- The paper proposes an LLM-powered simulator that integrates logical keyword matching with statistical models to accurately simulate user preferences.
- It employs structured pipelines and Chain-of-Thought techniques to extract both objective features and subjective insights for transparent simulation.
- Experimental results on diverse datasets show improved AUC and precision, validating the simulator’s enhanced performance over existing state-of-the-art methods.
LLM-Powered User Simulator for Recommender Systems
Abstract
The paper introduces a LLM-powered user simulator designed to enhance reinforcement learning-based recommender systems by simulating user engagement with high fidelity and transparency. This novel approach seeks to overcome existing challenges in user simulators, such as opacity in user preference modeling and difficulties in evaluating simulation accuracy. By leveraging LLMs, the proposed simulator captures both logical and statistical models of user interactions.
Introduction
The utility of RL-based recommender systems is enhanced by interactive environments that emulate user behaviors. However, the availability of online interaction data is limited by privacy concerns, costs, and collection difficulties. User simulators address these issues by providing adequate synthetic interaction data. Current simulators lack explicit user preference modeling and lack efficient evaluation mechanisms. The integration of LLMs into user simulators promises to fill these gaps by utilizing their broad knowledge and semantic capabilities. Although LLMs introduce challenges such as computational load and hallucinations, this paper proposes methods to mitigate these issues.
Methodology
User Interaction Logic
The simulation of user interactions is initiated by understanding two fundamental questions for a candidate item—what it is and how it aligns with the user's preferences. The paper details a pipeline (Figure 1), wherein LLMs analyze item characteristics and deduce user sentiments, providing insightful reasons for user inclinations.
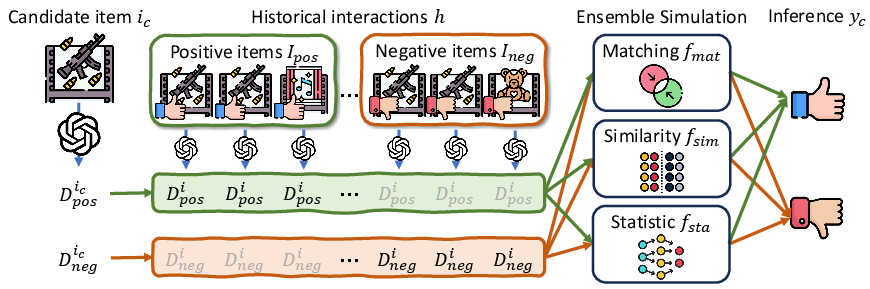
Figure 1: User interaction simulation pipeline using LLM-generated preference keywords.
Objective Item Description Collection
Objective item features, including possible pros and cons, are distilled using LLM prompts. A clear structure is provided to extract features based on data attributes such as genre, facilitating transparent inference.
Subjective Item Description Collection
Public feedback in the form of user comments is processed to obtain subjective insights. The integration of Chain-of-Thought techniques refines the reasoning, ensuring evidence-backed keyword extraction to represent user predispositions accurately.
Logical and Statistical Models
The proposed simulator embodies two logical models—keywords matching and similarity calculation models—that discern user preferences explicitly and are further complemented by a statistically driven model, such as SASRec, trained on historical data. This statistically driven aspect enhances the logical models' prediction robustness and consistency.
Ensemble Simulator Framework
Combining logical and statistical insights allows for a robust ensemble model that reflects user interactions. The ensemble approach ensures consistent implementation within RL frameworks by providing a structured MDP formulation to interact iteratively with the recommendation environment.
Experiments
Setup
Experiments were conducted across datasets spanning various content domains, including Yelp and Amazon, measuring the ensemble simulator against DQN, PPO, TRPO, and A2C algorithms. The simulator's ability to generate reliable interaction simulations was validated through a series of experiments focusing on both qualitative and quantitative metrics.
Results and Analysis
The new simulator shows promising results, outperforming existing state-of-the-art simulators, particularly in terms of AUC and inference precision, while maintaining reasonable computational efficiency. As shown in Table 1, it provides precise approximations of user preferences and captures the nuances of interaction sequences effectively.
Conclusion
The LLM-driven simulator brings forth a novel framework that systematically enhances the training of RL-based recommender systems by delivering transparent, evaluable, and reliable user interaction simulations. Future directions include extending its capabilities towards more complex interactions, incorporating more diverse feedback signals.
By integrating LLMs with statistical reasoning, this approach sets the stage for more realistic and nuanced simulations in RL systems beyond binary interactions, fostering advancements in adaptive and personalized recommendation strategies.