provide redacted datasets, synthetic benchmarks, or reproducible pipelines with open models where feasible.
- LLM-as-a-judge limitations: Offline evaluation relies on a single in-house LLM judge, risking bias and overestimation. Include human double-blind annotation, inter-annotator agreement, and cross-model judges (ensemble of different families) to validate findings.
- Small and imbalanced offline test set: Only 1,397 cases with unclear per-category/sample-size distributions and potential class imbalance. Expand the test set, stratify per rule/category/language, and report confidence intervals and power analyses.
- Under-specified annotation quality: No details on annotator training, protocols, or inter-annotator agreement for manual precision labels. Establish rigorous labeling guidelines, measure agreement (e.g., Cohen’s κ), and publish error analyses.
- Thresholds for rule retention/removal are heuristic: The chosen targets (~65% precision, ~25% Outdated Rate over 14 days) lack empirical justification. Optimize thresholds per category via multi-objective analysis and sensitivity studies.
- Limited coverage of recall and false negatives: The system prioritizes precision but does not quantify the cost of missed issues (e.g., severe bugs not flagged). Add targeted recall assessments for high-severity categories (security, correctness) and measure downstream risk.
- Incomplete baseline comparisons: No head-to-head evaluation against state-of-the-practice static analyzers and commercial code-review assistants in production settings. Benchmark combined/ensemble approaches and deduplication with static analysis alerts.
- No analysis of multi-file and cross-hunk reasoning: Context is limited to hunks and nearby function boundaries; issues spanning files or modules are not evaluated. Study techniques for project-wide context (e.g., program slicing, call graphs, repository-level context windows).
- Context preparation ablation missing: Heuristics (e.g., 3–4× diff expansion) are untested. Perform ablations to quantify the contribution of context window strategies, tree-sitter accuracy, and annotation schemes to precision/latency.
- Comment aggregation strategy is naive: Cosine similarity with random retention can discard the most informative instance and miss near-duplicates. Evaluate clustering methods (e.g., hierarchical clustering, centroid selection) and human-centered summarization quality.
- Limited language coverage and uneven data: Go dominates; other languages have far fewer training samples. Report per-language online metrics (precision, Outdated Rate, latency), analyze transferability, and explore multi-task/multilingual training.
- Explainability and developer trust: ReviewFilter’s “Conclusion-First” pattern optimizes for precision/latency, but how reasoning is surfaced to developers and its effect on trust and adoption are not evaluated. Run UX studies on explanation utility and transparency.
- Governance and safety of auto-approval (“LGTM”): BitsAI-CR can issue LGTM; risks of false approvals and bypassing human oversight are not assessed. Define safety constraints, fallback policies, and audited gates for auto-approval.
- Security-specific validation lacking: No evidence of catching real vulnerabilities or preventing incidents. Conduct red-team evaluations, seeded vulnerability tests, and track true positive/false negative rates in security-critical categories.
- Drift and lifecycle management: Rule and model drift over time are not monitored beyond precision and Outdated Rate. Add drift detection, calibration monitoring, rollback criteria, and safe online learning protocols.
- Potential Goodhart effects: Optimizing for Outdated Rate and precision may encourage rules that prompt trivial edits. Introduce value-weighted metrics (impact scoring, severity-adjusted acceptance) and guardrails against “hygiene-only” optimization.
- Developer burden and skills impact: No study of alert fatigue, cognitive load, or long-term effects on reviewer skill development. Assess ergonomics, effort, and the risk of over-reliance or anchoring bias.
- Cost and scalability metrics missing: The paper does not report per-MR latency, throughput, queueing, or compute cost at 12k WAU. Provide SLOs, resource consumption, and cost-benefit analysis under realistic load.
- Integration with CI/CD and existing tools: Interactions with linters, static analysis, and test pipelines (deduplication, conflict resolution) are not detailed. Evaluate orchestration strategies and unified triage to reduce tool noise.
- Rule taxonomy portability: The process for extending/porting the taxonomy to new languages, frameworks, and domains (e.g., data/ML, infra) is unspecified. Propose systematic rule mining, validation pipelines, and cross-language mapping strategies.
- Robustness to adversarial or tricky code: No tests for prompt injection via code comments, obfuscated patterns, or adversarial examples. Build robustness benchmarks and implement guardrails and sanitization.
- Safety and correctness of suggested fixes: The system does not verify that applied changes preserve semantics or do not introduce regressions. Integrate test-aware validation, speculative edits with verification, or constrained synthesis.
- Interactions with human preferences: Likes/dislikes are sparse and noisy; their signal integration into training is unclear. Explore preference learning, active learning with targeted sampling, and debiasing for popularity vs correctness.
