Task Singular Vectors: Reducing Task Interference in Model Merging
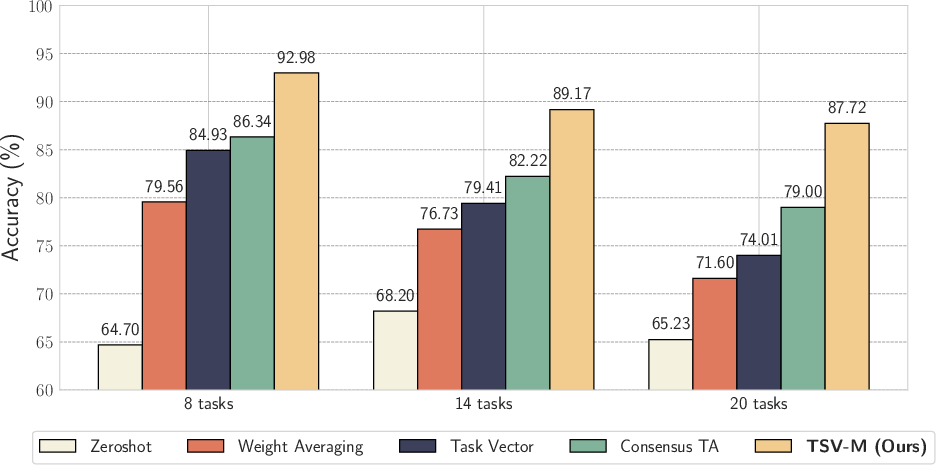
Abstract: Task Arithmetic has emerged as a simple yet effective method to merge models without additional training. However, by treating entire networks as flat parameter vectors, it overlooks key structural information and is susceptible to task interference. In this paper, we study task vectors at the layer level, focusing on task layer matrices and their singular value decomposition. In particular, we concentrate on the resulting singular vectors, which we refer to as Task Singular Vectors (TSV). Recognizing that layer task matrices are often low-rank, we propose TSV-Compress (TSV-C), a simple procedure that compresses them to 10% of their original size while retaining 99% of accuracy. We further leverage this low-rank space to define a new measure of task interference based on the interaction of singular vectors from different tasks. Building on these findings, we introduce TSV-Merge (TSV-M), a novel model merging approach that combines compression with interference reduction, significantly outperforming existing methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are either missing, uncertain, or left unexplored in the paper. Each point is phrased to be concrete and immediately actionable for future research.
- Generalization across modalities and architectures: The approach is only evaluated on CLIP ViT visual encoders and image classification tasks; its applicability to CNNs, detection/segmentation, audio, and NLP/LLM models remains unknown.
- Treatment of non-matrix parameters: How TSVs handle biases, LayerNorm parameters, embeddings, and positional encodings (where the paper “defaults to TA”) is not analyzed; the impact of mixing structured TSVs and flattened TA across layers is unexplored.
- Router requirement for TSV-C: Compression assumes known or inferred task identity; no experiments on router design, accuracy, latency/compute overhead, or robustness to misrouting are provided.
- Computational and memory cost: The per-layer SVD and Procrustes/whitening steps introduce nontrivial complexity; the paper lacks runtime, memory footprint, and scalability analyses for large models (e.g., ViT-G, LLMs) and many layers.
- Incremental updates: Procedures for adding new tasks without recomputing SVDs for previously stored TSVs (incremental/online merging and compression) are not specified or evaluated.
- Adaptive rank selection: The method uses a uniform per-task rank (≈1/T of layer dimensionality); criteria and algorithms to choose k per task and per layer (e.g., energy thresholds, optimal hard thresholds, noise-aware selection) are missing.
- Cross-task fairness vs T scaling: As the number of tasks grows, each task’s rank budget shrinks; the accuracy–storage–fairness trade-off and performance degradation beyond 20 tasks are not characterized.
- Singular value scaling bias: The paper notes Σ magnitudes may bias merging but keeps Σ unchanged; strategies to normalize, reweight, or temper singular values across tasks (and layers) are not explored.
- STI theory: While STI correlates empirically with accuracy, there are no theoretical guarantees or bounds linking STI reduction to performance gains across layers or tasks.
