- The paper introduces a novel structural editing method that employs reasoning triplets and knowledge graphs to overcome ambiguities in model and in-context editing.
- The methodology involves chain extraction, entity/relation parsing, and deterministic KG traversal, achieving 100% accuracy in single-edited multi-hop QA with minimal latency.
- The approach demonstrates significant improvements in robustness and speed over conventional editing techniques, offering transparent and reliable multi-hop reasoning.
StruEdit: Structured Outputs Enable Fast and Accurate Knowledge Editing in LLMs
Background and Motivation
Knowledge editing (KE) for LLMs addresses persistent concerns about outdated and incorrect parametric knowledge embedded in model weights after pretraining. Existing KE paradigms operate predominantly in two fashions: model editing (ME), which surgically modifies model parameters, and in-context editing (ICE), which injects new facts into the model's context or memory. Both paradigms are inherently limited by the lack of a structured representation of knowledge, leading to ambiguous localization of information to be edited and pronounced issues with inconsistent or hallucinated multi-hop reasoning. These issues are particularly acute as the complexity of the reasoning chain increases—a typical scenario in multi-hop question answering (QA).
StruEdit: Structured Knowledge Editing
StruEdit introduces a paradigm shift by abandoning the Locate-Then-Edit strategy. Instead, it leverages structured outputs, specifically reasoning triplets that form knowledge graphs (KGs), to perform explicit and comprehensive knowledge updates. In this framework, outdated or unreliable parametric knowledge is disregarded, and LLM outputs are deterministically regenerated over up-to-date structured knowledge.
Key distinctions among KE paradigms are visualized in the following figure:
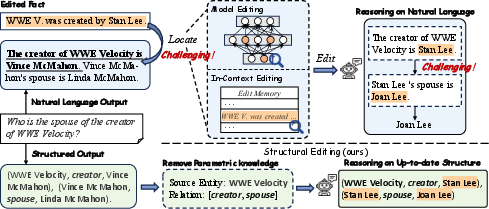
Figure 1: Schematic of the challenges in ME and ICE versus the structural editing process in StruEdit.
ME and ICE require locating the parts of the reasoning process potentially affected by a knowledge edit. This localization is error-prone in natural language, because tokenization artifacts and entangled reasoning steps make it hard to isolate only those portions of the chain influenced by a specific knowledge update. Structural editing, in contrast, removes all parametric traces possibly impacted by new information and reformulates answers by explicit reasoning over current knowledge structures—greatly reducing the risk of inconsistency and hallucination.
Methodology
StruEdit's workflow comprises three principal stages:
- Chain Extraction: The LLM is prompted (with in-context demonstrations) to generate a structured reasoning chain for the input multi-hop question.
- Entity and Relation Extraction: The resulting chain is parsed to extract a source entity and the sequence of relations required for the multi-hop inference.
- Reasoning Over Knowledge Structure: The extracted entity and relations are matched to an external, up-to-date knowledge graph. If exact matches are not found for entities or relations, the model employs rank-based matching on candidate sets using natural language entity/relation descriptions. Once the sequence is matched, traversing the KG deterministically yields the final answer.
This approach is illustrated below:
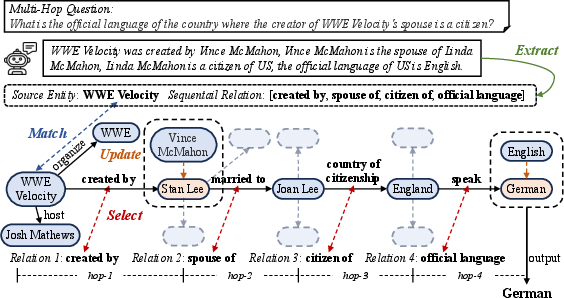
Figure 2: The StruEdit pipeline: generating the reasoning chain, structuring the logical relations/entities, matching to the KG, and executing the multi-hop path.
Unlike conventional approaches that patch or augment parametric knowledge, StruEdit discards all reasoning steps possibly affected by new or updated facts and fills in the chain purely based on explicit structural knowledge.
Experimental Evidence
Comprehensive evaluations employ the MQuAKE suite, which consists of multi-hop counterfactual QA tasks designed to stress-test KE in LLMs. Tasks assess both the accuracy of model responses post-edit and the robustness as hop count and batch size (number of edited facts) scale.
Notable findings include:
- Superior editing accuracy: StruEdit consistently achieves the highest accuracy across all tested scenarios—including both open-source (LLaMA2) and closed-source (GPT-3.5, GPT-4o) models. For instance, in multi-hop QA with a single relevant edited fact, StruEdit attains 100% accuracy, dramatically outperforming ME and ICE baselines, whose performance degrades sharply as reasoning hops increase or batch size becomes large.
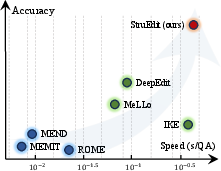
Figure 3: StruEdit achieves the highest accuracy and lowest latency among ME, ICE, and structural editing, even as reasoning hop count increases.
- Minimal latency: Editing latency is dramatically reduced with StruEdit. By eschewing iterative reasoning chains and full-context generation, the approach can answer complex multi-hop queries in nearly real-time, matching or outperforming even the most lightweight ICE variants on inference speed.
