- The paper introduces VIBES as a framework that efficiently identifies optimal pre-trained vision backbones tailored to specific computer vision tasks.
- It presents fast approximate evaluation methods, including dataset subsampling and feature space class coherence, to reduce computation time.
- Experimental results demonstrate that VIBES strategies can outperform general-purpose benchmarks within a short search time under varied dataset conditions.
Vision Backbone Efficient Selection
The paper "VIBES -- Vision Backbone Efficient Selection" (2410.08592) addresses the problem of efficiently selecting the best pre-trained vision backbone for a given computer vision task and dataset. Instead of relying on generic benchmark results, the paper advocates for dataset-specific solutions, framing backbone selection as an optimization problem. The authors introduce Vision Backbone Efficient Selection (VIBES) as a practical approach to balance performance and computational cost, providing a framework and heuristics for efficient backbone selection.
The paper formalizes the vision backbone selection problem, defining it as finding the optimal backbone b∗ from a set of N pre-trained backbones B={b1,...,bN} that maximizes the evaluation metric ϵ(b) on a target task T. The evaluation metric represents the performance of a backbone b when fine-tuned on the training dataset Dtrain and evaluated on the test dataset Dtest. The objective is to find b∗ such that:
b∗=b∈Bargmaxϵ(b).
An exhaustive search guarantees optimality but quickly becomes impractical due to the computational cost, which is expressed as:
t=∑b∈Bτ(b),
where τ(b) is the time needed to fine-tune and evaluate backbone b. To address this, the authors propose VIBES, which aims to quickly find a high-performing backbone, potentially sacrificing optimality for speed. VIBES reduces the total search time by either reducing τ(b) using fast approximate evaluation strategies or reducing the size of B using optimized sampling strategies.
Efficient Selection Strategies
The paper outlines two main families of strategies to make the backbone selection process more efficient: fast approximate evaluation and optimized sampling.
Fast approximate evaluation aims to reduce the evaluation time τ(b) by computing an approximation of the performance of b, noted as ϵ~(b). Two approaches are explored:
- Dataset Subsampling: Using only a fraction of the dataset for fine-tuning and testing. This reduces evaluation time but may lead to less reliable performance estimates.
- Measuring class coherence in the feature space: Evaluating backbone performance by measuring class separation in feature space without fine-tuning. The silhouette score is used to quantify class coherence, with higher values indicating better separation between classes.
Optimized sampling aims to reduce the search space by using only a subset of B. A sampling function π generates a permutation of {1,...,N}, and the ordered set is denoted as π(B)={bπ(1),…,bπ(N)}. Several sampling strategies are explored:
- Random: The sampling order is a random permutation of {1,...,N}.
- Increasing model complexity: Testing smaller backbones first, assuming they are faster to fine-tune and evaluate.
- Decreasing model complexity: Testing larger models first, assuming they often perform better.
- Decreasing dataset size: Testing backbones pre-trained on the largest datasets first, hypothesizing that more pre-training data leads to better performance.
- Dataset cycling: Alternating backbones corresponding to different pre-training datasets, aiming to maximize the chances of finding a well-suited backbone for the task.
To rigorously assess and compare VIBES strategies, the authors introduce Backbone Selection Efficiency Curves (BSEC), which plot the true evaluation metric ϵ(b^) as a function of the time budget tmax. The BSEC provides insights into the speed of improvement, long-term performance potential, and reliability of different strategies.
Experimental Results
The paper presents a series of experiments on four diverse datasets: CIFAR10, GTSRB, Flowers102, and EuroSAT. The experiments compare the proposed VIBES strategies against a baseline ConvNeXt-Base model pre-trained on ImageNet-22K, which was identified as a strong general-purpose backbone in previous benchmark studies. The key findings are:
- Simple VIBES strategies can outperform general-purpose benchmarks within one hour of search time.
- Using the full dataset is more efficient for long search times, while dataset subsampling enhances performance for shorter time budgets on CIFAR10 and GTSRB. Subsampling showed a negative effect on EuroSAT.
- Measuring class coherence in the feature space using the silhouette score leads to faster convergence for Flowers102 but underperforms for the other datasets.
- Sampling strategies based on model complexity consistently underperform compared to random sampling.
- Sampling methods based on pre-training datasets (dataset cycling and decreasing dataset size) outperform random sampling for GTSRB, CIFAR10, and Flowers102.