- Severity calibration and prioritization: Comments include severity labels, but calibration and consistency are not evaluated. Calibrate severities and measure alignment with developer triage and actual impact.
- Ethical, privacy, and compliance risks: Handling of sensitive code, secrets, and PII in training/inference is not detailed. Specify data governance, masking, retention, and audit mechanisms for compliance.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. They are grouped by time-to-deploy, linked to relevant sectors, and include indicative tools/workflows and key assumptions or dependencies.
Immediate Applications
- AI-assisted code review in CI/CD pipelines (Software, DevOps)
- Use the two-stage “RuleChecker + ReviewFilter” pipeline to generate high-precision review comments on pull/merge requests across Go, JavaScript/TypeScript, Python, and Java.
- Tools/Workflows: GitHub/GitLab/Bitbucket integration; pre-merge checks; “LGTM” automation; configurable rule blocker; embedding-based comment aggregation to prevent alert fatigue.
- Assumptions/Dependencies: Access to version control diffs; support for on-prem or VPC LLM inference; sufficiently labeled training datasets and style guides; developer buy-in for rule configuration.
- Secure coding gate in SDLC (Cybersecurity, Software)
- Apply the taxonomy’s security categories (e.g., SQLi, XSS, CSRF, insecure deserialization) as automated checks to reduce vulnerabilities before code merge.
- Tools/Workflows: Security policy gates with severity levels; dashboards tracking security-focused Outdated Rate; escalation for high-severity comments.
- Assumptions/Dependencies: Organizational secure coding standards; integration with existing static analysis; consistent measurement of Outdated Rate; audit trail retention.
- Precision-first AI reviewer to rebuild trust (Software, Quality Assurance)
- Use ReviewFilter (Conclusion-First reasoning) to improve precision and minimize hallucinations; prioritize fewer, higher-quality comments to reduce developer fatigue.
- Tools/Workflows: Two-stage inference; precision tracking; rule decommissioning based on precision and Outdated Rate; weekly monitoring.
- Assumptions/Dependencies: Compute budget for LLM inference; continuous annotation to maintain filter quality; acceptance of precision-over-recall trade-off.
- Outdated Rate as an operational metric for adoption and impact (Software, Management)
- Adopt Outdated Rate to measure whether flagged lines actually change post-review, complementing precision and enabling data-driven pruning of low-value rules.
- Tools/Workflows: Team dashboards; weekly reports; threshold-based rule removal; A/B testing of rule sets.
- Assumptions/Dependencies: Instrumentation to track subsequent commits; acceptance of Outdated Rate as a proxy for developer action; window definitions for “seen” comments.
- Embedding-based comment aggregation to reduce noise (Software, DevOps)
- Use semantic similarity to deduplicate comments across files/hunks and reduce cognitive load.
- Tools/Workflows: Embedding service (e.g., Doubbao-embedding-large or alternatives); cosine similarity threshold tuning; grouped presentation of comments.
- Assumptions/Dependencies: Availability of performant embedding models; multi-language embeddings; fine-tuned thresholds per repo.
- Customizable rule taxonomy aligned with house style guides (Software, Enterprise IT)
- Operationalize the paper’s 3-tier taxonomy to reflect organizational standards for readability, maintainability, defects, and performance.
- Tools/Workflows: Rule management UI; rule blocker; style guide-to-rule mapping; rule-level precision and Outdated Rate monitoring.
- Assumptions/Dependencies: Maintained and versioned style guides; governance for rule changes; curator capacity for taxonomy updates.
- Academic grading assistant for programming courses (Education)
- Provide structured, rubric-aligned feedback on student submissions using the taxonomy; filter comments to avoid misleading advice.
- Tools/Workflows: LMS plugins (Moodle, Canvas); assignment auto-review with categories and severity; aggregated feedback to reduce overload.
- Assumptions/Dependencies: Institution-specific rubrics; restricted data processing for student code; reduced compute costs for class-scale usage.
- Open-source PR triage (Software, Open Source)
- Help maintainers label issues, provide readable suggestions, and standardize feedback while avoiding excess comments.
- Tools/Workflows: GitHub Apps; PR labeling; per-repo rule profiles; comment aggregation.
- Assumptions/Dependencies: Maintainers willing to adopt; transparent logs; community acceptance; fallback for unsupported languages.
- Performance hygiene checks (Software, SRE)
- Enforce rules like “unoptimized loops,” “data format conversion performance,” and “excessive I/O” as automated suggestions for performance-sensitive repos.
- Tools/Workflows: Severity tagging; performance rule bundles; tracking of performance-rule Outdated Rate.