- Robustness to scaling: As both the number of reasoning hops and the number of edited facts scale up, StruEdit shows a substantially reduced degradation in accuracy. For each additional reasoning hop, conventional baselines degrade by 56–57% on average, whereas StruEdit only experiences a 38% drop.
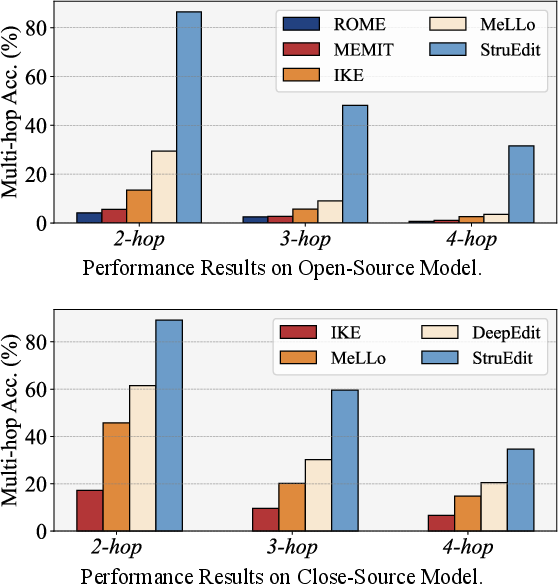
Figure 4: Editing accuracy across 2-, 3-, and 4-hop QA for both open- and closed-source LLMs using ME, ICE, and StruEdit.
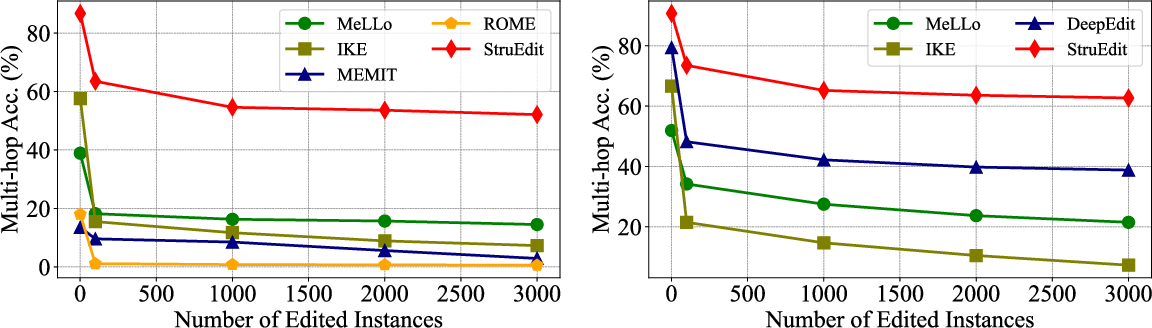
Figure 5: StruEdit maintains high performance across increasing numbers of edited knowledge instances, showing robust scalability.
Furthermore, because structural editing relies on the logical traversal of up-to-date KGs, it is immune to many confounding factors inherent in neural parametric memory—such as knowledge entanglement or overconfident hallucination when parametric and external knowledge conflict.
Practical and Theoretical Implications
StruEdit's approach has significant implications for both QA system design and model interpretability/control:
- Minimization of knowledge conflicts: By excising all parametric outputs potentially influenced by edited knowledge, StruEdit sidesteps hidden parameter entanglement and non-local interference that commonly afflicts weight-level KE methods.
- Explicit reasoning: Reasoning steps and answering logic become transparent and auditable, as the entire inference can be expressed as traversals over KGs driven by extracted logical predicates.
- Deployment relevance: The explicit, structure-based method is highly suited to real-world deployments where multiple, possibly simultaneous, factual updates are required—for example, counterfactual analysis, corrigibility in safety-critical systems, or continuous adaptation to evolving knowledge bases.
- Reduced dependence on model scale: Strong results are observed regardless of model size or proprietary status, suggesting that reliance on "emergent" reasoning capacities of large proprietary LLMs is lessened when logic is made explicit.
However, the strong dependence on accurate extraction of entities/relations and the need for structured KGs introduce new bottlenecks: degradation can occur if entity aliasing or incomplete KG coverage impairs matching. The paradigm requires structured knowledge and robust entity/relation extraction pipelines for end-to-end utility.
Future Directions
Future advancements could include:
- Optimization of entity/link extraction: Improving entity/relation extraction accuracy and disambiguation with enhanced LLM prompts or hybrid symbolic-neural architectures could further close the remaining performance gap in multi-hop challenging cases.
- Integration with retrieval: Combining StruEdit with sophisticated retrieval-augmented generation or hybrid memory systems to automatically update and expand KGs as new knowledge arrives.
- Automated KG construction: Methods for automatic, scalable, and constantly updating KG construction from unstructured data could expand the applicability of StruEdit to domains lacking manually curated KGs.
Conclusion
StruEdit provides an effective and robust solution to the problem of knowledge editing in LLMs by moving from token- and parameter-level interventions to direct structural manipulation. Experimental evidence demonstrates substantial improvements in accuracy, speed, and robustness compared to ME and ICE methods, especially for multi-hop and counterfactually consistent QA. The explicit, auditable reasoning enabled by StruEdit has significant implications for the design of reliable, controllable AI systems and suggests promising directions for future research at the intersection of KG reasoning and large-scale language modeling.