- The paper introduces the SAGE framework that uses a two-stage synthetic data generation process to address privacy risks in RAG systems.
- The paper demonstrates that an attribute-based generation followed by agent-based refinement significantly reduces data leakage while achieving comparable BLEU and ROUGE scores.
- The paper’s results indicate that synthetic data can secure privacy in sensitive applications, paving the way for more robust AI deployments.
Mitigating Privacy Issues in RAG via Synthetic Data
This essay explores a methodology to address privacy concerns in Retrieval-Augmented Generation (RAG) systems by employing synthetic data. The core innovation lies in a two-stage process that aims to maintain the utility of data while significantly enhancing its privacy properties.
Introduction to RAG and Privacy Concerns
Retrieval-Augmented Generation (RAG) enhances LLM outputs through the integration of retrieved data from external sources. While effective in applications such as domain-specific dialogues and completions, RAG systems are vulnerable to privacy risks, especially when interacting with sensitive data. Previous adaptations have only partially addressed these concerns and often at the cost of utility. Hence, the paper introduces a data-level alternative using synthetic data.
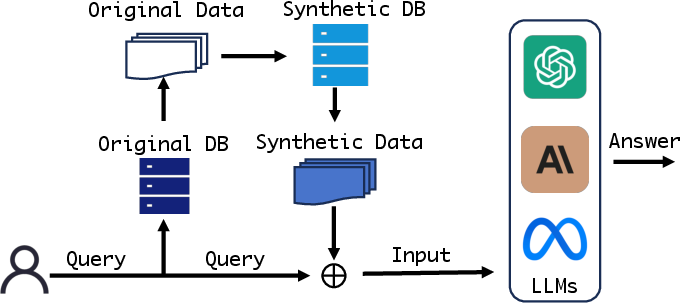
Figure 1: An illustration for RAG with synthetic data.
SAGE Framework: Synthetic Data Generation
The Synthetic Attribute-based Generation with agEnt-based refinement (SAGE) framework addresses these privacy concerns with a focus on maintaining the essential characteristics of original data. This section outlines the two stages of its operation.