- Assumptions/Dependencies: Performance rules tuned to repository context; developers accept non-functional suggestions; validation via perf tests when possible.
- Documentation and readability enforcement (Software, Documentation)
- Use rules for “missing/inappropriate comments,” naming conventions, “magic numbers,” “spelling errors,” and duplication to standardize code readability.
- Tools/Workflows: Comment prompts for docstrings; naming convention enforcement; deduplication detection; style guide mapping.
- Assumptions/Dependencies: Agreement on documentation standards; ability to waive or suppress non-critical rules per team.
- Policy-level internal governance and audit (Policy, Compliance, Finance, Healthcare)
- Record and monitor AI review comments and Outdated Rates as part of SDLC compliance evidence (e.g., SOC 2, ISO 27001, PCI DSS).
- Tools/Workflows: Compliance dashboards; audit exports; rule sets aligned with regulatory controls (secure coding, change management).
- Assumptions/Dependencies: Legal and compliance review; data retention policies; regulator acceptance of AI-assisted evidence.
Long-Term Applications
- Autonomous code fix generation and auto-commit with human oversight (Software, DevOps)
- Move from suggestions to patch generation; use Outdated Rate and developer actions as RL signals to improve auto-fixes.
- Tools/Workflows: “Suggest-and-apply” pipelines; gated auto-commits; rollback and diff review UI; RLHF/RLAIF with adoption signals.
- Assumptions/Dependencies: Strong guardrails; integration with test suites; safety constraints; higher precision for non-trivial edits.
- Standardized “Outdated Rate” as an industry metric (Policy, Software, Academia)
- Formalize Outdated Rate definitions and baselines across organizations; integrate into SDLC quality KPIs and external audit frameworks.
- Tools/Workflows: Industry working groups; standard schemas; benchmarking reports; certification criteria tied to adoption metrics.
- Assumptions/Dependencies: Cross-org consensus; reproducible instrumentation; evidence that Outdated Rate correlates with quality outcomes.
- Multi-language and domain expansion (Robotics, Energy, Finance, Mobile)
- Extend taxonomy to domain-specific rules (e.g., safety-critical robotics code, energy grid control systems, financial risk models, mobile platform APIs).
- Tools/Workflows: Domain-specific rule packs; curated datasets; integration with domain simulators and testbeds.
- Assumptions/Dependencies: Access to domain codebases; SME involvement; safe deployment constraints; tailored evaluation metrics beyond precision.
- Federated or privacy-preserving training across enterprises (Software, Privacy, Security)
- Use federated learning to improve RuleChecker/ReviewFilter without centralizing code data; share taxonomies and signals, not raw code.
- Tools/Workflows: Federated LoRA fine-tuning; secure aggregation; differential privacy; inter-org rule exchange.
- Assumptions/Dependencies: Legal agreements; robust privacy guarantees; compatible model stacks; secure infrastructure.
- Unified AI review across artifacts (IaC, Config, Data Pipelines, ML Ops)
- Apply the two-stage pipeline to infrastructure-as-code, Kubernetes manifests, Terraform, CI configs, SQL, and ML pipeline scripts to catch misconfigurations and data lineage issues.
- Tools/Workflows: Artifact-specific taxonomies; multi-artifact diff parsers; policy gates for IaC and pipeline changes.
- Assumptions/Dependencies: Accurate parsers for each artifact; domain rule development; mapping fixes to deployment workflows.
- Adaptive, personalized rule sets and dynamic reviewer assignment (Software, Developer Experience)
- Tailor rule bundles to team/project maturity; adapt thresholds based on historical Outdated Rate and precision; triage to human reviewers with topic expertise.
- Tools/Workflows: Per-team configuration profiles; adaptive thresholds; reviewer recommender systems; organizational “AI pair reviewer.”
- Assumptions/Dependencies: Historical telemetry; cultural acceptance of personalization; careful avoidance of bias in assignments.
- Robust evaluation science for LLM code review (Academia)
- Study correlations between precision, Outdated Rate, defect escape rates, and long-term maintainability; develop new metrics better aligned with real-world impact.
- Tools/Workflows: Longitudinal datasets; controlled experiments; cross-model comparisons; open benchmarks with reproducible pipelines.
- Assumptions/Dependencies: Access to anonymized repo histories; shared evaluation standards; institutional review for data use.
- Hybrid static analysis + LLM verification with formal methods (Software, Security)
- Combine static analysis proofs with LLM contextual reasoning; use ReviewFilter to mediate conflicting signals; escalate to formal verification for critical code.
- Tools/Workflows: Orchestration layer for multiple analyzers; rule-level fusion strategies; formal verification toolchain integration.
