- The paper introduces a novel framework integrating case-based reasoning into retrieval-augmented generation to improve the accuracy of legal question answering.
- It employs dual embedding strategies using LegalBERT and AnglEBERT, optimizing case retrieval and generative outputs.
- Empirical results demonstrate that enriched case-based context leads to higher F1 scores and improved cosine similarity metrics over baseline models.
CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
The paper "CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering" addresses the integration of Case-Based Reasoning (CBR) into Retrieval-Augmented Generation (RAG) systems, aiming to enhance performance in the legal domain by providing contextually rich responses derived from case-based knowledge.
Introduction to Retrieval-Augmented Generation and Case-Based Reasoning
Retrieval-Augmented Generation enhances LLMs by incorporating external sources to bolster the knowledge base and address existing limitations such as knowledge updating and provenance. By implementing CBR, the authors propose a retrieval system that organizes non-parametric memory based on case relevance, effectively bridging the gap between neural-based outputs and factually validated answers.
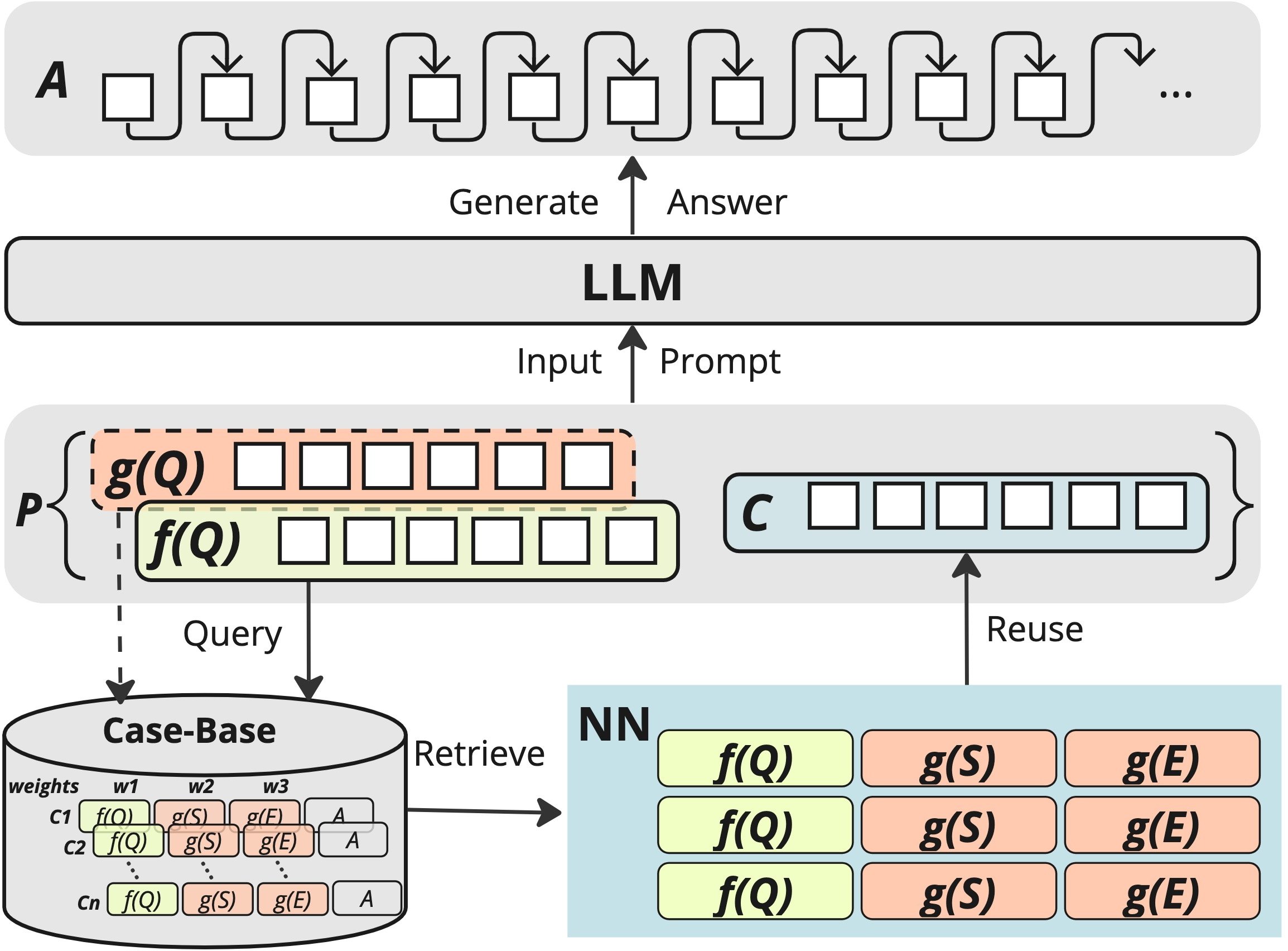
Figure 1: CBR-RAG.
The paper argues that CBR’s ability to organize experience-derived cases as knowledge entries can improve retrieval processes vital for producing accurate LLM-generated outputs in legal question answering. CBR facilitates context-aware retrieval by leveraging similarity between query components and previously indexed cases.