Stage-1: Attribute-Based Data Generation
This stage utilizes an attribute-based extraction and generation protocol to construct synthetic data. Key elements of data are extracted, ensuring that the resultant synthetic data preserves critical information while minimizing privacy risks. This involves few-shot prompting of LLMs to identify crucial attributes, followed by generating data that encapsulates these attributes.
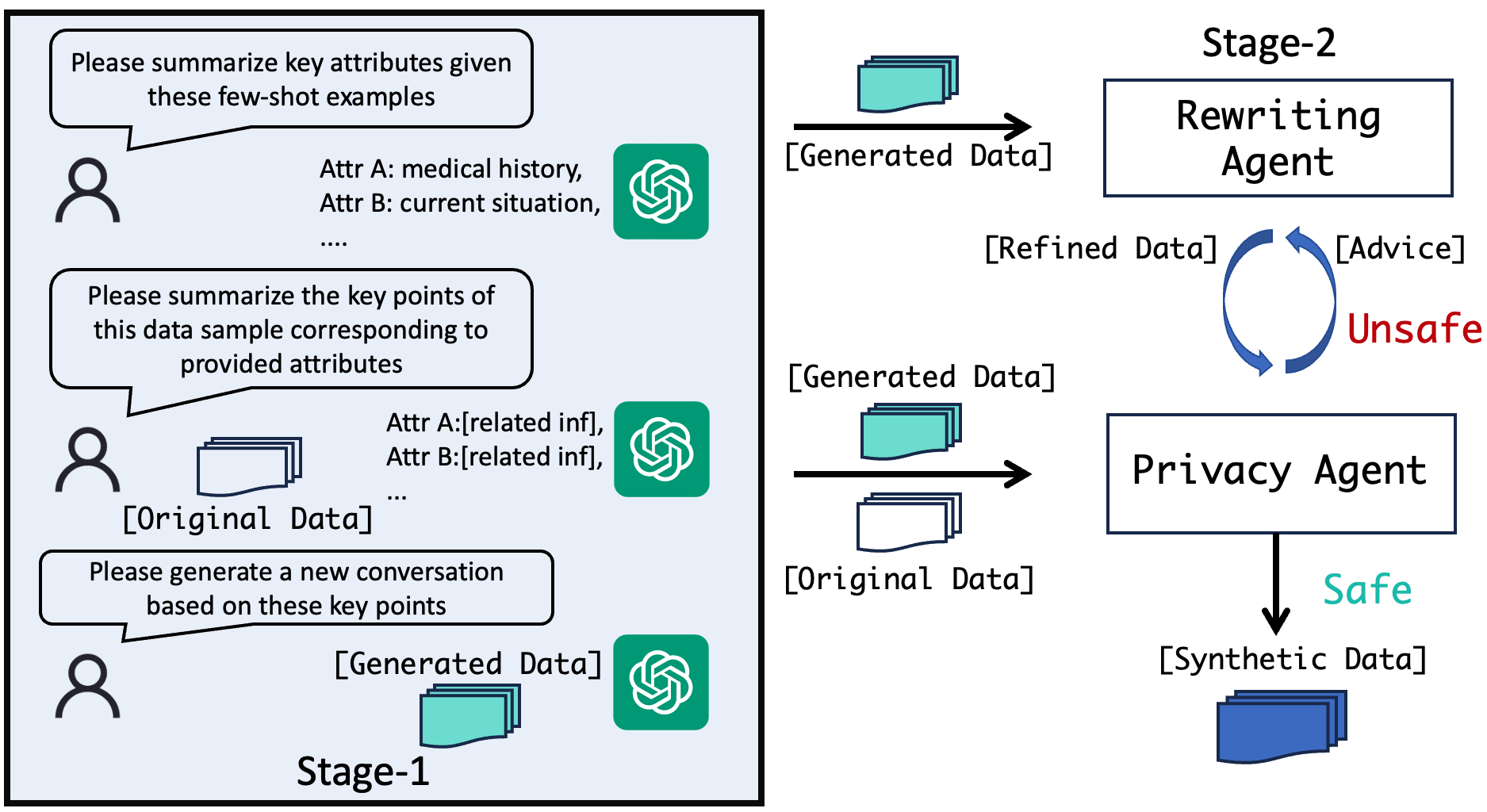
Figure 2: Pipeline of generating synthetic data.
Stage-2: Agent-Based Data Refinement
Stage-2 introduces two collaborating agents: a privacy assessment agent and a rewriting agent, tasked with iterative data refinement. The privacy agent evaluates generated data for sensitive content against predefined criteria, providing feedback to the rewriting agent for adjustments, thereby creating refined data that bolsters privacy further without sacrificing data utility.
Empirical Evaluation and Utility
The study evaluates the efficacy of synthetic data on both utility and privacy metrics across datasets, including medical dialogues and mixed public-private datasets. Experiments demonstrate that synthetic data achieves comparable performance metrics to original data, based on BLEU and ROUGE scores, while mitigating risks significantly in targeted and untargeted attack scenarios.
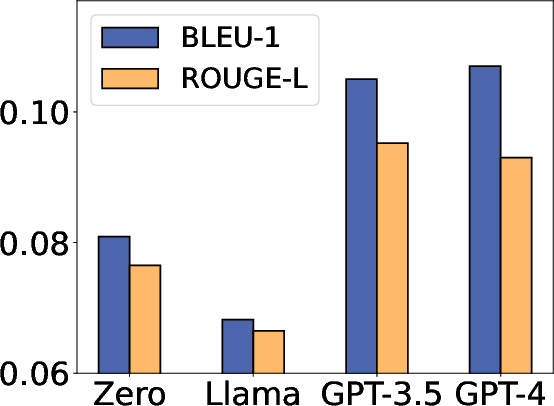
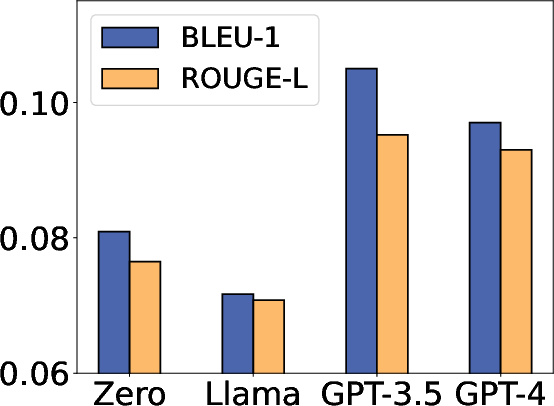
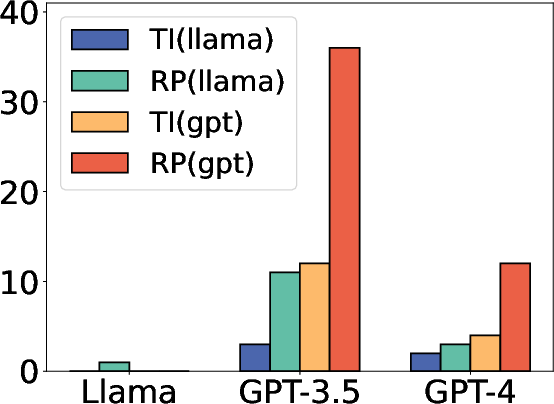
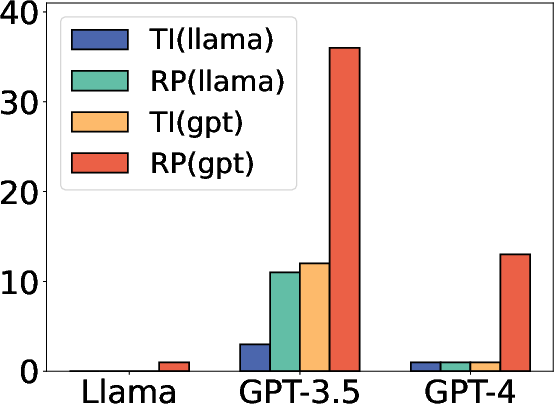
Figure 3: Ablation study on model choice. TI means targeted information and RP means repeat prompts.
