UniBind: LLM-Augmented Unified and Balanced Representation Space to Bind Them All
Abstract: We present UniBind, a flexible and efficient approach that learns a unified representation space for seven diverse modalities -- images, text, audio, point cloud, thermal, video, and event data. Existing works, eg., ImageBind, treat the image as the central modality and build an image-centered representation space; however, the space may be sub-optimal as it leads to an unbalanced representation space among all modalities. Moreover, the category names are directly used to extract text embeddings for the downstream tasks, making it hardly possible to represent the semantics of multi-modal data. The 'out-of-the-box' insight of our UniBind is to make the alignment center modality-agnostic and further learn a unified and balanced representation space, empowered by the LLMs. UniBind is superior in its flexible application to all CLIP-style models and delivers remarkable performance boosts. To make this possible, we 1) construct a knowledge base of text embeddings with the help of LLMs and multi-modal LLMs; 2) adaptively build LLM-augmented class-wise embedding center on top of the knowledge base and encoded visual embeddings; 3) align all the embeddings to the LLM-augmented embedding center via contrastive learning to achieve a unified and balanced representation space. UniBind shows strong zero-shot recognition performance gains over prior arts by an average of 6.36%. Finally, we achieve new state-of-the-art performance, eg., a 6.75% gain on ImageNet, on the multi-modal fine-tuning setting while reducing 90% of the learnable parameters.
- A review on language models as knowledge bases. arXiv preprint arXiv:2204.06031, 2022.
- Iterative zero-shot llm prompting for knowledge graph construction. arXiv preprint arXiv:2307.01128, 2023.
- Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015.
- Uniter: Universal image-text representation learning. In European conference on computer vision, pages 104–120. Springer, 2020.
- Cico: Domain-aware sign language retrieval via cross-lingual contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19016–19026, 2023.
- Knowledge base question answering by case-based reasoning over subgraphs. In International conference on machine learning, pages 4777–4793. PMLR, 2022.
- Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Multimodal sensors and ml-based data fusion for advanced robots. Advanced Intelligent Systems, 4(12):2200213, 2022.
- Learning visual representations via language-guided sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19208–19220, 2023.
- Clip2video: Mastering video-text retrieval via image clip. arXiv preprint arXiv:2106.11097, 2021.
- Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In 2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004.
- Devise: A deep visual-semantic embedding model. Advances in neural information processing systems, 26, 2013.
- Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023.
- Kat: A knowledge augmented transformer for vision-and-language. arXiv preprint arXiv:2112.08614, 2021.
- Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023.
- Audioclip: Extending clip to image, text and audio. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976–980. IEEE, 2022.
- Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv preprint arXiv:2108.02035, 2021.
- Clip2point: Transfer clip to point cloud classification with image-depth pre-training. arXiv preprint arXiv:2210.01055, 2022.
- Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1037–1045, 2015.
- Llvip: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3496–3504, 2021.
- N-imagenet: Towards robust, fine-grained object recognition with event cameras. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2146–2156, 2021.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023a.
- Oscar: Object-semantics aligned pre-training for vision-language tasks. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16, pages 121–137. Springer, 2020.
- Flexkbqa: A flexible llm-powered framework for few-shot knowledge base question answering. arXiv preprint arXiv:2308.12060, 2023b.
- Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. arXiv preprint arXiv:2305.13655, 2023.
- Universal vision-language dense retrieval: Learning a unified representation space for multi-modal retrieval. In The Eleventh International Conference on Learning Representations, 2022.
- Semantic-aware scene recognition. Pattern Recognition, 102:107256, 2020.
- Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022.
- Image anything: Towards reasoning-coherent and training-free multi-modal image generation. arXiv preprint arXiv:2401.17664, 2024.
- Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
- Ave-clip: Audioclip-based multi-window temporal transformer for audio visual event localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5158–5167, 2023.
- Open vocabulary semantic segmentation with patch aligned contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19413–19423, 2023.
