OmniBind: Teach to Build Unequal-Scale Modality Interaction for Omni-Bind of All
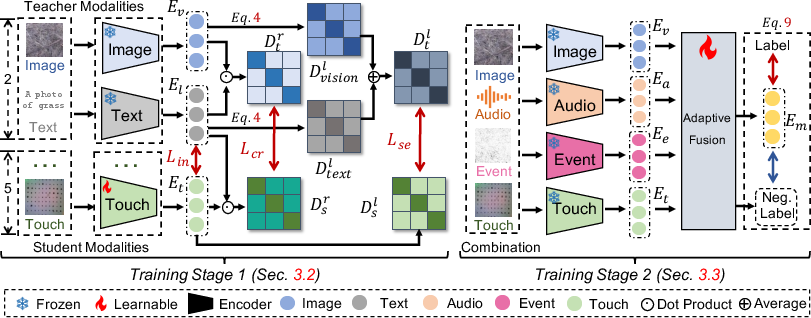
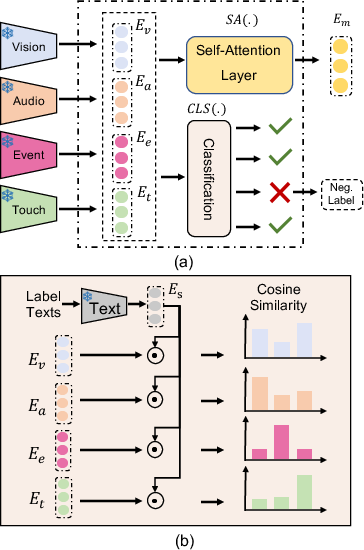
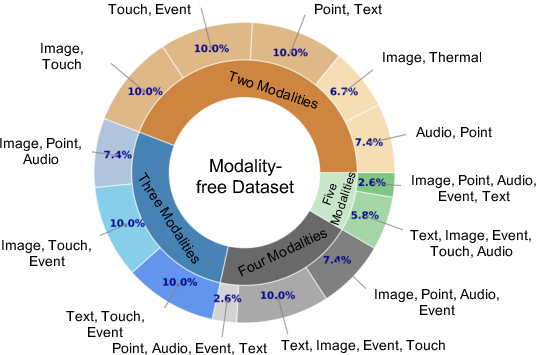
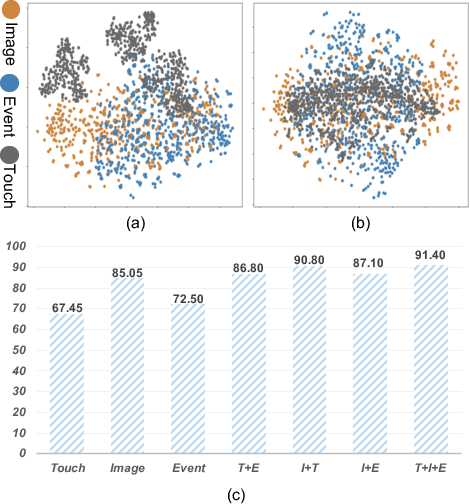
Abstract: Research on multi-modal learning dominantly aligns the modalities in a unified space at training, and only a single one is taken for prediction at inference. However, for a real machine, e.g., a robot, sensors could be added or removed at any time. Thus, it is crucial to enable the machine to tackle the mismatch and unequal-scale problems of modality combinations between training and inference. In this paper, we tackle these problems from a new perspective: "Modalities Help Modalities". Intuitively, we present OmniBind, a novel two-stage learning framework that can achieve any modality combinations and interaction. It involves teaching data-constrained, a.k.a, student, modalities to be aligned with the well-trained data-abundant, a.k.a, teacher, modalities. This subtly enables the adaptive fusion of any modalities to build a unified representation space for any combinations. Specifically, we propose Cross-modal Alignment Distillation (CAD) to address the unequal-scale problem between student and teacher modalities and effectively align student modalities into the teacher modalities' representation space in stage one. We then propose an Adaptive Fusion (AF) module to fuse any modality combinations and learn a unified representation space in stage two. To address the mismatch problem, we aggregate existing datasets and combine samples from different modalities by the same semantics. This way, we build the first dataset for training and evaluation that consists of teacher (image, text) and student (touch, thermal, event, point cloud, audio) modalities and enables omni-bind for any of them. Extensive experiments on the recognition task show performance gains over prior arts by an average of 4.05 % on the arbitrary modality combination setting. It also achieves state-of-the-art performance for a single modality, e.g., touch, with a 4.34 % gain.
- Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Advances in Neural Information Processing Systems, 35:32897–32912, 2022.
- Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358, 2021.
- Graph-based object classification for neuromorphic vision sensing. In Proceedings of the IEEE/CVF international conference on computer vision, pages 491–501, 2019.
- Clip2scene: Towards label-efficient 3d scene understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7030, 2023.
- Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- Cico: Domain-aware sign language retrieval via cross-lingual contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19016–19026, 2023.
- Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023.
- Vidloc: A deep spatio-temporal model for 6-dof video-clip relocalization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6856–6864, 2017.
- Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Multimodal sensors and ml-based data fusion for advanced robots. Advanced Intelligent Systems, 4(12):2200213, 2022.
- Clip2video: Mastering video-text retrieval via image clip. arXiv preprint arXiv:2106.11097, 2021.
- Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In 2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004.
- End-to-end learning of representations for asynchronous event-based data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5633–5643, 2019.
- Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023.
- Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023.
- Cross modal distillation for supervision transfer. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2827–2836, 2016.
- Audioclip: Extending clip to image, text and audio. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976–980. IEEE, 2022.
- Imagebind-llm: Multi-modality instruction tuning. arXiv preprint arXiv:2309.03905, 2023.