Privacy Evaluation
The evaluation against attacks reveals that while Stage-1 offers a degree of privacy protection, Stage-2 significantly reduces vulnerability, approaching a near-zero leakage rate. This underscores the effectiveness of the iterative refinement in addressing privacy concerns inherent in RAG systems.
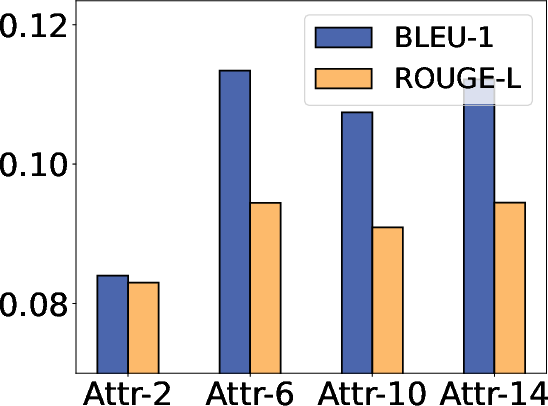
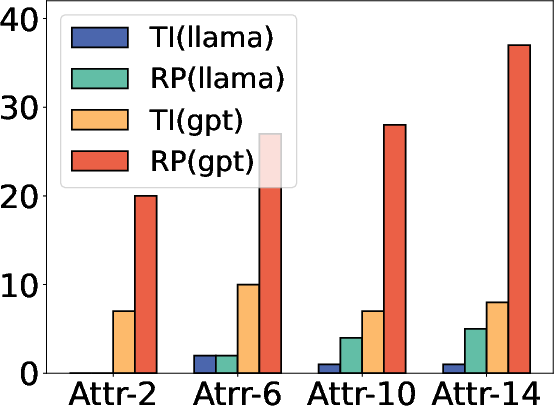
Figure 4: Ablation study on the number of attributes m.
Future Directions and Conclusion
The implications of using synthetic data in RAG systems extend beyond immediate privacy gains, offering a pathway to broader applications in sensitive domains like healthcare and finance, where data security is paramount. Future work could explore integration with differential privacy frameworks to enhance theoretical guarantees. The SAGE framework sets the stage for more secure and robust RAG systems, addressing critical concerns in the deployment of AI technologies in privacy-sensitive areas.
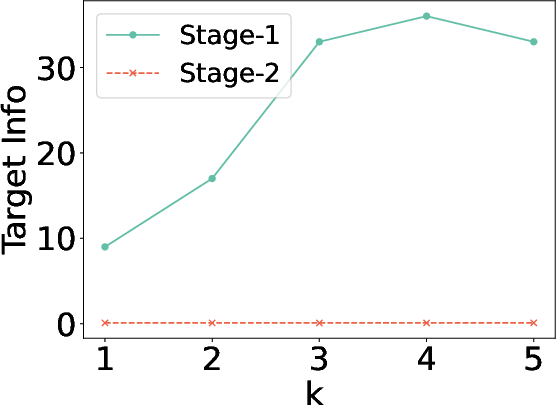
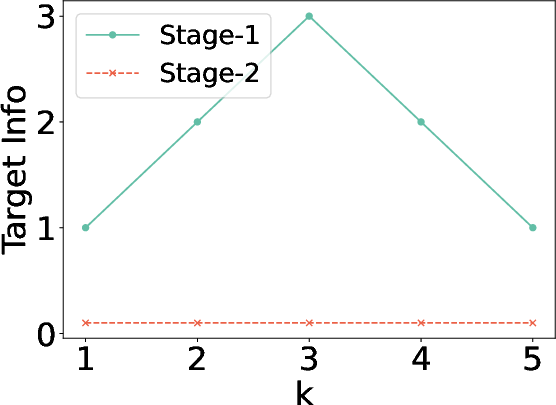
Figure 5: Ablation study on number of retrieved docs.
In summary, the adoption of synthetic data through the SAGE framework offers a compelling solution to privacy concerns in RAG while preserving the utility of generated outputs. This approach provides a foundational step towards safer AI applications in privacy-critical sectors.