- I2mvformer: Large language model generated multi-view document supervision for zero-shot image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15169–15179, 2023.
- Llm2kb: Constructing knowledge bases using instruction tuned context aware large language models. arXiv preprint arXiv:2308.13207, 2023.
- Multimodal deep learning. In Proceedings of the 28th international conference on machine learning (ICML-11), pages 689–696, 2011.
- OpenAI. Gpt-4 technical report, 2023.
- Converting static image datasets to spiking neuromorphic datasets using saccades. Frontiers in neuroscience, 9:437, 2015.
- Karol J Piczak. Esc: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, pages 1015–1018, 2015.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia, pages 1041–1044, 2014.
- Pre-training multi-modal dense retrievers for outside-knowledge visual question answering. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, pages 169–176, 2023.
- Shubhra Kanti Karmaker Santu and Dongji Feng. Teler: A general taxonomy of llm prompts for benchmarking complex tasks. arXiv preprint arXiv:2305.11430, 2023.
- Logical neural networks for knowledge base completion with embeddings & rules. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3863–3875, 2022.
- Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
- Recent advancements in multimodal human–robot interaction. Frontiers in Neurorobotics, 17:1084000, 2023.
- Vl-bert: Pre-training of generic visual-linguistic representations. arXiv preprint arXiv:1908.08530, 2019.
- Learning audio-visual source localization via false negative aware contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6420–6429, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Multimodal token fusion for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12186–12195, 2022.
- iclip: Bridging image classification and contrastive language-image pre-training for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2776–2786, 2023.