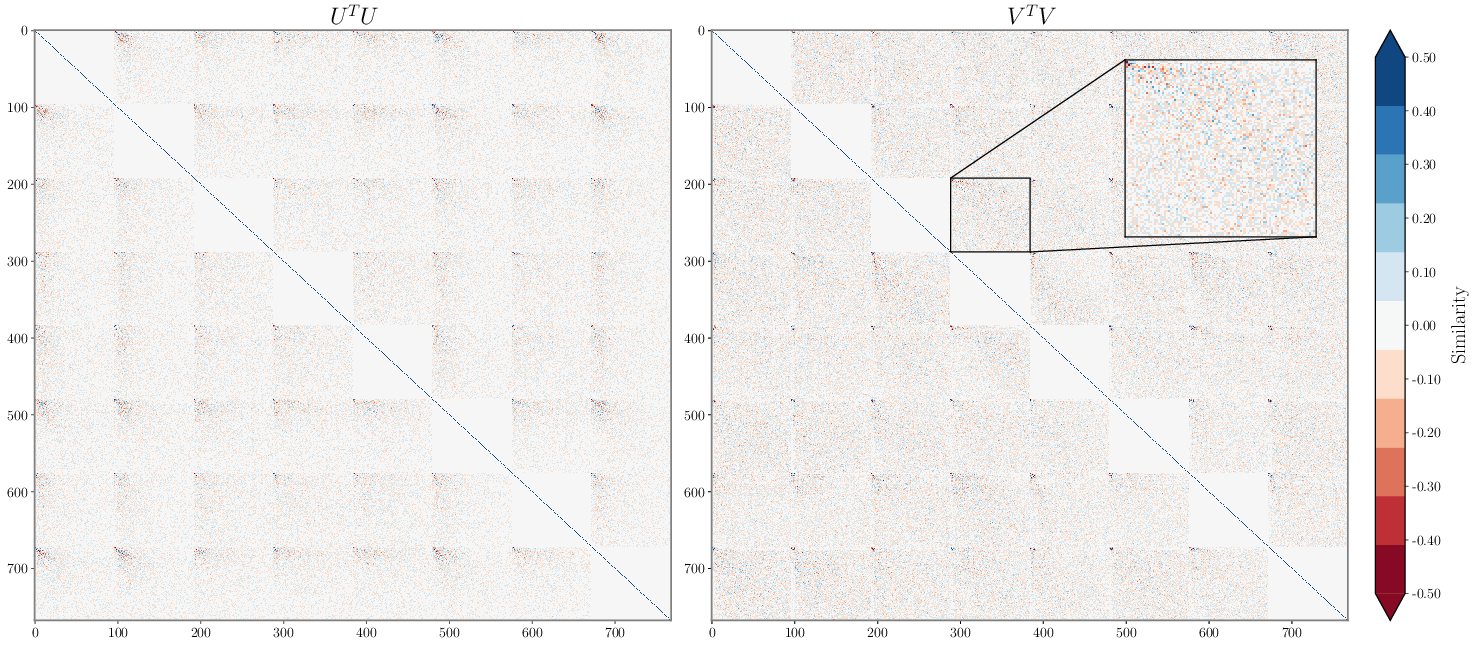
- STI metric design: The choice of L1 norm and concatenation-based similarity is not justified against alternatives (e.g., principal angles, CCA, subspace distance); normalization for dimensionality and task count is missing.
- Preserving positive transfer: Whitening removes inter-task correlations that could be beneficial; criteria to distinguish harmful from helpful overlap and selective decorrelation strategies are not proposed.
- Per-layer strategies: Using STI to decide which layers to decorrelate, freeze, skip, or assign different ranks is not investigated; the one-size-fits-all approach may be suboptimal.
- α scaling policy: Although α=1.0 works empirically on selected setups, per-layer or per-task α, data-free tuning strategies, or theoretical guidance for α selection are not studied.
- Numerical stability: Whitening/Procrustes on rank-deficient or ill-conditioned matrices may be unstable; regularization, conditioning, and error-control strategies (and their impact on accuracy) are not examined.
- Merging across different bases: The method assumes all tasks are fine-tuned from the same pretrained base; merging models from different bases, checkpoints, or architectures (with potential permutation misalignment) is not addressed.
- Baseline coverage: Key merging baselines (e.g., Fisher Merging, RegMean, TIES, DARE) are missing from the main merging results; comparisons to PEFT-based merging (e.g., LoRA adapters) are absent.
- Robustness and calibration: Effects on robustness (corruptions, adversarial), calibration, uncertainty, OOD generalization, and fairness across tasks are not evaluated.
- Inference efficiency: The impact of TSV-M on inference latency, memory usage, and deployment constraints versus TA, Model Soups, and MoE is not measured.
- Compatibility with compression/quantization: Interactions with quantization, pruning, distillation, and PEFT (e.g., directly merging LoRA adapters via TSVs) are not explored.
- Task forgetting: The framework’s ability to support targeted forgetting (akin to negating task vectors in TA) post-whitening is not studied.
- Sensitivity to fine-tuning recipes: Effects of optimizer choice, seeds, regularization, and re-basin/permutation mismatches on TSVs and STI are unknown.
- Variance and reproducibility: The paper lacks error bars and sensitivity analyses across runs; stability under approximate/truncated SVD or randomized methods is not reported.
- Storage accounting and limits: Claims of “~2× base model storage” for TSV-C lack a detailed breakdown; how storage scales in practice when T increases (and k shrinks) and under different layer shapes is unclear.
- Layer types beyond linear: Adaptations of TSV to convolutional/tensor layers (e.g., CP/Tucker decompositions) and empirical validation are missing.
- STI for routing/selection: Using STI to predict conflicts and guide dynamic routing, selective activation, or task-aware layer choices is not investigated.
- Privacy and security: Potential leakage of task-specific information via stored singular vectors and privacy-preserving merging strategies are not discussed.
Collections
Sign up for free to add this paper to one or more collections.