- The paper introduces a novel FedBSD framework that splits client models into a shared backbone for global knowledge and a private head for personalization.
- The proposed self-distillation strategy uses the global backbone as a teacher to enhance local model representations under heterogeneous data conditions.
- Experiments on datasets like CIFAR and FEMNIST show that FedBSD outperforms conventional methods with faster convergence and improved accuracy.
Personalized Federated Learning via Backbone Self-Distillation
This paper introduces a novel approach named FedBSD (Backbone Self-Distillation) for personalized federated learning (PFL), which aims to address the heterogeneity challenge in federated learning (FL) by effectively combining global model sharing and local personalization. Here's a detailed exploration.
Background and Motivation
Federated Learning aims to train machine learning models across decentralized devices or servers holding local data samples, without exchanging them. However, FL faces significant challenges when data distributed across clients is heterogeneous, leading to performance issues such as client drift. To overcome these challenges, personalized federated learning approaches have been proposed that either modify model structures or adjust parameters to accommodate local data variations. Previous works have explored various techniques like FedPer and FedRep that bifurcate model structures, but these approaches often result in suboptimal global model performance.
Key Contributions
Backbone Self-Distillation Framework
The core proposal of this paper is the FedBSD approach that divides each client's model into a shared backbone and a private head. The backbone is responsible for common representation learning, and the head is responsible for learning client-specific information.
- Shared Backbone: Clients periodically send backbone weights to the server for aggregation, resulting in a global backbone.
- Private Head: Trained locally for client-specific tasks, ensuring personalization.
The proposed method employs self-distillation wherein the global backbone serves as a teacher model to improve the local model's representation capabilities.
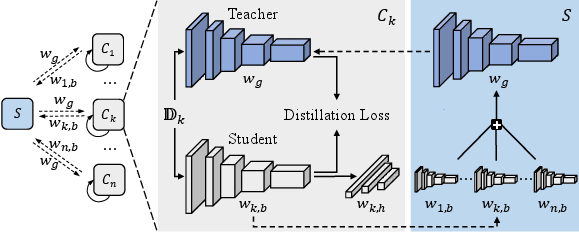
Figure 1: The framework of backbone self-distillation. Firstly, each client Ck divides its local model wk into a shared backbone wk,b and a private head wk,h, and communicates only the shared backbone wk,b with the server.
The Learning Process
- Model Partitioning: Client models are divided into backbone and head, and only the backbone is shared with the server.
- Backbone Aggregation: The server collects and aggregates backbones.