- Assumptions/Dependencies: Expertise in formal methods; performance headroom; calibrated false-positive trade-offs.
- SaaS platformization and marketplace ecosystem (Software)
- Build a multi-tenant service offering rule packs, dashboards, and integrations; third-party marketplace for domain rules and embeddings.
- Tools/Workflows: Tenant isolation; billing and quotas; plugin architecture; API/SDK for custom rules.
- Assumptions/Dependencies: Security and compliance; partner ecosystem; reliable inference at scale.
- Organizational change management and developer upskilling (Policy, Education)
- Use taxonomy-aligned feedback to educate developers; track improvement via Outdated Rate and precision; align incentives with quality metrics.
- Tools/Workflows: Training modules mapped to rules; career ladders tied to quality KPIs; feedback loops for team retrospectives.
- Assumptions/Dependencies: Leadership support; fair evaluation practices; avoidance of metric gaming; accessible learning resources.
Glossary
- Ablation study: An experiment that removes or disables components to assess their individual impact on system performance. Example: "Ablation Study for ReviewFilter."
- Alert fatigue: A phenomenon where users become desensitized to frequent alerts and start ignoring them. Example: "alert fatigue"
- Annotation feedback: Structured labels or reviewer inputs used to evaluate and improve model outputs. Example: "The generated review comments receive annotation feedback"
- Chain-of-Thought (CoT): A prompting and reasoning technique where models generate intermediate reasoning steps before answers. Example: "chains of thought (CoT)"
- Code diff: A representation of changes between two versions of code, typically used in reviews. Example: "Given a code diff"
- Conclusion-First: A reasoning pattern where the model outputs a decision token first, followed by rationale. Example: "Conclusion-First"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. Example: "cosine similarity"
- Cross-Site Request Forgery (CSRF): A web attack that tricks a user into submitting unwanted actions in a web application they’re authenticated to. Example: "Cross-Site Request Forgery (CSRF)"
- Cross-Site Scripting (XSS): A vulnerability that allows attackers to inject malicious scripts into trusted websites. Example: "Cross-Site Scripting (XSS)"
- Data flywheel: A feedback loop where deployed system data and user interactions continuously improve models and rules. Example: "data flywheel"
- Direct Conclusion: A reasoning pattern where the model outputs a yes/no decision without explicit reasoning. Example: "Direct Conclusion"
- Doubao-Pro-32K-0828: A ByteDance-developed LLM used as the base for fine-tuning in this system. Example: "Doubao-Pro-32K-0828"
- Embedding model: A model that converts text or code into numerical vectors for similarity or downstream tasks. Example: "embedding model, Doubbao-embedding-large"
- Filter rate: The proportion of candidate comments that a filter component rejects as erroneous. Example: "filter rate"
- Fine-tuned LLM: A pre-trained LLM further trained on task-specific data for improved performance. Example: "fine-tuned LLM"
- Hallucination: When a model produces outputs that are not supported by the input or facts. Example: "hallucination"
- Header hunk: A chunk in a diff that delineates a contiguous set of changed lines along with its metadata. Example: "header hunks"
- LGTM: An approval signal in code review meaning “Looks Good To Me.” Example: "``LGTM''"
- LLM-as-a-judge: An evaluation approach where an LLM assesses the correctness or quality of model outputs. Example: "LLM-as-a-judge methodology"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that trains low-rank adapters on top of frozen model weights. Example: "Low-Rank Adaptation (LoRA)"
- Merge Request (MR): A workflow artifact proposing to merge a set of code changes into a target branch. Example: "Merge Request (MR)"
- Outdated Rate: A metric measuring the percentage of flagged code lines that are later modified, indicating acceptance or impact. Example: "Outdated Rate"
- Reasoning-First: A reasoning pattern where the model provides its rationale before giving the final decision. Example: "Reasoning-First"
- ReviewFilter: A fine-tuned LLM component that validates and filters review comments to improve precision. Example: "ReviewFilter"
- RuleChecker: A fine-tuned LLM component that detects potential issues based on a taxonomy of review rules. Example: "RuleChecker"
- Static analysis: Automated examination of code without executing it to detect issues or enforce standards. Example: "static analysis"
- Taxonomy of review rules: A structured classification of review dimensions, categories, and rules that guide detection and evaluation. Example: "taxonomy of review rules"
- Tree-sitter: A parsing framework for generating syntax trees used to analyze and segment code. Example: "tree-sitter"
- WAU (Weekly Active Users): A product metric counting distinct users who are active within a given week. Example: "Weekly Active Users (WAU)"
Collections
Sign up for free to add this paper to one or more collections.