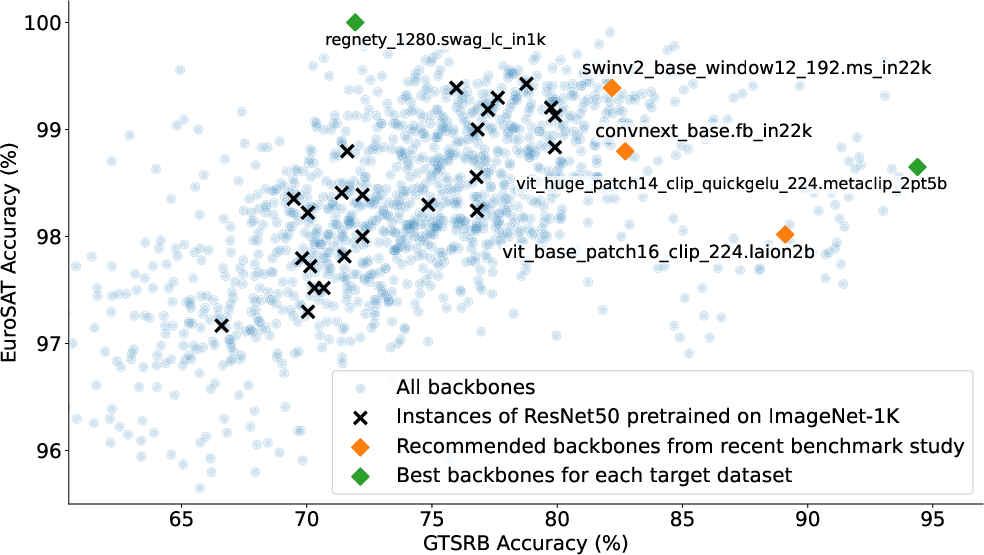
Figure 1: Performance comparison of pretrained vision backbones on GTSRB and EuroSAT datasets. Each point represents a backbone from the PyTorch Image Models (timm) library. Accuracies are obtained by training a shallow classifier (one hidden layer with 50 neurons) on top of frozen backbone features. Recommended backbones are from~\cite{goldblum2024battle}.
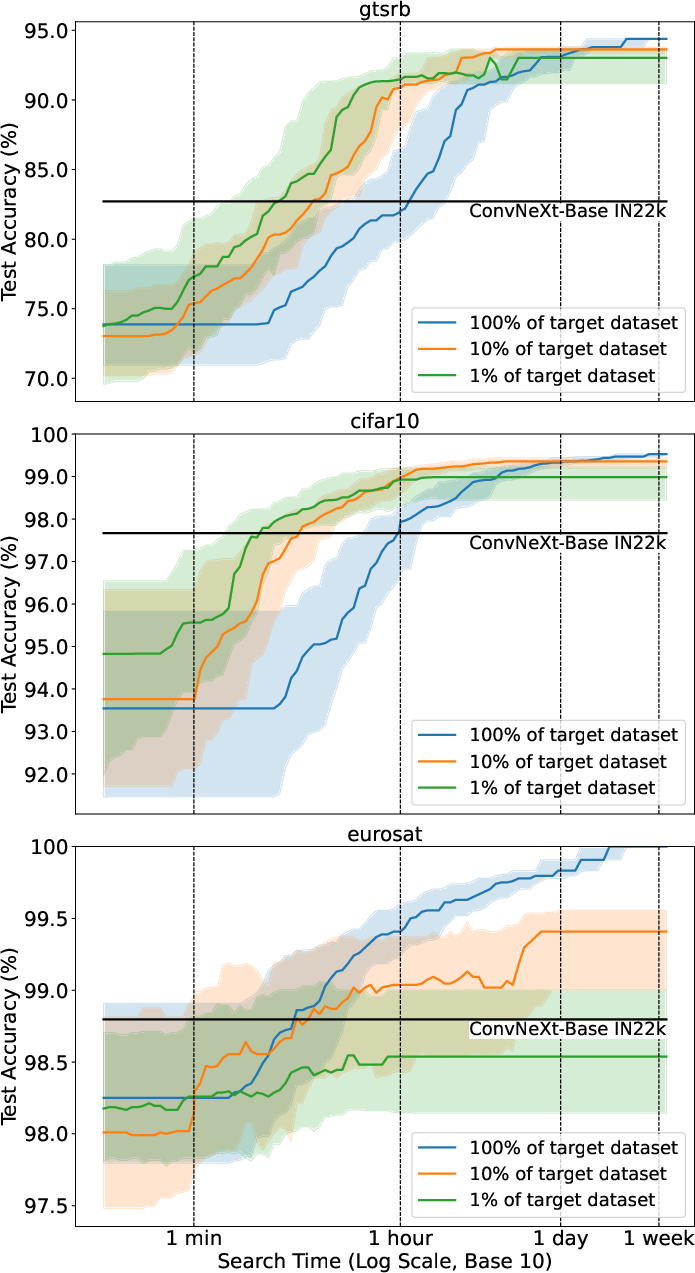
Figure 2: Dataset Subsampling. This figure compares Backbone Selection Efficiency Curves (BSEC) for different subsampling fractions of the training dataset (Section~\ref{sec:fraction}).