- 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015.
- Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016.
- Clip-vip: Adapting pre-trained image-text model to video-language representation alignment. arXiv preprint arXiv:2209.06430, 2022.
- Unified contrastive learning in image-text-label space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19163–19173, 2022a.
- Enhancing multi-modal and multi-hop question answering via structured knowledge and unified retrieval-generation. arXiv preprint arXiv:2212.08632, 2022b.
- Cmx: Cross-modal fusion for rgb-x semantic segmentation with transformers. IEEE Transactions on Intelligent Transportation Systems, 2023a.
- Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5579–5588, 2021.
- Pointclip: Point cloud understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8552–8562, 2022.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023b.
- Meta-transformer: A unified framework for multimodal learning. arXiv preprint arXiv:2307.10802, 2023c.
- A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Cvt-slr: Contrastive visual-textual transformation for sign language recognition with variational alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23141–23150, 2023a.
- Deep learning for event-based vision: A comprehensive survey and benchmarks. arXiv preprint arXiv:2302.08890, 2023b.
- E-clip: Towards label-efficient event-based open-world understanding by clip. arXiv preprint arXiv:2308.03135, 2023.
- Pointclip v2: Adapting clip for powerful 3d open-world learning. arXiv preprint arXiv:2211.11682, 2022.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
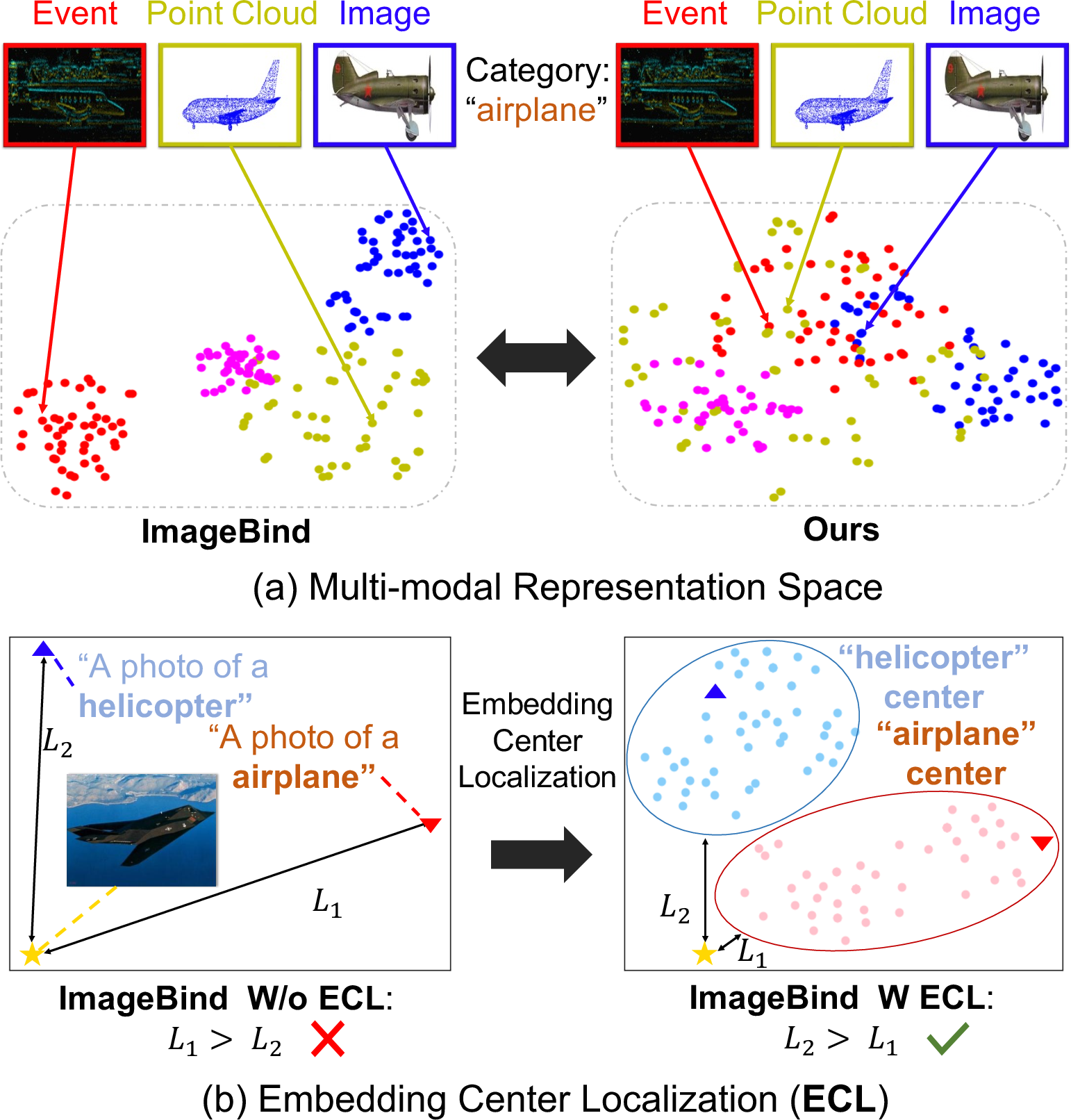
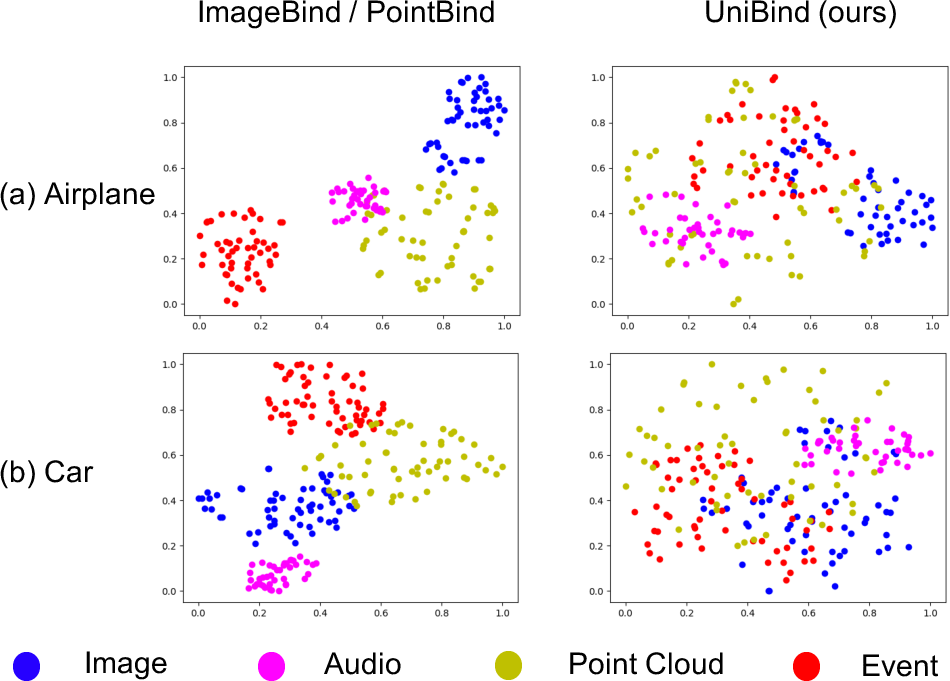
The paper introduces UniBind, a way for computers to understand many kinds of data—like pictures, sounds, videos, 3D shapes, heat images, and even special camera “events”—in one shared “language.” Think of it like making a single map where all these different types of information can be placed fairly, so the computer can compare and connect them easily.
