- The paper introduces MITA-YOLO, which employs mirror-based indirect vision to extend camera coverage without intrusive installations.
- The paper presents a Target-Mask module that filters non-target areas, improving detection accuracy with a 3.7% increase in mAP50 and a 3% recall boost.
- The experiments demonstrate superior performance over existing YOLO models, reducing false alarms and preserving the structural integrity of heritage sites.
Mirror Target YOLO: An Improved YOLOv8 Method with Indirect Vision for Heritage Buildings Fire Detection
Introduction
The paper introduces Mirror Target YOLO (MITA-YOLO), a novel fire detection method specifically designed for heritage buildings. Traditional fire detection mechanisms often require intrusive installations that can damage the historical fabric of these buildings. In response, MITA-YOLO utilizes indirect vision through strategically placed mirrors to enhance the field of view and minimize the need for numerous cameras, thus preserving the integrity of such structures.
Indirect Vision Deployment
MITA-YOLO employs indirect vision by leveraging mirrors to extend the coverage area of cameras without additional infrastructure. The technique involves aligning mirrors to reflect target monitoring areas only, excluding non-interest regions such as ceilings made from non-combustible materials. This strategic placement reduces the operational need for cabling and excessive camera installation, mitigating the risk of structural damage.
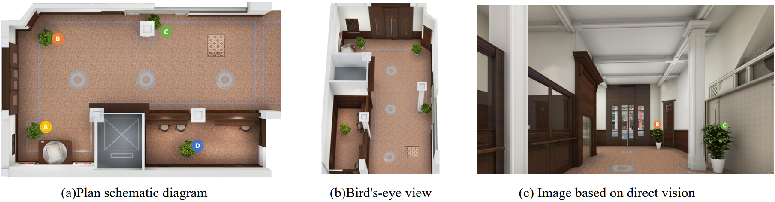
Figure 1: When the camera is deployed at a position directly facing the gate and only direct vision is used, due to the irregular shape of the indoor space, the direct vision of the camera is blocked. Among the four plants placed in this space, only two can be observed, and two plants are invisible in the occluded area.

Figure 2: After the mirrors were deployed, the corresponding target areas could be seen through indirect vision in the mirrors, realizing the expansion of the camera's field of vision coverage and the alignment of the indirect vision and the target detection area.
Target-Mask Module
To further enhance fire detection accuracy and robustness against noise, MITA-YOLO integrates a Target-Mask module within the YOLOv8 architecture. This module is crucial for filtering out irrelevant visual information, focusing only on indirect vision areas. It functions through three sub-modules: the Indirect Vision Recognizer (IVR), Targeted Mask Generator (TMG), and Mask Blender (MB). These work in tandem to identify indirect vision fields, generate masks, and apply them to the captured images to ensure only target areas are processed.
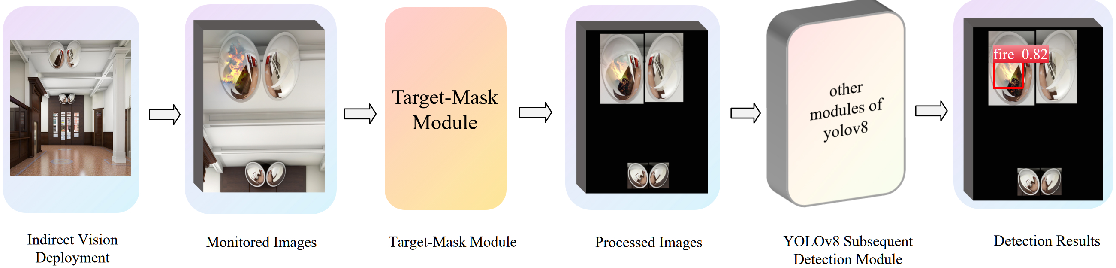
Figure 3: First, deploy the mirror system in the irregular space. Then, input the detection images obtained by the camera into the improved detection model. After the original images pass through the Target-Mask module, only the indirect vision area is retained. The processed images are then pushed into the subsequent modules of the detection model. Finally, the results of targeted detection only for the indirect vision area are obtained.
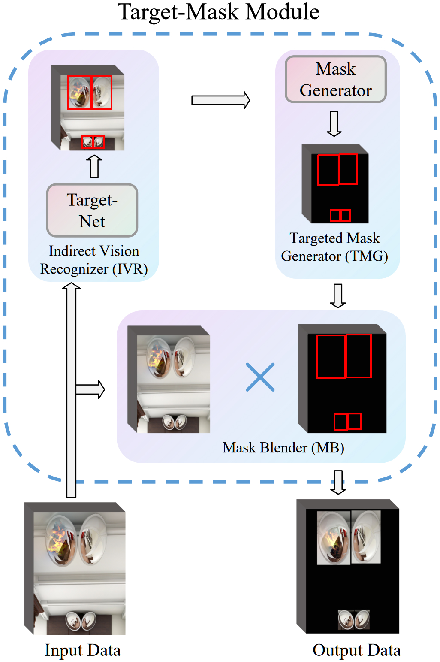
Figure 4: The Target-Mask is added to the neck between the data input and the backbone network of YOLOv8. When the image data passes through the Target-Mask module, the module will use the built-in network to find the area location information of each indirect vision in the image, and then use the obtained location information to generate a mask with corresponding area boundary information. Then, the mask is mapped back to the original image. After the mapping processing, the passed image only retains the pixels of the target area and filters out other non-interest areas. Then, the optimized image data is sent to the subsequent network of YOLOv8.
