- The paper presents the SWAN benchmark and HQDL solution for hybrid querying, demonstrating how LLMs can supplement missing data in relational databases.
- Using few-shot GPT-4 Turbo prompts, the proposed method achieved 40.0% execution accuracy and a 48.2% F1 score, showcasing both its potential and current limitations.
- The paper outlines future directions such as improved prompt design and direct LLM integration into SQL for optimizing hybrid query processing.
Hybrid Querying with LLMs: The SWAN Benchmark and HQDL Solution
This paper introduces SWAN, a novel benchmark for evaluating hybrid queries that integrate relational databases with LLMs to answer beyond-database questions. The authors also present HQDL, a preliminary solution for addressing these complex queries, and highlight potential future research directions in this area. The evaluation demonstrates that HQDL, when using GPT-4 Turbo with few-shot prompts, achieves 40.0\% execution accuracy and 48.2\% data factuality, underscoring both the potential and challenges of hybrid querying.
SWAN Benchmark Construction
The SWAN benchmark is built upon the Bird benchmark and comprises 120 beyond-database questions spanning four real-world databases: European Football, Formula One, California Schools, and Superhero. To generate beyond-database questions, specific columns or entire tables were removed from the original databases, necessitating the use of LLMs to provide the missing information. This benchmark challenges LLMs to both select values from a predefined list and generate free-form outputs. For example, in the Superhero database, the publisher_id column was dropped, requiring the LLM to select the appropriate publisher for each superhero from a list of predefined publishers.
HQDL: A Hybrid Query Solution
The authors introduce HQDL (Hybrid Query Database LLM), a preliminary solution for solving beyond-database questions. HQDL leverages LLMs to generate missing columns and tables, using the keys consisting of the minimal number of attributes that represent the primary-key/foreign-key (PK-FK) relationships between the existing tables in the relational database and the tables generated by LLMs. HQDL instructs the LLMs to fill in the missing values in the target data entry. Value lists, such as publishers and colors, are provided for LLMs to select from, avoiding ambiguous data values. The generated data entries are then materialized into tables and inserted into a SQLite database. When one-to-many relationships occur, HQDL condenses the tuples in the "many" side of the relationship into a long text.
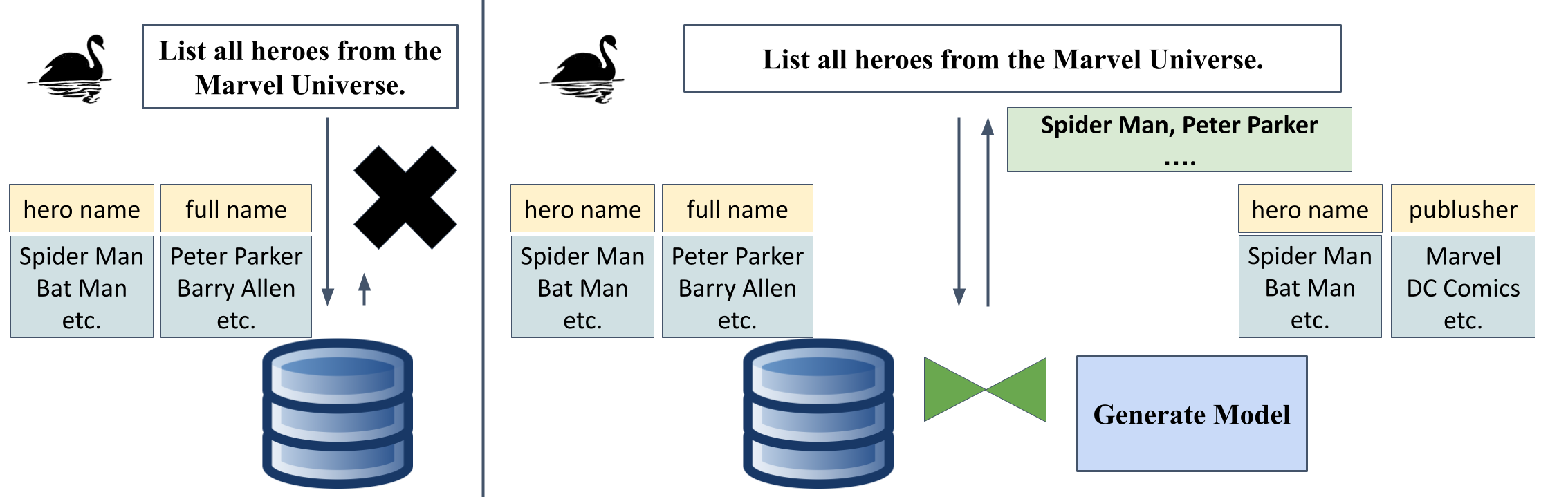
Figure 1: An illustrative example contrasting the answering of a beyond-database question solely using a database (left) versus hybrid querying over both databases and LLMs (right).
Evaluation Metrics and Results
The evaluation of hybrid queries uses three metrics: execution accuracy (EX), data factuality, and the number of input/output tokens. EX measures the percentage of hybrid queries that produce identical results to the ground truth. Data factuality is measured using exact string match and the F1 score. The results show that GPT-4 Turbo achieves 31.6\% accuracy on the SWAN benchmark, surpassing GPT-3.5 Turbo by 7.4% in the zero-shot setting. Providing static examples for few-shot learning significantly improves the quality of generated data entries, with GPT-4 Turbo achieving 40.0% execution accuracy and a 48.2\% F1 score for data factuality with 5-shot prompts. The results also indicate that selecting a subset of records using the LIMIT clause plays a significant role in the execution accuracy of hybrid queries.
Limitations and Future Directions
The authors acknowledge several limitations of HQDL. First, HQDL does not provide more context than the necessary keys and the predefined value lists. Second, the prompts and static examples used in HQDL are hand-crafted. Third, HQDL requires LLMs to generate all deleted data and materialize these data as tables, which may not be necessary for answering beyond-database questions. The authors observe that the industry has started integrating LLM calls directly into SQL syntax, such as Google BigQuery's syntax for directly querying LLMs using SQL. They suggest that this approach offers more control for the database to optimize the hybrid query, build materialized views, and potentially reduce the amount of data generated by LLMs.
Conclusion
This paper introduces SWAN, the first benchmark for evaluating hybrid queries that answer beyond-database questions using relational databases and LLMs. The authors also present HQDL, a preliminary solution for addressing questions in SWAN, achieving an accuracy of 40.0\% in execution accuracy and a 48.2\% F1 score for data factuality. The authors envision that this benchmark, along with the HQDL discussions, will spark interests within the community to develop comprehensive data systems that leverage the full potential of relational databases and LLMs.