Methodology
Casebase Creation and Indexing
The researchers constructed the casebase using the Australian Open Legal QA (ALQA) dataset, consisting of synthesized question-answer pairs, curated and validated to ensure factual correctness without hallucinated elements. The dataset was analyzed for legal act citations to establish indexing vocabularies, demonstrating the shortcomings of solely relying on named acts due to distribution sparsity.
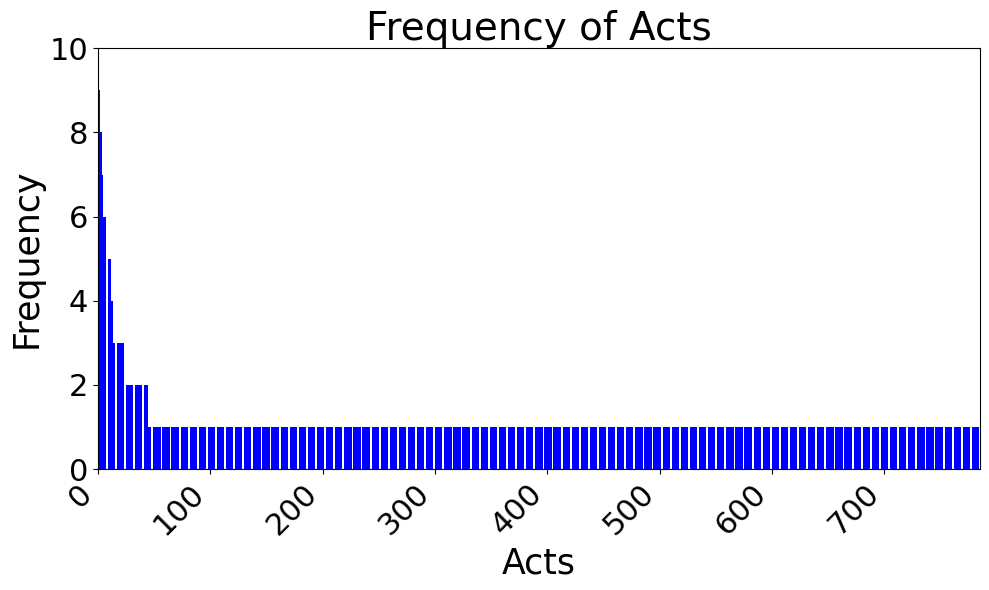
Figure 2: Ten most frequent legal acts in the casebase are listed on the left, and the legal act frequency distribution appears on the right.
Representation and Similarity Measures
CBR-RAG systems employ dual embedding strategies, consisting of intra-embeddings for attribute-specific comparisons, and inter-embeddings for broader IR-style retrieval scenarios. This dual approach allows for dynamic matching strategies tuned to query relevance, across diverse segments of content being matched.
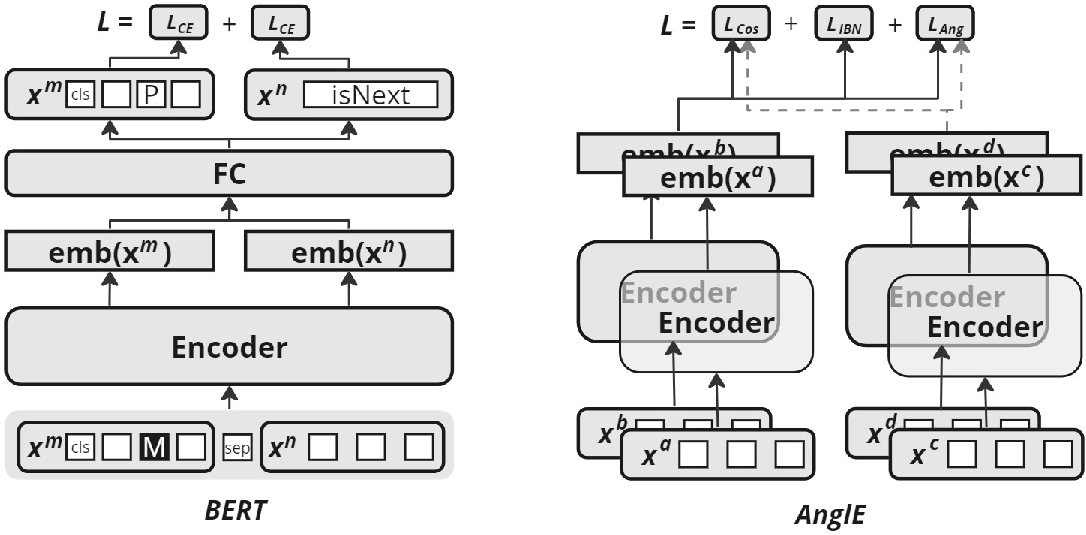
Figure 3: Architecture and training process for BERT and AnglEBERT. Note that LegalBERT has the same architecture as BERT, but is pre-trained on legal text.
