Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
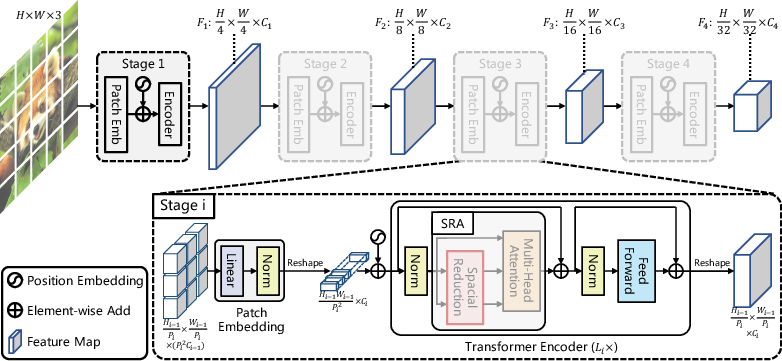
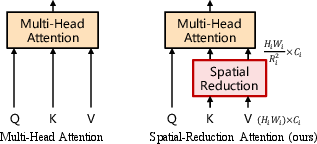
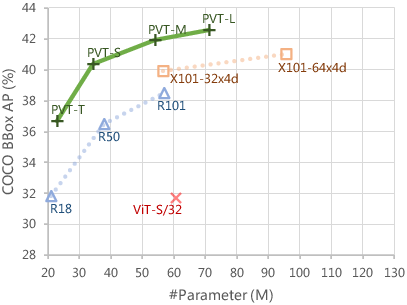
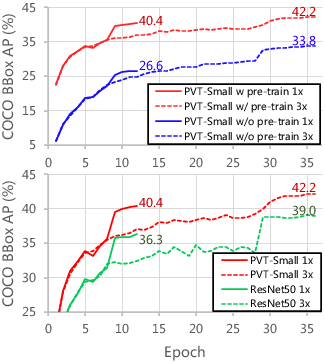
Abstract: Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at https://github.com/whai362/PVT.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.