- The paper introduces LaFAM, a method that computes saliency maps from average convolutional activations without using labels or gradients.
- It demonstrates superior performance over RELAX in self-supervised learning and competitive localization compared to Grad-CAM in supervised tasks.
- The approach offers high computational efficiency and broader feature coverage, making it suitable for real-time and large-scale CNN explainability.
Unsupervised Feature Attribution with Label-free Activation Maps (LaFAM)
Introduction
The paper "LaFAM: Unsupervised Feature Attribution with Label-free Activation Maps" (2407.06059) addresses the challenge of providing saliency-based explanations for convolutional neural networks (CNNs) in the absence of labels, particularly within the context of self-supervised learning (SSL). While activation maps (AMs) are known to encapsulate semantic and spatial information, their direct utilization for feature attribution without further manipulation or reliance on class labels has received limited attention. This work proposes Label-free Activation Maps (LaFAM), a method that leverages the raw AMs from CNNs to generate saliency maps in a label- and gradient-free manner, thereby advancing explainability in both supervised and self-supervised paradigms. The method is evaluated against established approaches—particularly RELAX for SSL and Grad-CAM for supervised learning—highlighting the advantages and tradeoffs of raw AM-based attribution.
Methodology
LaFAM is designed as a post hoc analytical tool for CNNs, extracting saliency maps purely from the average activations of a chosen convolutional layer. Importantly, LaFAM operates without supervision, label information, or backpropagated gradients. The process involves:
- Selecting a target convolutional layer and computing the average activation field across all channels at each spatial location.
- Performing min-max normalization to scale the AMs within [0,1].
- Upsampling the resulting map to the resolution of the input image.
By avoiding class-specific weighting, as is standard in class activation map (CAM) techniques, LaFAM reveals an unsupervised attribution of features, potentially corresponding to all learned concepts present in the scene. The approach is highly efficient since it requires only a single forward pass, with no masking or sampling operations required.
Comparison with Existing Approaches
Prior methods for feature attribution in CNNs can be categorized into:
- Occlusion-based and gradient-based CAM methods: E.g., Grad-CAM and its variants require label information to compute class-specific weights and generate attributions focused on predicted objects.
- Unsupervised Explainability (RELAX): RELAX replaces class scores by measuring the change in embedding caused by random occlusions, generating attribution via cosine similarity. This method, however, incurs high computational cost due to repeated inferences and tends to produce noisy outputs due to sampling artifacts.
LaFAM replaces the need for label-based semantic grounding with direct inspection of network activations, thus extending the applicability of XAI methods to SSL architectures where annotation is unavailable.
Experimental Evaluation
The empirical analysis spans supervised and SSL settings. Experiments are conducted using SimCLR and SwAV pretrained on ImageNet-1K, with tests on the ImageNet-S and PASCAL VOC 2012 datasets. Multiple evaluation metrics are used, including precision-oriented (Pointing-Game, Top-K Intersection, Relevance Rank/ Mass Accuracy), noise sensitivity (Sparseness), and overall discriminativity (AUC).
Key results include:
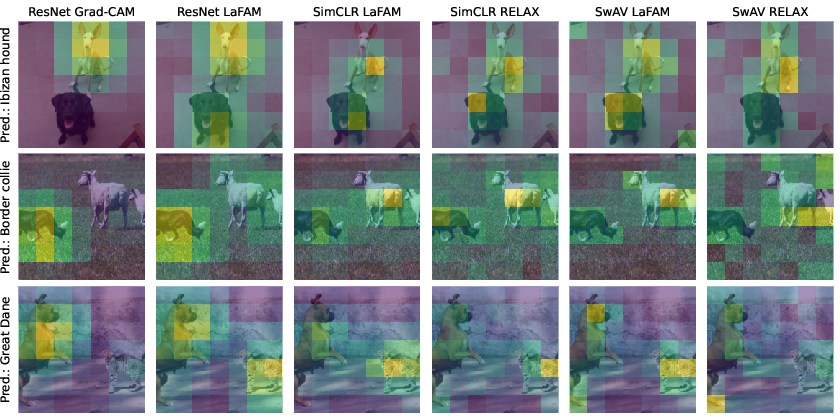
- In SSL scenarios, LaFAM outperforms RELAX across all metrics. For example, in the PASCAL VOC 2012 evaluation, LaFAM consistently achieves higher Pointing-Game and Top-K Intersection scores, indicating more accurate localization and alignment with annotated objects. RELAX, while label-free, yields substantially noisier and less interpretable maps, particularly for small objects.
- In supervised scenarios, LaFAM demonstrates competitive performance with Grad-CAM across saliency metrics, especially regarding object localization. However, its lower Sparseness score indicates inclusion of broader regions—interpreted as capturing multiple concepts per image rather than noise. Grad-CAM, by construction, focuses only on the class of the maximal prediction, which can be misleading in multi-object settings or misclassification cases.
