- The paper presents GSVC, which models video frames as sets of 2D Gaussian splats to enable explicit, controllable video representation and high-speed decoding.
- It leverages Gaussian Splat Pruning and Augmentation to optimize compression efficiency and adapt to dynamic content changes.
- Experimental results demonstrate competitive rate-distortion performance with over 1500 fps decoding on 1080p videos compared to state-of-the-art codecs.
GSVC: Efficient Video Representation and Compression Through 2D Gaussian Splatting
Introduction and Motivation
The paper introduces GSVC (GaussianVideo), a video representation and compression framework leveraging 2D Gaussian splatting as the core primitive. The motivation stems from the limitations of both traditional signal processing-based codecs (e.g., H.264/AVC, HEVC, VVC, AV1) and neural-based video compression methods. While neural codecs offer data-driven adaptability, they suffer from high computational cost and implicit representations that hinder direct manipulation and efficient decoding. GSVC aims to provide an explicit, compact, and efficient video representation that supports fast decoding, direct control over rate-distortion trade-offs, and adaptability to video dynamics.
2D Gaussian Splatting for Video Frames
GSVC models each video frame as a set of 2D Gaussian splats, where each splat is parameterized by its position, weighted color (including opacity), and a Cholesky vector encoding the covariance matrix. This explicit representation enables efficient rendering and direct manipulation of the splats. The number of splats per frame (N) serves as a rate control parameter, allowing fine-grained adjustment of compression quality and file size.




Figure 1: As the number of Gaussian splats N increases, the learned splats more accurately approximate the image content from the UVG Jockey video.
The training process iteratively optimizes the parameters of the splats to minimize the L2 loss between the original and reconstructed frames. Intermediate results demonstrate progressive fitting of image content as training iterations increase.



Figure 2: Optimization of Gaussian splat parameters over training iterations for 10,000 splats, illustrating convergence towards accurate frame reconstruction.
Temporal Redundancy and Frame Prediction
GSVC exploits temporal redundancy by categorizing frames into key-frames (I-frames) and predicted frames (P-frames). Key-frames are learned from scratch, while P-frames are initialized from the previous frame's splats and fine-tuned to fit the current frame. Only the parameter differences between consecutive frames are stored for P-frames, reducing redundancy and improving compression efficiency.
Gaussian Splat Pruning and Augmentation
To further control the rate-distortion trade-off, GSVC introduces Gaussian Splat Pruning (GSP), which removes splats with low contribution to frame quality. A learnable weight parameter wn quantifies each splat's importance, and splats with low ∣wn∣2 are pruned during training.


Figure 3: Distribution of Gaussian Splat Centers (45K) on f1 in Beauty, HoneyBee, and Jockey, showing concentration of splats in high-detail regions after pruning.
For dynamic content, GSVC employs Gaussian Splat Augmentation (GSA), adding new splats to P-frames to capture large deformations and newly appeared objects. This mechanism ensures that abrupt changes and high-motion regions are effectively represented.