Encoding Techniques
The paper evaluates encoder models including BERT, LegalBERT, and AnglEBERT, emphasizing LegalBERT’s domain-specific pre-training advantage. AnglEBERT, with its contrastive learning mechanism, delivers optimized embeddings by overcoming cosine similarity’s saturation problem in complex spaces, which proved essential for legal domain accuracy.
Evaluation
Retrieval Effectiveness
The evaluation focused on examining the effectiveness of retrieval methods with varied embedding strategies and weights. Using a test set derived by pairing cases based on shared legal acts, AnglEBERT demonstrated a pronounced ability to more accurately retrieve relevant cases, thereby enhancing generative task performance.
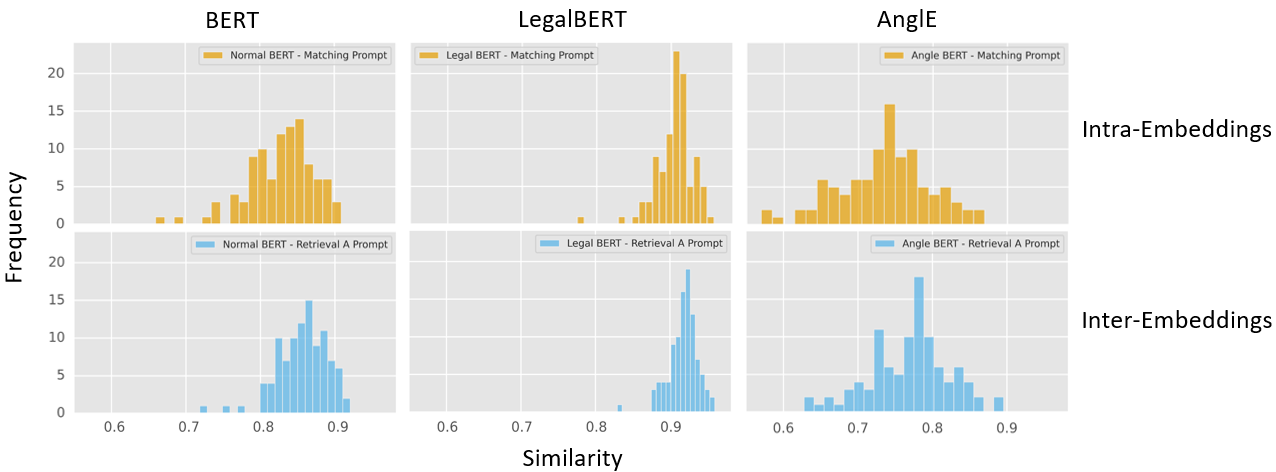
Figure 4: Cosine similarity distribution for intra- and inter-embeddings.
The system measured linearly against a baseline, using semantic similarity to evaluate enhanced generative output from CBR-RAG versus the conventional No-RAG setup. Across various configurations, AnglEBERT produced superior cosine similarity scores, particularly when utilizing complete case-based context for the prompt.
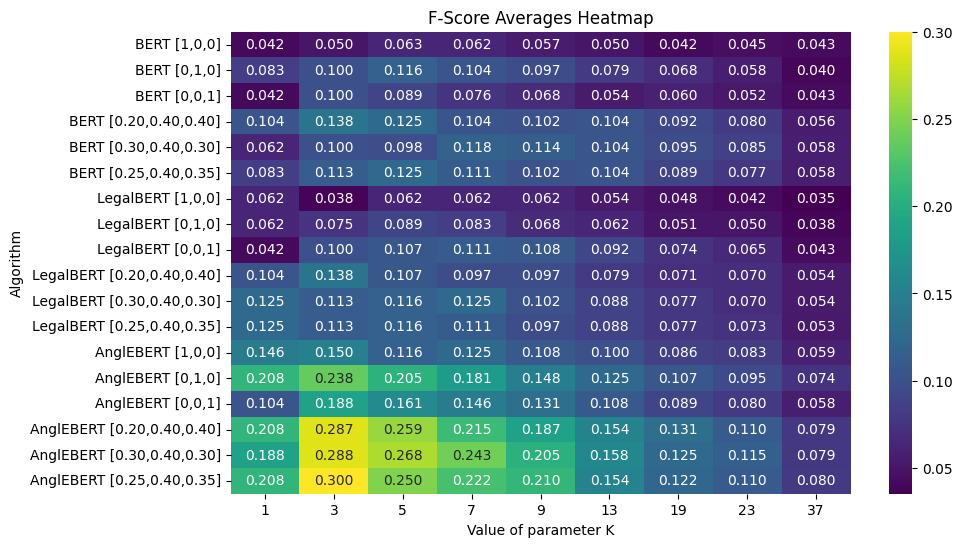
Figure 5: F1 score for Retrieval@k.
Conclusion
CBR-RAG introduces a robust framework for augmenting the generative capabilities of LLMs in the legal domain by integrating case-based reasoning for enriched contextual prompts. The study highlights the performance benefits of employing case retrieval systems in RAG, coupled with strategic embeddings that contribute to improved answer accuracy. The findings encourage continued exploration into embedding models and aggregation strategies to further optimize case retrieval mechanisms.
Future research prospects involve refining domain-specific embeddings and exploring aggregation methodologies to optimize the case-based context within prompts further.