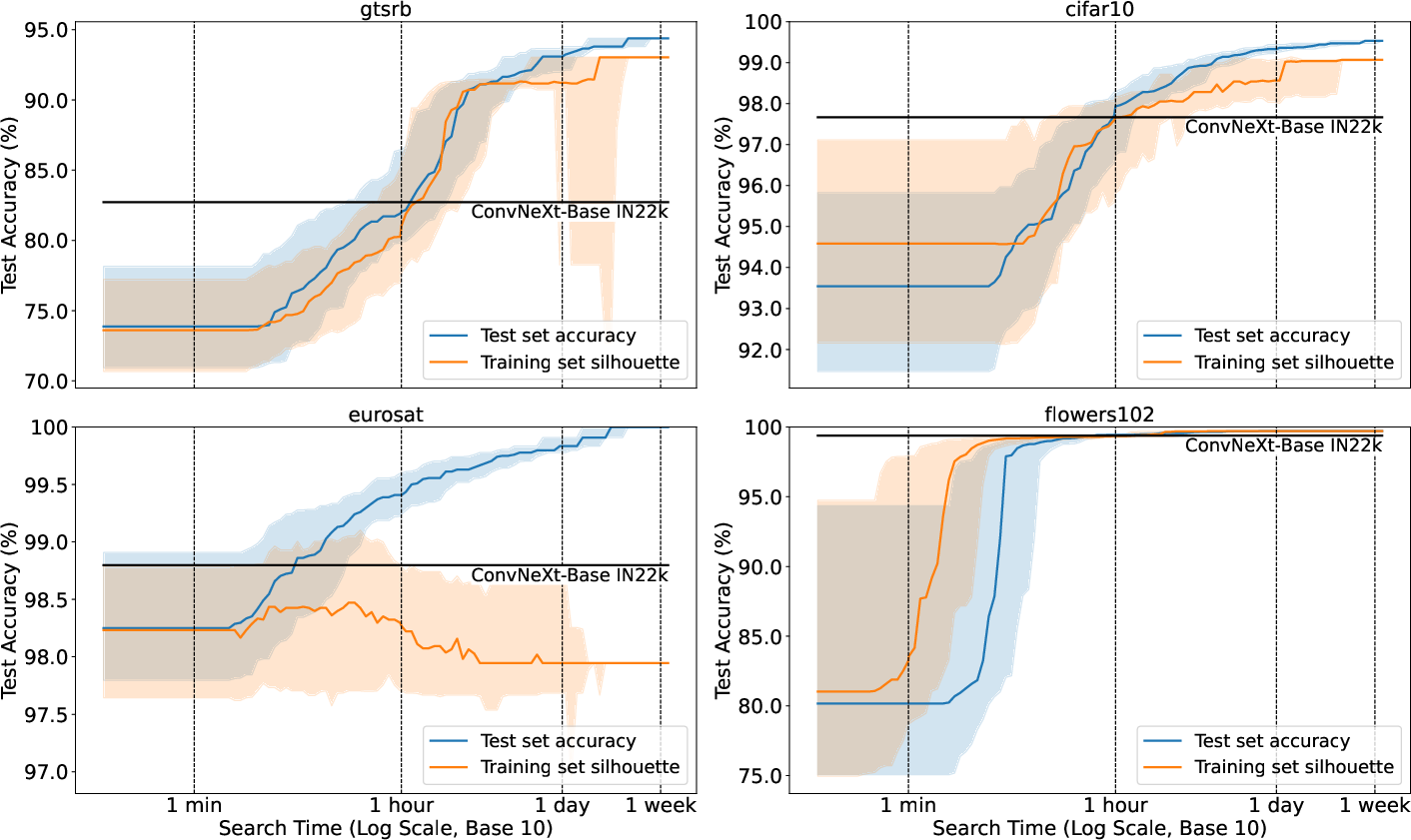
Figure 3: Feature Space Class Coherence. This figure compares BSECs using the silhouette score in feature space against the traditional fine-tuning and evaluation approach (Section~\ref{sec:silhouette}).