Experiment and Results
The authors conducted experiments using a dataset created from a 3D mock-up of a heritage site to validate MITA-YOLO. The results indicate significant improvements over state-of-the-art models. Specifically, MITA-YOLO achieved a 3.7% increase in mAP50 and a 3% improvement in recall rate, highlighting its effectiveness in fire detection tasks with reduced false alarms.

Figure 5: Example of experimental data.
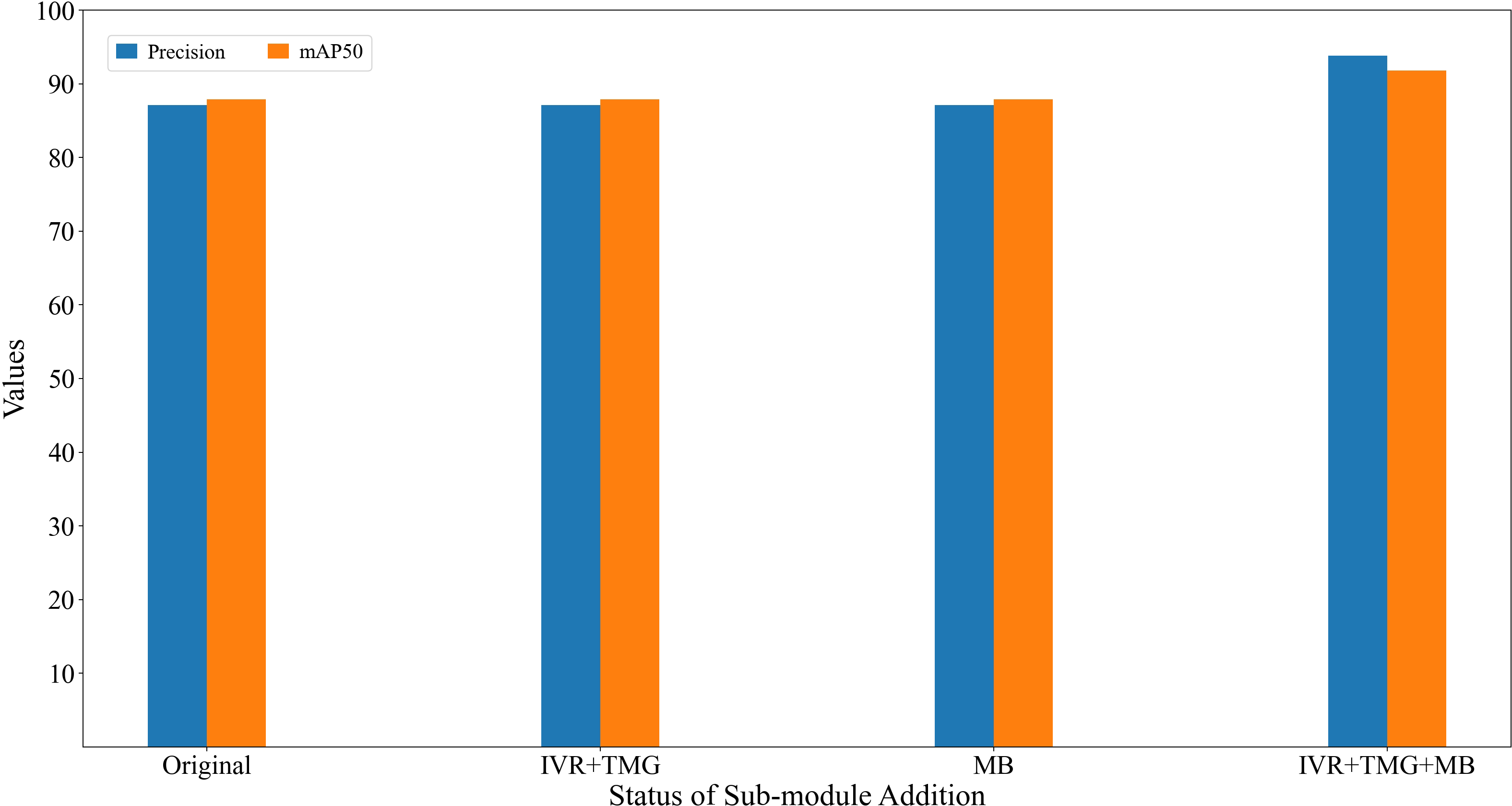
Figure 6: Results of ablation experiment.