- A comprehensive overhaul of feature distillation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1921–1930, 2019.
- Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Clip2point: Transfer clip to point cloud classification with image-depth pre-training. arXiv preprint arXiv:2210.01055, 2022.
- Interactive multimodal robot programming. The international journal of robotics research, 24(1):83–104, 2005.
- Materials, actuators, and sensors for soft bioinspired robots. Advanced Materials, 33(19):2003139, 2021.
- Llvip: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3496–3504, 2021.
- Self-supervised visuo-tactile pretraining to locate and follow garment features. arXiv preprint arXiv:2209.13042, 2022.
- Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119–132, 2019.
- N-imagenet: Towards robust, fine-grained object recognition with event cameras. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2146–2156, 2021.
- Vit-lens: Towards omni-modal representations. arXiv preprint arXiv:2308.10185, 2023.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- Towards cross-modality medical image segmentation with online mutual knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 775–783, 2020.
- Frozen clip models are efficient video learners. In European Conference on Computer Vision, pages 388–404. Springer, 2022.
- Fourier prompt tuning for modality-incomplete scene segmentation. arXiv preprint arXiv:2401.16923, 2024.
- Universal vision-language dense retrieval: Learning a unified representation space for multi-modal retrieval. In The Eleventh International Conference on Learning Representations, 2022.
- Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022.
- Image anything: Towards reasoning-coherent and training-free multi-modal image generation. arXiv preprint arXiv:2401.17664, 2024.
- Unibind: Llm-augmented unified and balanced representation space to bind them all. arXiv preprint arXiv:2403.12532, 2024.
- Ave-clip: Audioclip-based multi-window temporal transformer for audio visual event localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5158–5167, 2023.
- Interactive multimodal learning environments: Special issue on interactive learning environments: Contemporary issues and trends. Educational psychology review, 19:309–326, 2007.
- Open vocabulary semantic segmentation with patch aligned contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19413–19423, 2023.
- Multimodal deep learning. In Proceedings of the 28th international conference on machine learning (ICML-11), pages 689–696, 2011.
- OpenAI. Gpt-4 technical report, 2023.
- Converting static image datasets to spiking neuromorphic datasets using saccades. Frontiers in neuroscience, 9:437, 2015.
- Relational knowledge distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3967–3976, 2019.
- Karol J Piczak. Esc: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, pages 1015–1018, 2015.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550, 2014.
- A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia, pages 1041–1044, 2014.
- Recent advancements in multimodal human–robot interaction. Frontiers in Neurorobotics, 17:1084000, 2023.
- Any-to-any generation via composable diffusion. Advances in Neural Information Processing Systems, 36, 2024.
- An efficient approach to informative feature extraction from multimodal data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 5281–5288, 2019.
- Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- Exploiting spatial sparsity for event cameras with visual transformers. In 2022 IEEE International Conference on Image Processing (ICIP), pages 411–415. IEEE, 2022.
- iclip: Bridging image classification and contrastive language-image pre-training for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2776–2786, 2023.
- Wav2clip: Learning robust audio representations from clip. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4563–4567. IEEE, 2022.
- Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519, 2023.
- 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015.
- Eventclip: Adapting clip for event-based object recognition. arXiv preprint arXiv:2306.06354, 2023.
- Hidanet: Rgb-d salient object detection via hierarchical depth awareness. IEEE Transactions on Image Processing, 32:2160–2173, 2023.
- Knowledge distillation meets self-supervision. In European Conference on Computer Vision, pages 588–604. Springer, 2020.
- Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016.
- Progress and prospects of multimodal fusion methods in physical human–robot interaction: A review. IEEE Sensors Journal, 20(18):10355–10370, 2020.
- Cross-image relational knowledge distillation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12319–12328, 2022.
- Binding touch to everything: Learning unified multimodal tactile representations. arXiv preprint arXiv:2401.18084, 2024.
- Touch and go: Learning from human-collected vision and touch. arXiv preprint arXiv:2211.12498, 2022.
- Improving visual grounding with visual-linguistic verification and iterative reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9499–9508, 2022.
- Knowledge transfer via dense cross-layer mutual-distillation. European Conference on Computer Vision, 2020.
- All-printed soft human-machine interface for robotic physicochemical sensing. Science robotics, 7(67):eabn0495, 2022.
- Cmx: Cross-modal fusion for rgb-x semantic segmentation with transformers. IEEE Transactions on Intelligent Transportation Systems, 2023.
- Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5579–5588, 2021.
- Fmcnet: Feature-level modality compensation for visible-infrared person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7349–7358, 2022.
- Pointclip: Point cloud understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8552–8562, 2022.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Meta-transformer: A unified framework for multimodal learning. arXiv preprint arXiv:2307.10802, 2023.
- Learning unseen modality interaction. Advances in Neural Information Processing Systems, 36, 2024.
- Arkittrack: a new diverse dataset for tracking using mobile rgb-d data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5126–5135, 2023.
- Knowledge as priors: Cross-modal knowledge generalization for datasets without superior knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6528–6537, 2020.
- Cvt-slr: Contrastive visual-textual transformation for sign language recognition with variational alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23141–23150, 2023.
- Xu Zheng and Lin Wang. Eventdance: Unsupervised source-free cross-modal adaptation for event-based object recognition. arXiv preprint arXiv:2403.14082, 2024.
- E-clip: Towards label-efficient event-based open-world understanding by clip. arXiv preprint arXiv:2308.03135, 2023.
- Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 13041–13049, 2020.
- Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. arXiv preprint arXiv:2310.01852, 2023.
- Pointclip v2: Adapting clip for powerful 3d open-world learning. arXiv preprint arXiv:2211.11682, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.