- The paper introduces SepFormer, a non-recurrent, attention-based model that uses Transformer blocks to replace RNNs for efficient speech separation.
- It employs dual-path processing with IntraTransformer and InterTransformer blocks to capture both short and long-term dependencies in audio signals.
- Experiments on WSJ0-2/3mix show SI-SNR improvements of 22.3 dB and 19.5 dB respectively, demonstrating significant computational efficiency gains.
Attention is All You Need in Speech Separation
Introduction
The paper "Attention is All You Need in Speech Separation" introduces the SepFormer, an innovative RNN-free architecture utilizing Transformers for speech separation tasks. Typically, RNNs have dominated sequence-to-sequence learning in speech separation, but their inherent sequential nature hinders parallel computation. The Transformer architecture, with its parallelizable multi-head attention mechanism, presents a promising alternative that circumvents these limitations. The SepFormer achieves state-of-the-art (SOTA) results on benchmarks like WSJ0-2/3mix datasets and showcases the potential advantages of employing Transformers in audio signal processing.
Model Architecture
The SepFormer leverages a dual-path processing framework, where RNNs commonly used in systems like Dual-Path RNN (DPRNN) are replaced with Transformer blocks.
- Encoder: The model begins with a convolutional encoder that transforms the input time-domain signal x∈RT into an STFT-like representation h∈RF×T′.
- Masking Network:
- The Masking Network, detailed in
(Figure 1)
Figure 1: The high-level architecture of the SepFormer including the Encoder, Masking Network, and Decoder.
processes the encoded representation to obtain masks for each speaker. It implements the dual-path strategy with IntraTransformer (short-term dependency modeling) and InterTransformer (long-term dependency modeling).
- SepFormer Block: Transformations within this block learn temporal dynamics with repeated IntraT and InterT arrangements that process overlapping chunks of the signal, minimizing Transformer scaling issues.
(Figure 2)
Figure 2: Detailed architecture of the SepFormer including IntraTransformer and InterTransformer blocks, which are pivotal for exploiting short and long-term dependencies.
- Decoder: Reconstructs the separated time-domain signals using a transposed convolution operation, applying the masks generated by the Masking Network to the encoded input.
Experimentation and Results
The SepFormer was evaluated using the WSJ0-2mix and WSJ0-3mix datasets. It achieved an SI-SNR improvement of 22.3 dB and 19.5 dB, respectively, in conditions augmented by dynamic mixing. These results surpass many RNN-based systems and even outperform others when augmented with additional data (e.g., Wavesplit with dynamic mixing).
Ablation Study
An analysis was performed to understand hyperparameters' effects, confirming that both IntraTransformer and InterTransformer blocks contribute significantly to performance. Dynamic mixing, dual-path processing, and the number of heads in the attention mechanism were fine-tuned for optimal results.
Resource Efficiency
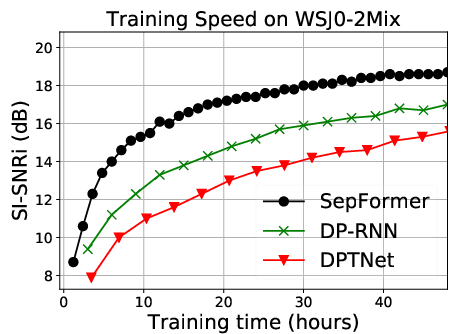
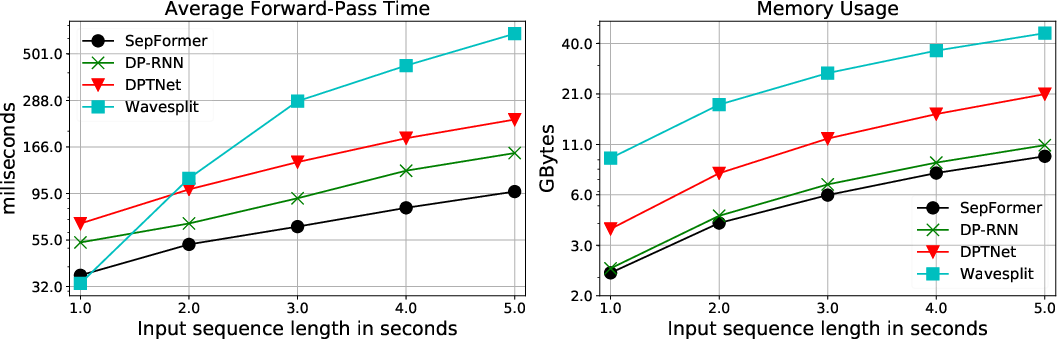
Figure 3: The training curves of SepFormer, DPRNN, and DPTNeT on the WSJ0-2mix dataset, illustrating the superior speed of the SepFormer.
SepFormer benefits from the parallelism inherent in Transformer architectures, leading to faster training and inference speeds while maintaining lower memory usage compared to traditional RNN-based frameworks, as reflected in significant computation efficiency over models like DPRNN and DPTNet.
Conclusion
The SepFormer model, by capitalizing on the strengths of Transformer architectures, mitigates the constraints associated with RNN-based models. It demonstrates that SOTA speech separation can be achieved with entirely non-recurrent, attention-focused methods, offering considerable computational advantages. Future research directions may explore refined Transformer architectures to unlock further performance improvements and operational efficiencies.