When compared with competing models such as YOLOv8n, YOLOv9-Tiny, and others, MITA-YOLO demonstrated superior performance metrics—particularly precision and recall—affirming its utility in scenarios limited by physical and structural constraints.
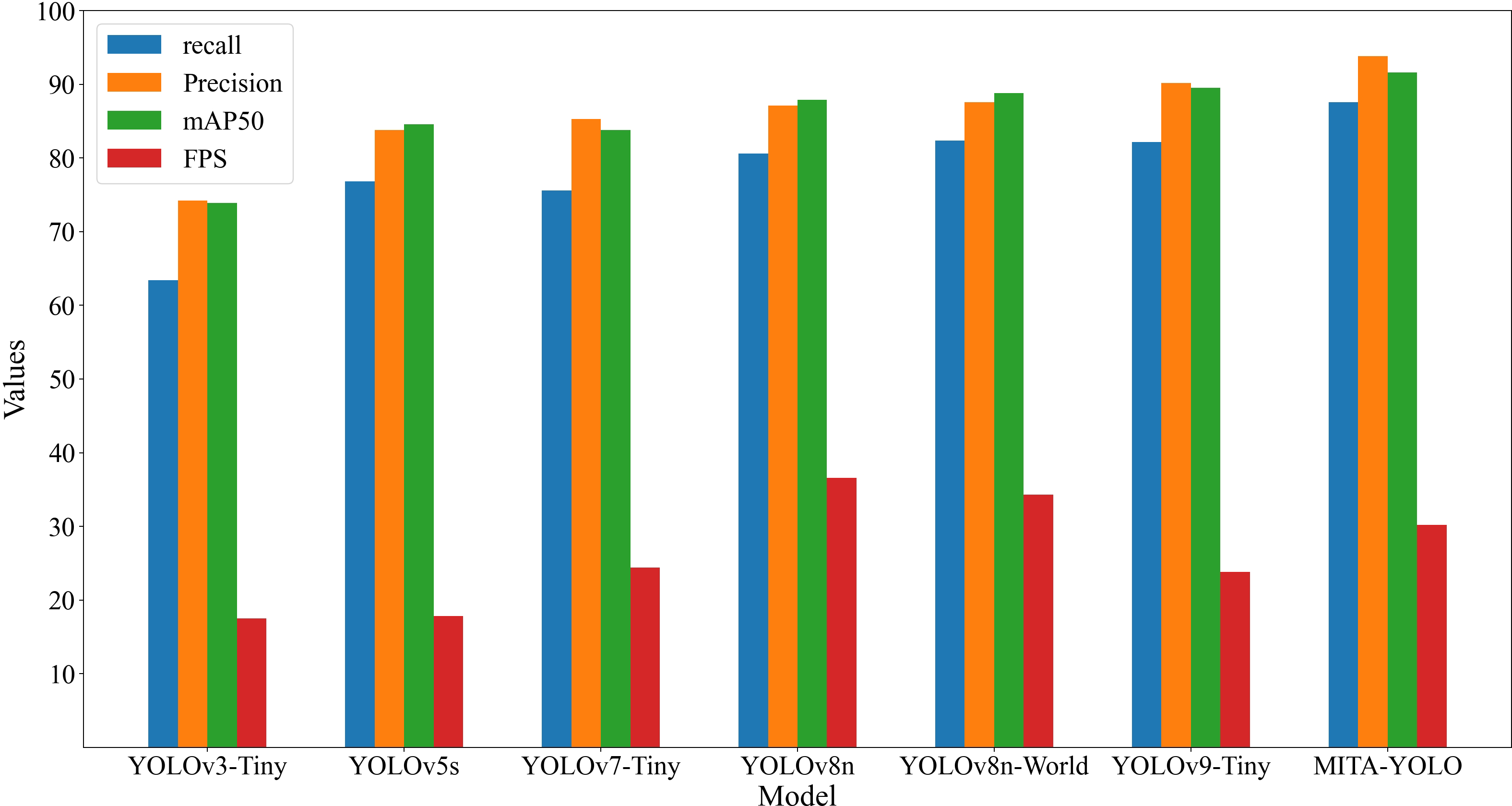
Figure 7: Results of comparative experiments.

Figure 8: Comparison of detection results between YOLOv8n and MITA-YOLO.
Conclusion
MITA-YOLO presents a sophisticated approach to fire detection in heritage buildings that respects the structural and aesthetic integrity of such sites. By innovatively integrating indirect vision and a specialized detection module, MITA-YOLO effectively minimizes the need for camera redundancy and intrusive infrastructure. Future enhancements could focus on expanding its applicability to diverse architectural layouts and further refining its responsiveness to environmental changes, pushing the boundaries of this technique in various computer vision tasks.