- The paper introduces an innovative approach that enhances unsupervised single-view 3D occupancy prediction by leveraging visual priors from foundation models.
- Its architecture features an inverse depth alignment module and SNOG sampler that improve depth consistency and spatial-temporal accuracy significantly.
- Experiments on KITTI datasets show improved scene occupancy accuracy and reduced depth errors, validating its applicability for autonomous driving.
ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction
Introduction
The paper "ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction" (2412.11210) addresses the challenging task of 3D occupancy prediction from a single image, a crucial component of vision-centric autonomous driving systems. Traditional methods rely on supervised learning techniques, demanding substantial 3D ground truth data. In contrast, ViPOcc introduces an innovative approach that utilizes visual priors from vision foundation models (VFMs) to enhance accuracy in unsupervised single-view 3D occupancy prediction.
Methodology
ViPOcc's architecture comprises two key branches: a depth estimation branch and a 3D occupancy prediction branch. The depth estimation branch employs an inverse depth alignment module, which addresses the discrepancies between VFM-generated depth predictions and ground truth data. This is necessary to correct the scale ambiguity often present in VFM predictions. By leveraging VFM outputs like those from Depth Anything V2, the method refines pseudodepth outputs to guide temporal photometric alignment, critical for ensuring spatial-temporal consistency in occupancy predictions.
A standout feature of ViPOcc is the semantic-guided non-overlapping Gaussian mixture (SNOG) sampler, which optimizes ray sampling efficiency. By integrating semantic priors from Grounded-SAM, the SNOG sampler focuses on crucial instances, avoiding redundant sampling and enhancing 3D scene reconstruction detail.
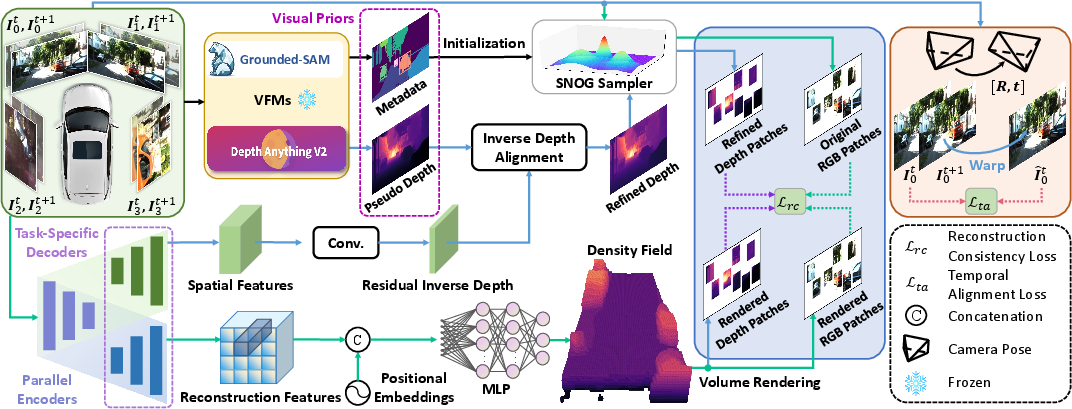
Figure 1: An illustration of our proposed ViPOcc framework. Unlike previous approaches that rely solely on NeRF for 3D scene reconstruction, ViPOcc introduces an additional depth prediction branch and an instance-aware SNOG sampler for temporal photometric alignment and spatial geometric alignment.
Experimental Results
The paper reports extensive experiments carried out on the KITTI-360 and KITTI Raw datasets, illustrating the superior performance of ViPOcc compared to existing state-of-the-art methods. The framework achieves a notable increase in scene occupancy accuracy (Oaccs) and invisible scene recall (IErecs), outperforming methods like BTS and KYN. Notably, ViPOcc achieves substantial accuracy improvements in reconstructing distant and occluded objects.