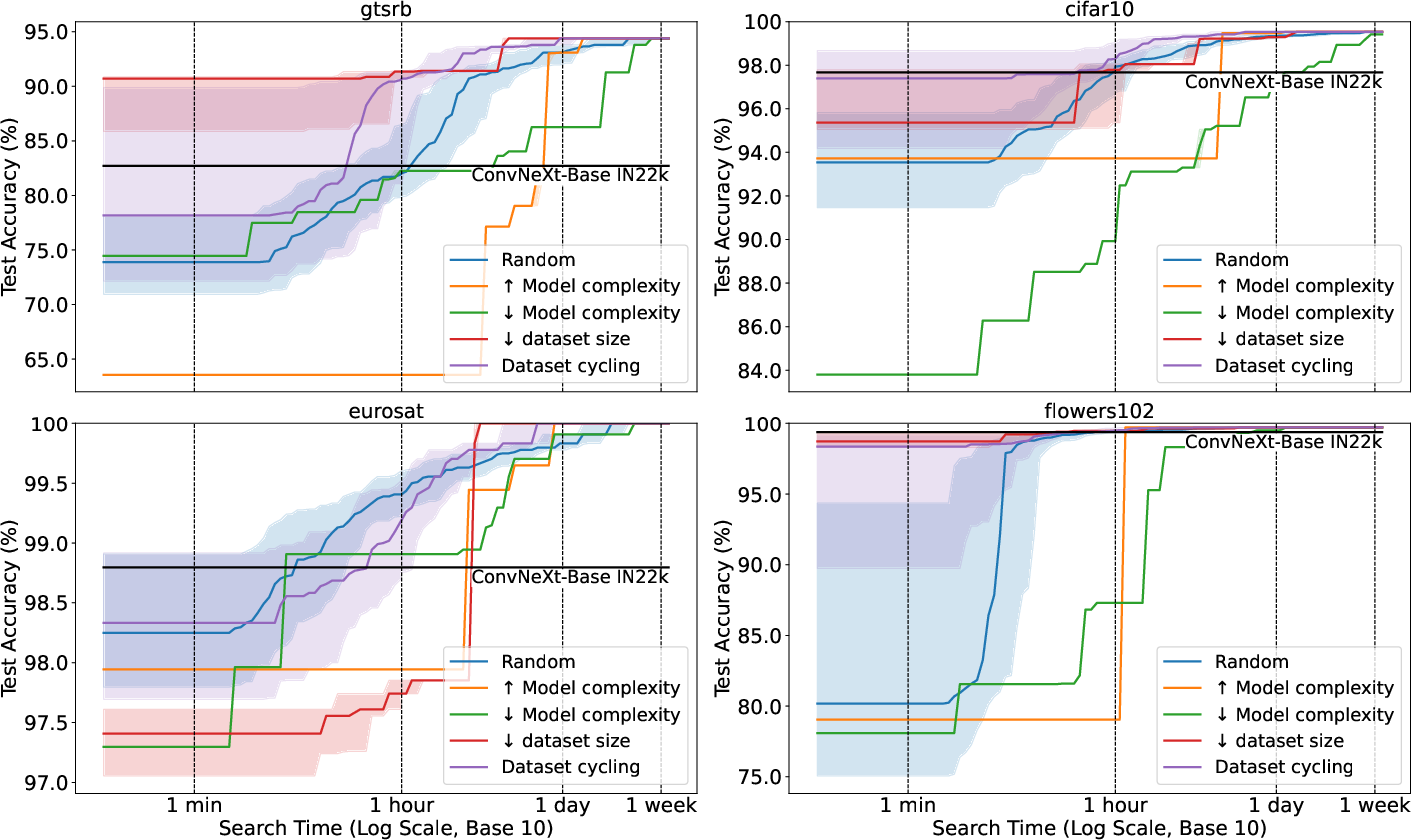
Figure 4: Optimized Sampling. This figure compares different backbone sampling strategies (Section~\ref{sec:model_sampling_approx}).
The experimental results demonstrate the benefits of task-specific backbone selection and highlight the context-dependent effectiveness of different VIBES approaches. The choice of the optimal strategy depends on the available time budget and the characteristics of the target dataset. For example, evaluating subsets of large datasets is efficient under tight time constraints, while cycling through pre-training datasets is a robust sampling strategy.
Conclusion
The paper "VIBES -- Vision Backbone Efficient Selection" (2410.08592) formalizes the problem of efficient vision backbone selection and provides a preliminary exploration of potential solutions. The experimental results show that simple VIBES approaches can outperform general-purpose benchmarks within a short search time, highlighting the importance of task-specific optimization. Future research directions include conducting comprehensive experiments to delineate the strengths and limitations of the proposed strategies and developing more versatile approaches by combining approximate evaluation with optimized sampling and meta-learning techniques. The codebase released with the paper provides practitioners with a tool for backbone search, promoting broader application and innovation in computer vision tasks.