MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs
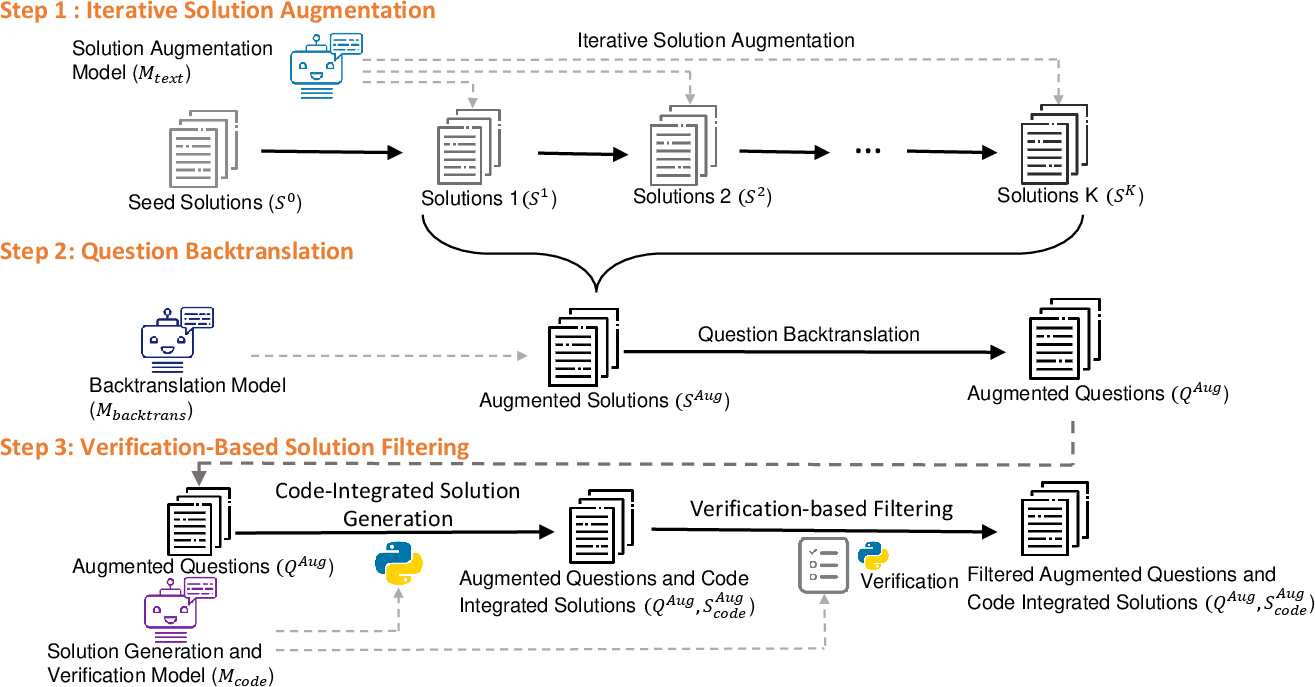
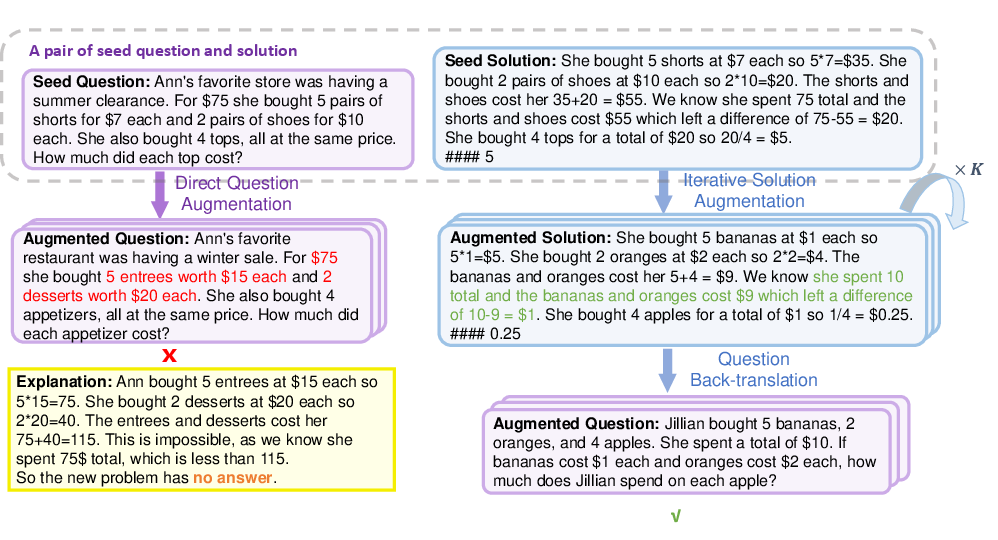
Abstract: LLMs have exhibited great potential in mathematical reasoning. However, there remains a performance gap in this area between existing open-source models and closed-source models such as GPT-4. In this paper, we introduce MathGenie, a novel method for generating diverse and reliable math problems from a small-scale problem-solution dataset (denoted as seed data). We augment the ground-truth solutions of our seed data and train a back-translation model to translate the augmented solutions back into new questions. Subsequently, we generate code-integrated solutions for the new questions. To ensure the correctness of the code-integrated solutions, we employ rationale-based strategy for solution verification. Various pretrained models, ranging from 7B to 70B, are trained on the newly curated data to test the effectiveness of the proposed augmentation technique, resulting in a family of models known as MathGenieLM. These models consistently outperform previous open-source models across five representative mathematical reasoning datasets, achieving state-of-the-art performance. In particular, MathGenieLM-InternLM2 achieves an accuracy of 87.7% on GSM8K and 55.7% on MATH, securing the best overall score among open-source LLMs.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Advancing mathematics by guiding human intuition with ai. Nature, 600:70 – 74.
- Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452.
- Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
- Mistral 7b. arXiv preprint arXiv:2310.06825.
- Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Mawps: A math word problem repository. In North American Chapter of the Association for Computational Linguistics.
- Query and response augmentation cannot help out-of-domain math reasoning generalization. arXiv preprint arXiv:2310.05506.
- Self-alignment with instruction backtranslation. arXiv preprint arXiv:2308.06259.
- Haoxiong Liu and Andrew Chi-Chih Yao. 2024. Augmenting math word problems via iterative question composing. arXiv preprint arXiv:2401.09003.
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583.
- Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
- OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Are nlp models really able to solve simple math word problems? arXiv preprint arXiv:2103.07191.
- Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- InternLM Team. 2023. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM-techreport.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. In International Conference on Learning Representations.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825.
- Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653.
- Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification. In International Conference on Learning Representations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.