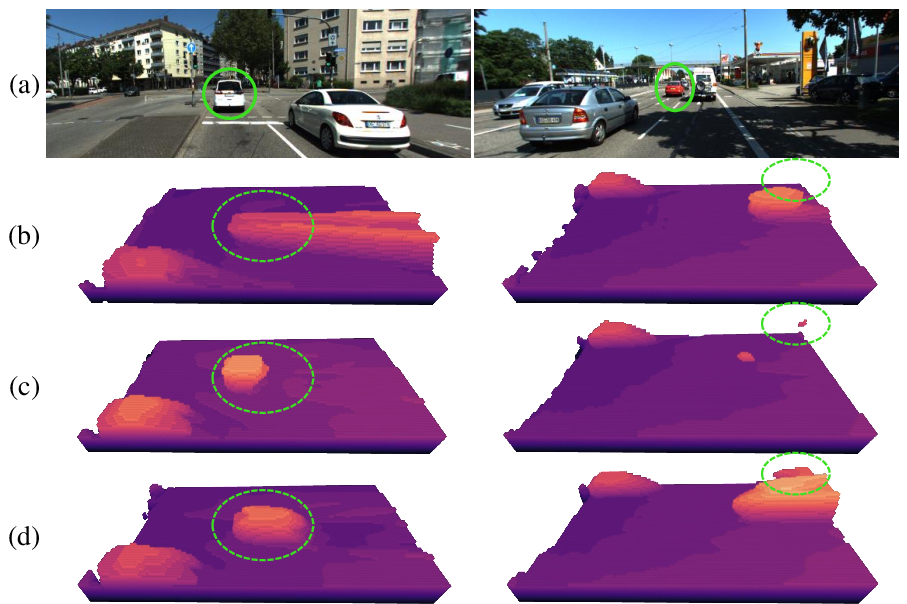
Figure 2: Qualitative comparison of 3D occupancy prediction on the KITTI-360 dataset: (a) input RGB images; (b) BTS results; (c) KYN results; (d) our results. A darker voxel color indicates a lower altitude.
Additionally, ViPOcc demonstrates significant advancements in metric depth estimation. It reduces mean absolute relative error (Abs Rel) by 5.8% on the KITTI-360 dataset, showcasing its efficacy in depth consistency and boundary preservation. These improvements can be traced back to the sophisticated inverse depth alignment and the integration of spatial-temporal consistency losses.
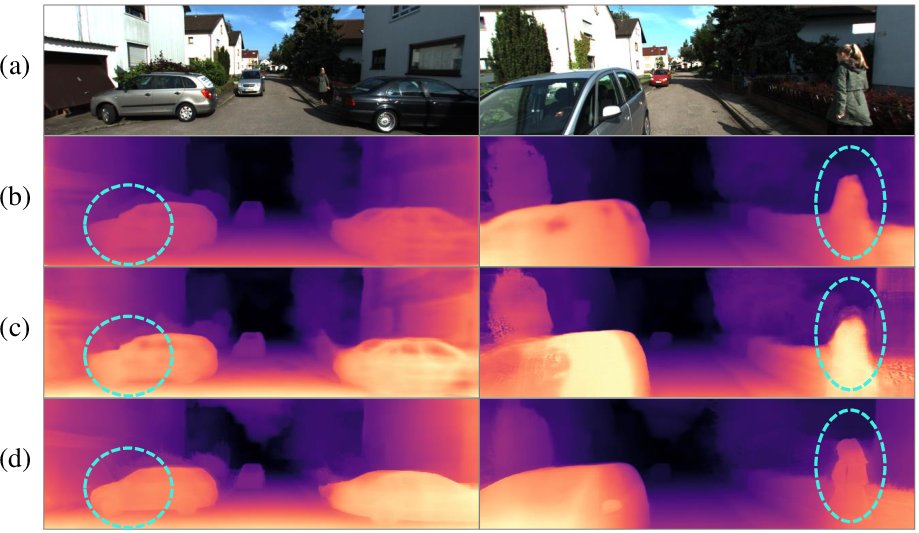
Figure 3: Comparison of metric depth estimation on the KITTI-360 dataset: (a) input RGB images; (b) BTS results; (c) KYN results; (d) our results.
Implications and Future Directions
The introduction of visual priors from VFMs represents a significant advancement in single-view 3D occupancy prediction. The ViPOcc framework efficiently bridges the gap between VFM predictions and real-world data, providing a robust solution for unsupervised depth estimation and 3D scene understanding. This research not only enhances autonomous vehicle environmental perception but also suggests broader applications for unsupervised learning techniques in other domains requiring fine-grained 3D reconstructions.
The paper hints at future explorations, such as tighter coupling between the depth estimation and occupancy prediction branches, and potential adaptations of the framework to accommodate real-time processing requirements in autonomous systems. As VFMs evolve, integrating their enriched semantic and spatial priors could further elevate the accuracy and efficiency of perception systems.
Conclusion
ViPOcc establishes a novel paradigm in the field of single-view 3D occupancy prediction. By strategically employing visual priors from VFMs, the framework circumvents the limitations of traditional methods, achieving superior accuracy and consistency in 3D reconstructions. It stands as a testament to the potential of leveraging foundational models to meet the complex demands of contemporary autonomous driving frameworks.