Qualitative examples substantiate these claims:
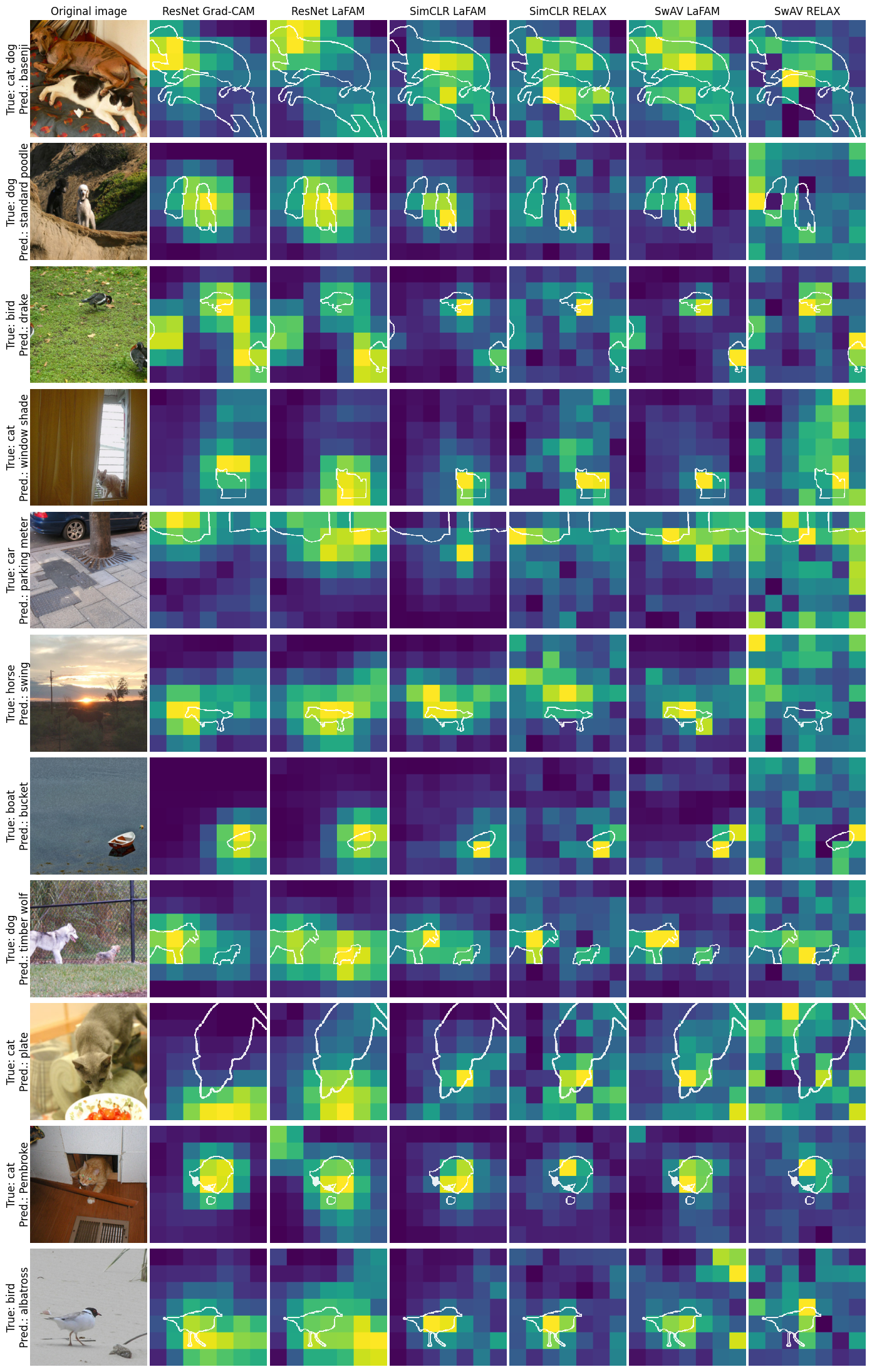
Figure 2: LaFAM produces saliency maps on PASCAL VOC 2012 that closely resemble Grad-CAM, but RELAX outputs are substantially noisier, especially in scenes with miscalssification.
Practical and Theoretical Implications
LaFAM's computational efficiency and absence of hyperparameters make it highly suitable for large-scale and real-time analysis of CNNs, including SSL models increasingly prominent as foundation models. By not depending on annotated data, it addresses the need for transparent explainability mandated in regulated domains such as healthcare. From a theoretical perspective, LaFAM aligns with emergent evidence that semantic detectors form in late-stage representations of CNNs, independent of class-specific supervision. Its broader feature coverage contrasts with the discriminative but potentially brittle outputs of gradient-based CAMs, which may be misleading in the case of incorrect model predictions.
One limitation remains the inherently low resolution dictated by the spatial size of the final convolutional layer. The paper suggests possible remedies such as propagating attribution maps through layer-wise relevance propagation (LRP), although practical validation is pending.
Future Outlook
Future work will likely explore integrating LaFAM with hierarchical or multi-scale feature extraction, enabling higher fidelity saliency maps. Its label-free paradigm may also extend to hybrid architectures (e.g., vision transformers with convolutional stems) and non-visual modalities, leveraging direct feature activation statistics in unsupervised or semi-supervised frameworks. Combining LaFAM with methods that refine or disentangle concept attribution could improve human interpretability without sacrificing coverage.
Conclusion
LaFAM represents an effective and computationally tractable approach for feature attribution in CNNs, uniquely addressing the gap in unsupervised explanatory methods. Its strong empirical performance in SSL contexts, superior to state-of-the-art alternatives like RELAX, and its parity with Grad-CAM in supervised evaluation, underpins its value. The method's robustness to multi-object and misclassified scenarios constitutes a noteworthy advantage for both model auditing and transparency. As SSL and foundation models proliferate, label-free attribution strategies such as LaFAM will become central to practical and responsible deployment of deep learning systems.