Previous systems often put images at the center and forced every other type of data to match the image world. UniBind does something different: it uses strong LLMs (like GPT-4) to create neutral “meeting points” for concepts. Then all types of data learn to meet at these points. This makes the shared space more balanced and fair to every modality (type of data).
The main questions the paper asks
Here are the two big problems the authors wanted to solve:
- Can we avoid bias from making images the “boss” of the shared space? In other words, can we build a space that’s not centered on any one modality?
- Can we represent categories (like “airplane” or “dog”) better than just using the category name? A single word often misses important details (like background, lighting, sounds, or shapes).
How UniBind works (using everyday ideas)
To explain a few technical terms:
- Modality: a type of data (image, text, audio, video, 3D point cloud, thermal, event).
- Representation space: imagine a huge map where every piece of data (a sound, a picture, a video) gets a dot. Dots that mean similar things should be close together.
- Contrastive learning: a training trick that pulls matching pairs closer (like a cat photo and the text “a cat”) and pushes mismatched pairs apart.
- Embedding center: a “meeting spot” on the map for a category, like a well-chosen landmark where all “airplane”-related data can gather.
Here’s the simple step-by-step idea:
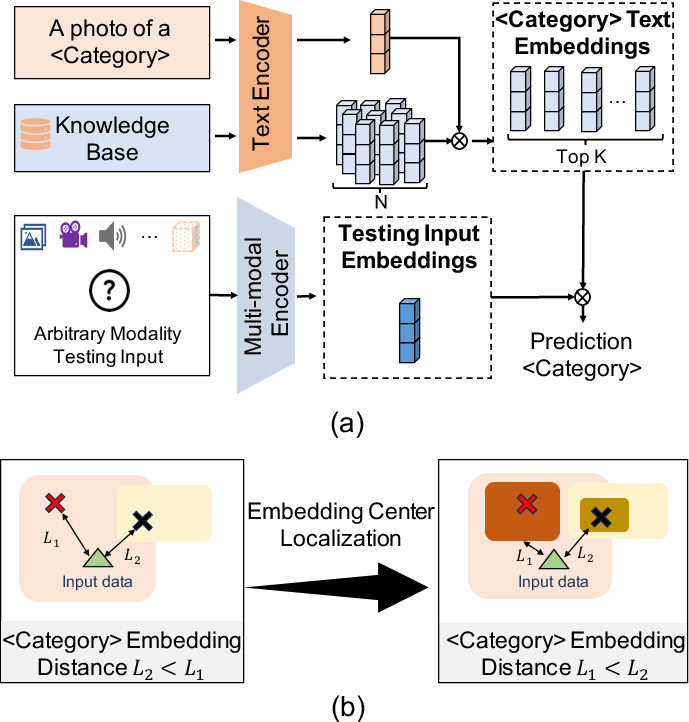
- Build a knowledge base with LLMs: The system asks LLMs (like GPT-4 and LLaMA) to write many detailed descriptions for each category (for example, many different ways to describe “helicopter”). It also uses multi-modal LLMs (like BLIP-2) to describe actual images, sounds, and other data. This is like creating a rich, well-written mini-encyclopedia for every concept.
