- The paper introduces a novel framework combining LLMs and GNNs through role-specific templates to encode graph structures without altering LLM parameters.
- It employs a projector that maps graph node sequences into LLM token spaces, enabling effective multi-task learning for node classification and link prediction.
- Experimental results show superior performance and interpretability, demonstrating robust zero-shot generalization across diverse datasets.
LLaGA: Large Language and Graph Assistant
The exploration into the combination of LLMs and Graph Neural Networks (GNNs) has brought about new methodologies to handle graph-structured data with enhanced versatility and generalization. The paper introduces the Large Language and Graph Assistant (LLaGA), which treads this emerging path by implementing a framework that effectively encodes graph structures as inputs for LLMs without altering their parameters.
Introduction to LLaGA
LLaGA addresses the challenge of applying LLMs to graph data, aiming for seamless integration that allows these models to maintain their proficiency across various non-graph tasks. By bridging graph and token spaces, LLaGA allows for the utilization of LLMs in traditional graph machine learning tasks such as node classification and link prediction. This is achieved through a combination of novel methodologies: converting graph data into sequences that preserve structural and semantic information, and employing a projector to align these sequences within the LLM's input space.
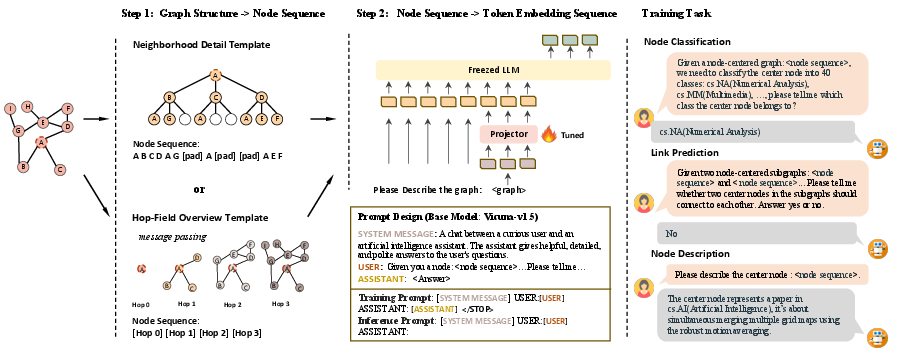
Figure 1: Illustration of LLaGA framework and its prompt design paradigm.
Methodology
Structure-Aware Graph Translation
LLaGA's approach to translating graph inputs into LLM-compatible formats involves two innovative role-specific templates: the Neighborhood Detail Template and the Hop-Field Overview Template. These templates facilitate the conversion of graph structures into sequence formats. The Neighborhood Detail Template captures detailed local information around a node by constructing a fixed-shaped computational tree centered on the node. On the other hand, the Hop-Field Overview Template provides a broader summarization of node neighborhoods through parameter-free message passing across various hops.
After generating these node sequences, a versatile projector maps them into the token embedding space comprehensible to the LLMs. This mapping aligns the graph data with the LLM's native formats, enabling efficient interpretation without modifying the LLM's inherent structure.
Training and Tasks
The training of LLaGA involves multi-task learning encompassing node classification, link prediction, and node description tasks. This ensures that the projector is finely tuned to handle diverse graph tasks, effectively leveraging LLMs' abilities for semantic interpretation and comprehensive understanding of the graph data. The training paradigm emphasizes the alignment between graph structures and token spaces, fostering the model's ability to generalize across unseen datasets and tasks.
Experimental Results
LLaGA was evaluated against various baselines, including traditional GNNs and other LLM-based frameworks like GraphGPT. LLaGA demonstrated superior performance across multiple tasks and datasets, notably excelling in multi-task settings where other models tend to degrade. The experiments utilized datasets such as Cora, Pubmed, Arxiv, and Products, underscoring LLaGA's versatility and robustness. In zero-shot settings, LLaGA showed a remarkable ability to generalize across domains, which further highlighted its potential in handling previously unseen graph tasks or datasets.
Interpretability
An essential feature of LLaGA is its capacity to generate interpretable insights and explanations for node embeddings. This interpretability is measured through tasks like node description, where LLaGA provides semantically rich explanations, often aligning with human expert interpretations. The framework also supports zero-shot and detailed insights into the decision-making processes of node embeddings, further establishing its utility in real-world applications.
Conclusion
LLaGA emerges as a pioneering framework capable of integrating LLMs into the field of graph machine learning effectively. Its innovative approach to encoding graph structures for LLM consumption, coupled with a robust projector for graph-token alignment, sets a new standard in the flexibility and applicability of LLMs to diverse data forms. Future work may focus on enhancing scalability to even larger datasets and further expanding the framework to include additional tasks beyond traditional node and link prediction, driving broader adoption in AI applications that demand high versatility and robust interpretability.