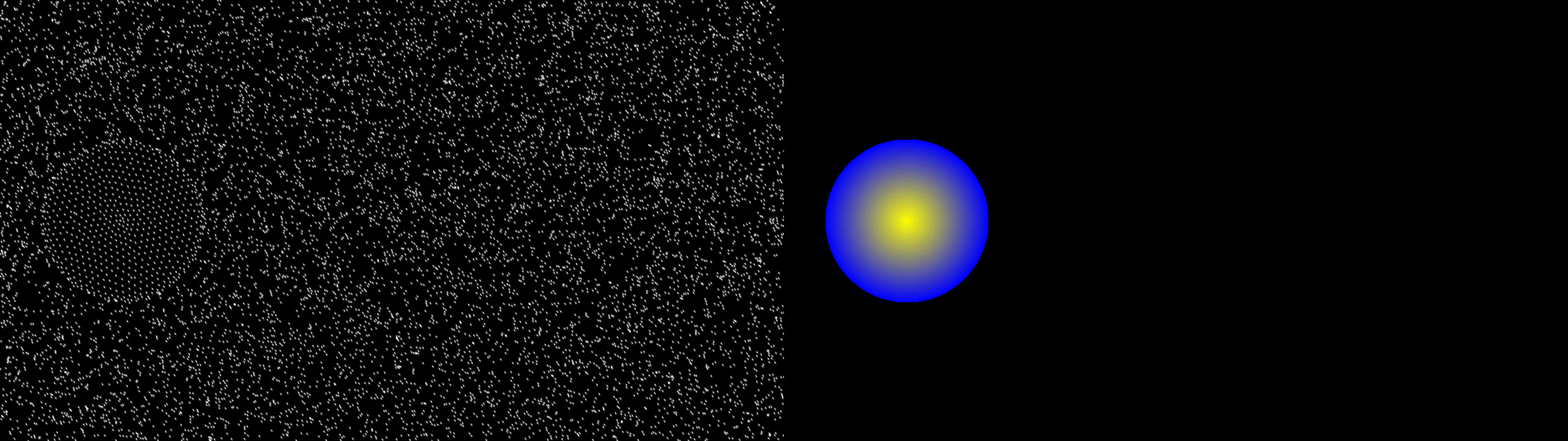

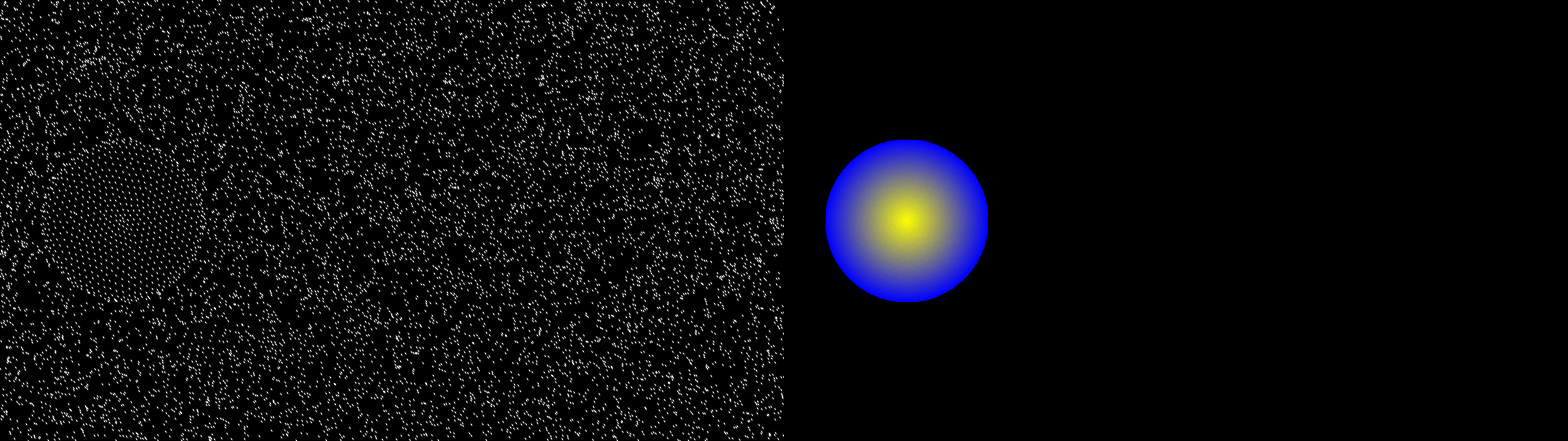

Figure 4: Distribution of Gaussian Splats (45K) on f5 in Beauty, demonstrating the impact of augmentation in capturing dynamic content.
Dynamic Key-frame Selection
Scene transitions and drastic changes between frames are detected using the Dynamic Key-frame Selector (DKS). DKS analyzes the loss difference between key-frame and P-frame pre-training, identifying outliers via a sliding window approach. Frames with loss differences exceeding the local mean by three standard deviations are classified as key-frames, ensuring efficient adaptation to scene changes.
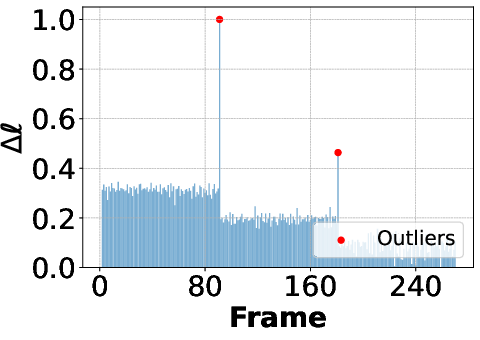
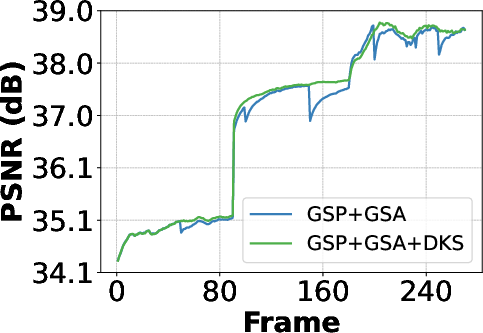
Figure 5: Δℓ loss difference and PSNR over frames, illustrating effective key-frame selection at scene transitions.
Encoding Strategy
GSVC encodes the learned splats using quantization-aware fine-tuning. For key-frames, splat parameters are quantized directly; for P-frames, only the quantized differences from the previous frame are stored. Position parameters use 16-bit float precision, Cholesky vectors employ b-bit asymmetric quantization, and weighted colors are encoded via multi-stage residual vector quantization. This approach ensures compact storage and efficient decoding.
Experimental Results
GSVC is evaluated on the UVG dataset (Beauty, HoneyBee, Jockey), using PSNR, MS-SSIM, and VMAF as metrics. The framework is implemented with CUDA-optimized rasterization and trained using the Adan optimizer. Key experimental findings include:
- Rate-Distortion Performance: GSVC achieves rate-distortion curves comparable to state-of-the-art codecs (AVC, HEVC, VVC, AV1) and neural compression methods (DCVC-HEM, DCVC-DC), particularly in MS-SSIM and VMAF. PSNR is slightly lower in some scenarios, but can be improved by tuning convergence criteria.
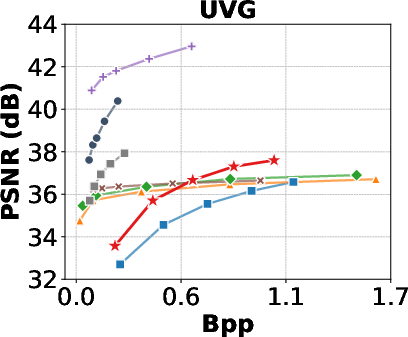
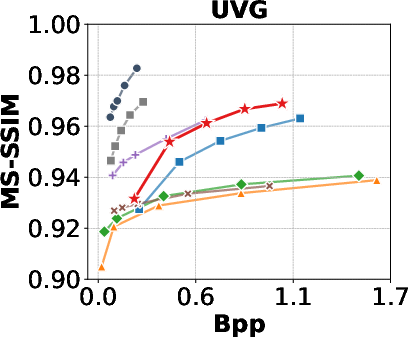
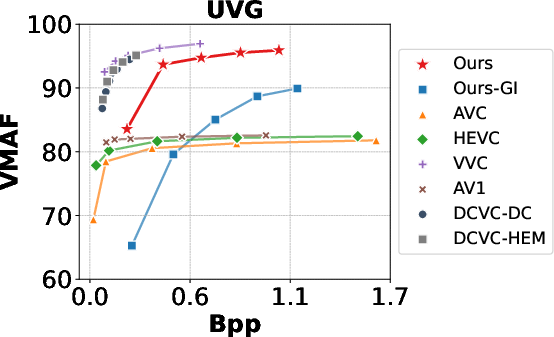
Figure 6: Rate-Distortion Curves in PSNR, MS-SSIM, and VMAF, comparing GSVC with baselines.
