- The paper presents a comprehensive review of machine unlearning techniques, detailing both data-oriented and model-oriented methods.
- It demonstrates that while unlearning supports privacy regulations, these methods may introduce vulnerabilities like membership inference and backdoor attacks.
- The review underscores the need to integrate privacy-enhancing techniques, such as differential privacy, to solidify unlearning efficacy and model integrity.
An Exploration of Machine Unlearning: Techniques and Emerging Privacy Concerns
Machine unlearning has become a prominent area of research in the field of privacy protection as machine learning systems increasingly incorporate vast amounts of data. With legislative measures like GDPR enforcing the right to be forgotten, the need for efficient methods to remove data and its influence from trained models has grown. The paper presents a comprehensive review of machine unlearning techniques and highlights new privacy risks associated with these methods.
Introduction to Machine Unlearning
Machine unlearning refers to the process of effectively removing specific data and its impact from a machine learning model. While retraining from scratch remains the most straightforward approach, it is computationally expensive, especially for large datasets. The challenge lies in developing methods that can unlearn data efficiently without compromising model accuracy and integrity.
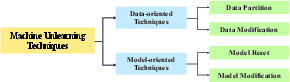
The paper outlines two main categories of unlearning techniques: data-oriented and model-oriented. Data-oriented approaches modify or partition the training set, while model-oriented approaches adjust model parameters directly. These techniques aim to achieve indistinguishable performance between models trained with and without the forgotten data, yet they often introduce new vulnerabilities.
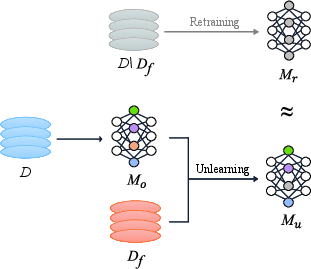
Figure 1: The Objective of Machine Unlearning.
Techniques of Machine Unlearning
The techniques are categorized into two primary types: data-oriented and model-oriented.
Data-Oriented Techniques
These techniques focus on modifying the training data itself. They can be subdivided into data partition and data modification methods.
- Data Partition: Methods like SISA (Sharded, Isolated, Sliced, and Aggregated learning) partition the data into subsets, training separate models and retraining only affected ones upon data deletion.
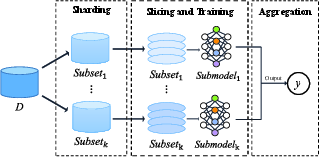
Figure 2: SISA.
- Data Modification: Techniques involve transforming or adding noise to the data so its influence on the model can be updated without a full retraining.
Model-Oriented Techniques
This category focuses on adjusting model parameters, either by resetting them or modifying specific parts.
Privacy Risks in Machine Unlearning
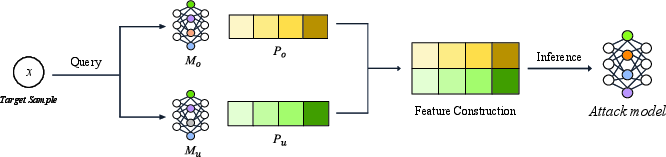
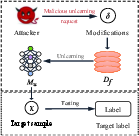
Despite their intent to enhance privacy, unlearning methods can inadvertently create new attack vectors. The paper identifies two primary categories of privacy threats: information-stealing attacks and model-breaking attacks.
These attacks exploit the differences between learned and unlearned models to extract information.
Model-Breaking Attacks
These attacks target the integrity of unlearning models.
Implications and Future Directions
The paper suggests a need for further exploration into defenses against these newly exposed vulnerabilities. Techniques like differential privacy and robust training should be integrated into unlearning methods to strengthen security and privacy guarantees. Additionally, the growing complexity of machine learning models, particularly in federated learning and LLMs, calls for efficient unlearning mechanisms that maintain model performance without extensive computational costs.
Conclusion
Machine unlearning is crucial for upholding privacy in machine learning systems but must be carefully deployed to avoid introducing new vulnerabilities. Ongoing research will need to focus on improving efficiency and robustness of unlearning techniques, ensuring they can be applied broadly across different types of models and datasets. The findings in this paper underscore the importance of developing more secure unlearning approaches that can support diverse applications in AI.