- Self-Distillation: Clients use the updated global backbone to fine-tune their local models through a self-distillation process, where the global backbone acts as an informative teacher model.
- Local Head Training: Clients update their head parameters using local data to improve personalization.
Experimental Setup
The study evaluates the effectiveness of FedBSD on several datasets including CIFAR10, CIFAR100, FEMNIST, and real-world datasets such as DomainNet and Digits. It compares FedBSD with notable PFL strategies including FedAvg, FedProx, and FedRep among others.
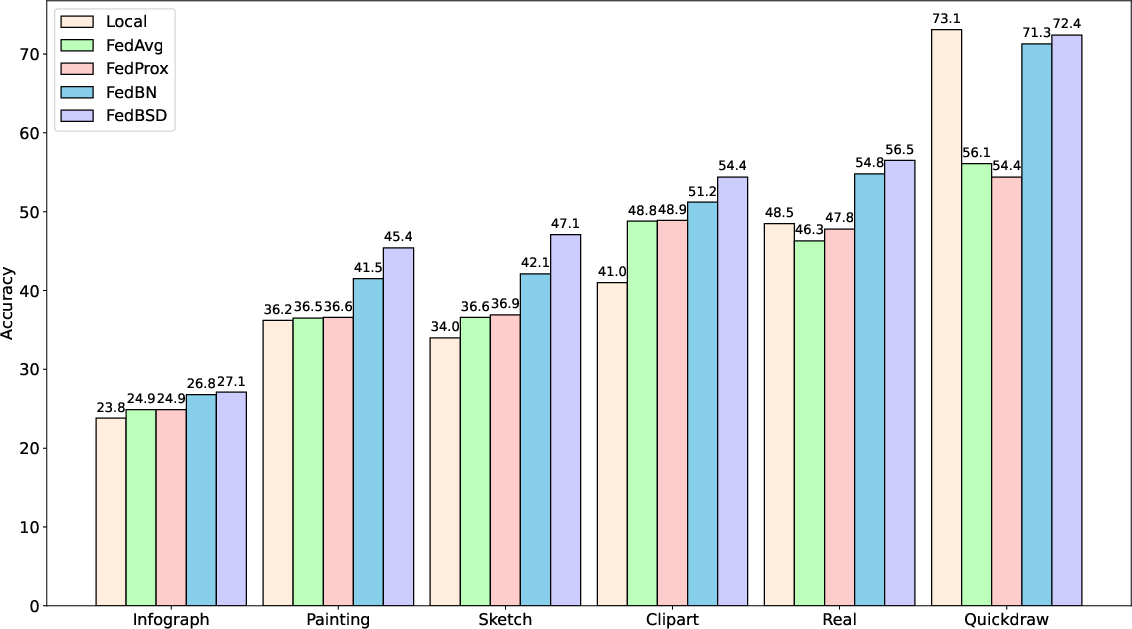
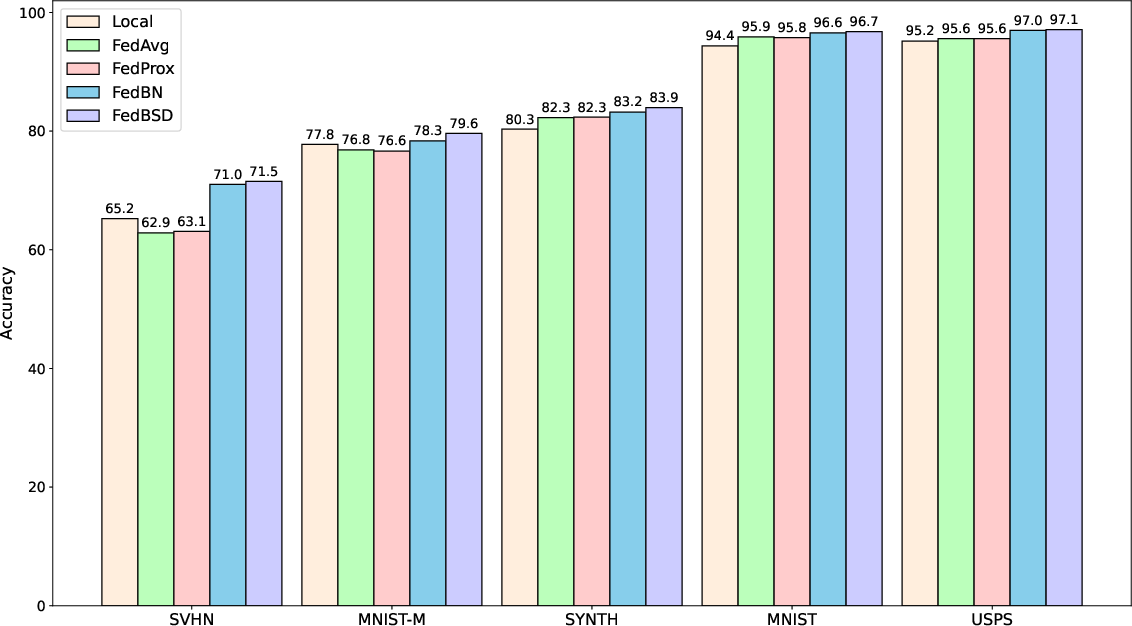
Figure 2: Test accuracy of various approaches on DomainNet (left) and Digits (right).
The experiments reveal that FedBSD consistently achieves higher accuracy over existing federated approaches across varied heterogeneous conditions.
Implementation Details
The FedBSD algorithm involves key hyperparameters such as:
- Learning rate η: Set typically to $0.01$ with momentum $0.5$.
- Temperature τ for knowledge distillation: Standard setting is τ=2.
- Number of local epochs and communication rounds: Adaptable based on client data size and dataset heterogeneity.
The backbone distillation loss integrates cross-entropy and Kullback–Leibler divergence tailored for backbone features rather than logits, emphasizing enhanced representation capacity without external data requirements.
Ablation Studies and Analysis
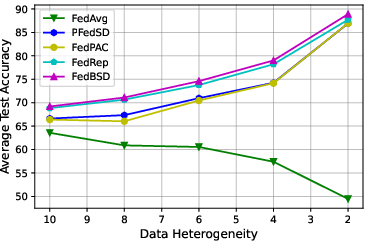
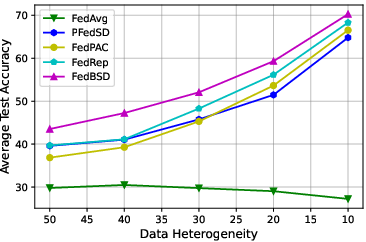
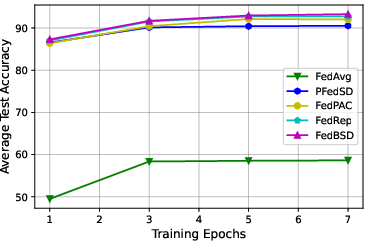
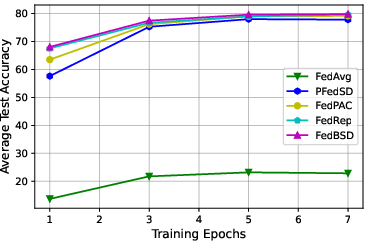
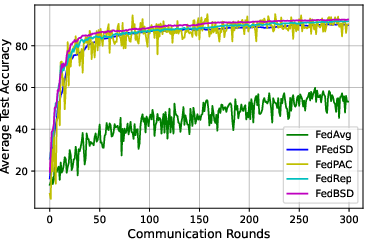
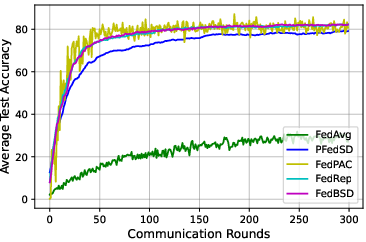
Figure 3: Ablation studies for data heterogeneity, training epochs, and communication rounds on CIFAR10 (left) and CIFAR100 (right).
Comprehensive ablation studies highlight:
- Data Heterogeneity: FedBSD scales effectively with increasing data heterogeneity.
- Training Epochs and Communication Rounds: Demonstrated efficiency by converging faster with fewer communication rounds.
Conclusion
The FedBSD approach distinctly stands out by efficiently addressing personalization and communication cost challenges in federated learning environments. It achieves a beneficial balance between leveraging shared global knowledge and ensuring client-specific customization, marking significant improvements in heterogeneous data scenarios without relying on additional data or complex model permutations.
Future research could explore the intersection of FedBSD with model compression techniques to further optimize communication efficiency, potentially broadening its applicability across even resource-constrained environments.

