DASH: Warm-Starting Neural Network Training in Stationary Settings without Loss of Plasticity
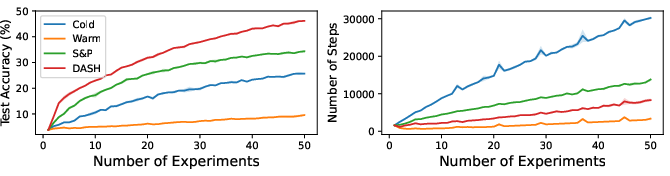
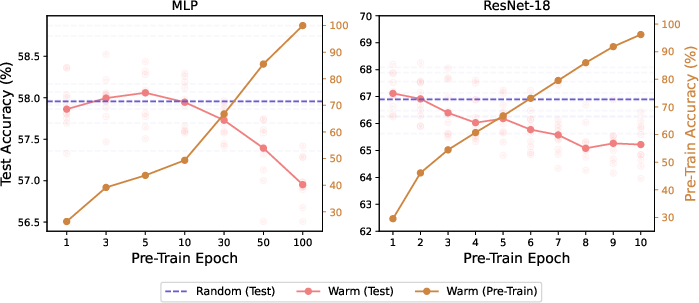
Abstract: Warm-starting neural network training by initializing networks with previously learned weights is appealing, as practical neural networks are often deployed under a continuous influx of new data. However, it often leads to loss of plasticity, where the network loses its ability to learn new information, resulting in worse generalization than training from scratch. This occurs even under stationary data distributions, and its underlying mechanism is poorly understood. We develop a framework emulating real-world neural network training and identify noise memorization as the primary cause of plasticity loss when warm-starting on stationary data. Motivated by this, we propose Direction-Aware SHrinking (DASH), a method aiming to mitigate plasticity loss by selectively forgetting memorized noise while preserving learned features. We validate our approach on vision tasks, demonstrating improvements in test accuracy and training efficiency.
- Critical learning periods in deep networks. In International Conference on Learning Representations, 2018.
- Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. arXiv preprint arXiv:2012.09816, 2020.
- A closer look at memorization in deep networks. In International conference on machine learning, pages 233–242. PMLR, 2017.
- On warm-starting neural network training. Advances in neural information processing systems, 33:3884–3894, 2020.
- Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- A study on the plasticity of neural networks. arXiv preprint arXiv:2106.00042, 2021.
- Benign overfitting in two-layer convolutional neural networks. Advances in neural information processing systems, 35:25237–25250, 2022.
- Improving language plasticity via pretraining with active forgetting. Advances in Neural Information Processing Systems, 36:31543–31557, 2023.
- Robust learning with progressive data expansion against spurious correlation. Advances in Neural Information Processing Systems, 36, 2023.
- Continual backprop: Stochastic gradient descent with persistent randomness. arXiv preprint arXiv:2108.06325, 2021.
- Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412, 2020.
- The early phase of neural network training. arXiv preprint arXiv:2002.10365, 2020.
- Transient non-stationarity and generalisation in deep reinforcement learning. arXiv preprint arXiv:2006.05826, 2020.
- Towards understanding how momentum improves generalization in deep learning. In International Conference on Machine Learning, pages 9965–10040. PMLR, 2022.
- On the joint interaction of models, data, and features. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ze7DOLi394.
- Characterizing structural regularities of labeled data in overparameterized models. arXiv preprint arXiv:2002.03206, 2020.
- Critical learning periods emerge even in deep linear networks. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Aq35gl2c1k.
- Maintaining plasticity via regenerative regularization. arXiv preprint arXiv:2308.11958, 2023.
- Plastic: Improving input and label plasticity for sample efficient reinforcement learning. Advances in Neural Information Processing Systems, 36, 2023.
- Curvature explains loss of plasticity. arXiv preprint arXiv:2312.00246, 2023.
- Bad global minima exist and sgd can reach them. Advances in Neural Information Processing Systems, 33:8543–8552, 2020.
- Towards perpetually trainable neural networks, 2023a.
- Understanding plasticity in neural networks. In International Conference on Machine Learning, pages 23190–23211. PMLR, 2023b.
- Deep double descent: Where bigger models and more data hurt. Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003, 2021.
- The primacy bias in deep reinforcement learning. In International conference on machine learning, pages 16828–16847. PMLR, 2022.
- Deep reinforcement learning with plasticity injection. Advances in Neural Information Processing Systems, 36, 2023.
- Provable benefit of cutout and cutmix for feature learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=8on9dIUh5v.
- Understanding and improving convolutional neural networks via concatenated rectified linear units. In international conference on machine learning, pages 2217–2225. PMLR, 2016.
- Data augmentation as feature manipulation. In International conference on machine learning, pages 19773–19808. PMLR, 2022.
- The dormant neuron phenomenon in deep reinforcement learning. In International Conference on Machine Learning, pages 32145–32168. PMLR, 2023.
- Pretrained language model in continual learning: A comparative study. In International conference on learning representations, 2021.
- The benefits of mixup for feature learning. arXiv preprint arXiv:2303.08433, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.