- Decoding Speed: GSVC decodes at 1500+ fps for 1920×1080 videos, vastly outperforming neural codecs (e.g., DCVC-DC at 2.4 fps).
- Model Size and Encoding Time: Encoding time per frame ranges from 197.58s to 221.45s as bpp increases, with model size directly controlled by N and quantization parameters.
Ablation Study
Ablation experiments demonstrate the contributions of each component:
- GSP yields the largest improvement in rate-distortion efficiency.
- GSA further enhances representation of dynamic content.
- DKS provides marginal gains in MS-SSIM, especially in videos with significant scene changes.
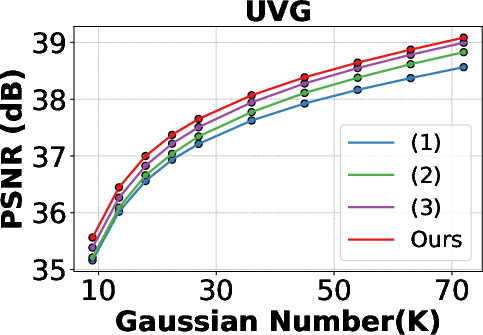
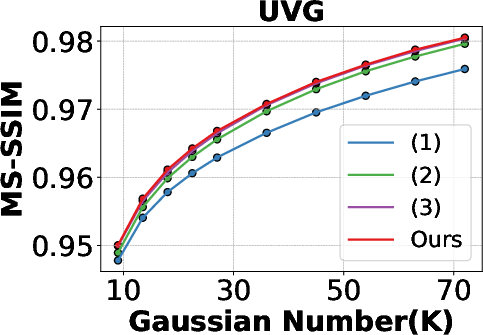
Figure 7: Ablation Study of PSNR and MS-SSIM over Gaussian Number on UVG dataset, highlighting the impact of GSP, GSA, and DKS.
Implications and Future Directions
GSVC establishes 2D Gaussian splatting as a viable explicit primitive for video representation and compression. The explicit nature of the representation allows direct control over compression parameters, supports fast decoding, and facilitates progressive coding and editing. The approach generalizes well to diverse video content without requiring pre-training, unlike neural codecs.
Potential future developments include:
- Integration of advanced compression techniques from 3DGS literature.
- Hyperparameter optimization for further rate-distortion improvements.
- Extension to bidirectional prediction and scalable encoding.
- Application to real-time streaming and interactive video editing.
Conclusion
GSVC demonstrates that 2D Gaussian splatting can serve as an efficient, explicit, and adaptable video representation for compression. The framework achieves competitive rate-distortion performance, supports high-speed decoding, and provides direct control over compression parameters. The results suggest that Gaussian splats are a promising alternative to both traditional and neural-based video codecs, with significant potential for further research and practical deployment in video processing systems.