- Create smarter “centers” for each category: Instead of using just the one-word label (like “airplane”), UniBind picks the top 50 most relevant descriptions from that knowledge base to represent the category. These descriptions become the category’s embedding center—like a cluster of landmarks, not just a single point. That makes the center more accurate and flexible.
- Align all modalities to these centers: The system learns so that any data about “airplane” (a picture, a sound, a video, a 3D shape) moves toward the same “airplane” center on the map. This is done with contrastive learning: pull together data that match the same description, push away those that don’t. Because the centers are based on language, they don’t favor images over audio or any other modality.
- Use small adapters, keep big models frozen: UniBind plugs into existing popular models (like CLIP and ImageBind) without retraining them from scratch. It freezes the big parts and only trains small, simple layers. That saves a lot of time and computer power.
- Make predictions with the centers: To recognize what something is, UniBind compares it to each category’s center (those 50 descriptive points) and picks the best match. This is more reliable than comparing to just a single label text.
What they found and why it matters
Across many tests (called “benchmarks”) and seven different modalities, UniBind consistently improved results. A few highlights:
- Better “zero-shot” performance: Zero-shot means recognizing things without extra training on that specific task. UniBind beat previous methods by about 6% on average across tasks. For example, it improved ImageNet results by around +5.5% in a zero-shot setting.
- Strong fine-tuning with fewer trainable parts: When allowed a little training, UniBind reached new state-of-the-art results. On the widely used ImageNet dataset, it improved accuracy by about +6.75% while reducing around 90% of the trainable parameters compared to typical setups. That means it’s both smarter and more efficient.
- Better cross-modal search: Searching from one type of data to another (like “find images that match this sound” or “find event data that match this text”) became much better. For one task, UniBind improved top-20 retrieval by nearly +18%. Results were also more balanced across types, not just dominated by images.
- First to include “event” data in this unified space: Event cameras record tiny changes in brightness very quickly (useful in robotics). UniBind successfully brought this new modality into the same shared space as text, images, and audio.
Why this is important and what it could change
- Fair to all data types: By using language as a neutral anchor, UniBind avoids making images the “default boss.” That helps the system understand complex scenes more fairly across modalities.
- Plug-and-play with popular models: UniBind can boost existing CLIP-style models without heavy retraining, making it practical to use in the real world.
- Smarter search and recognition: You could search for “a quiet street at night” and find matching images, videos, sounds, or thermal data—even if they were never directly paired during training.
- Useful across fields: This could help in accessibility (matching audio descriptions to visuals), robotics (combining sensors like cameras and event sensors), and security or safety systems (combining thermal, audio, and video).
- Future work: The authors note they want to improve robustness even more. Since UniBind leans on LLMs, making sure the descriptions are consistently reliable and unbiased will be important.
Quick analogies to remember
- The shared representation space is like a giant map; every piece of data gets a pin.
- The embedding centers are like good landmark clusters for each category, built from many helpful descriptions instead of just a single label.
- Contrastive learning is like organizing a messy room: put matching socks together (pull close), separate different socks (push apart).
- LLMs act like expert writers who give rich, varied descriptions so the system understands each category better.
Collections
Sign up for free to add this paper to one or more collections.