- The paper sets a hierarchical taxonomy for visual text processing by distinguishing between enhancement/restoration and manipulation tasks.
- It reviews reconstruction-based and generative learning paradigms, leveraging deep models such as GANs and diffusion models for effective text enhancement.
- The survey benchmarks key performance metrics like PSNR, SSIM, and FID, while outlining open challenges such as limited annotated datasets.
Visual Text Meets Low-Level Vision: A Comprehensive Survey on Visual Text Processing
Introduction
The paper "Visual Text Meets Low-level Vision: A Comprehensive Survey on Visual Text Processing" provides a detailed survey of visual text processing, focusing on the integration of visual text features within the context of low-level vision tasks. Visual text, a critical component in both document and scene images, plays a significant role across various applications like image retrieval and scene understanding. This survey addresses the challenges unique to visual text processing, sets a hierarchical taxonomy of tasks, and reviews learning paradigms and datasets, while also highlighting open challenges for future exploration.

Figure 1: Visualization samples of visual text processing tasks, illustrating text image enhancement/restoration, including super-resolution, dewarping, and denoising, and text image manipulation, such as text removal, editing, and generation.
Taxonomy and Learning Paradigms
The survey introduces a hierarchical taxonomy that categorizes visual text processing into text image enhancement/restoration and text image manipulation (Figure 2). Enhancement and restoration tasks focus on improving text clarity and image quality through super-resolution, dewarping, and denoising. Manipulation tasks focus on altering text content and style, involving text removal, editing, and generation.
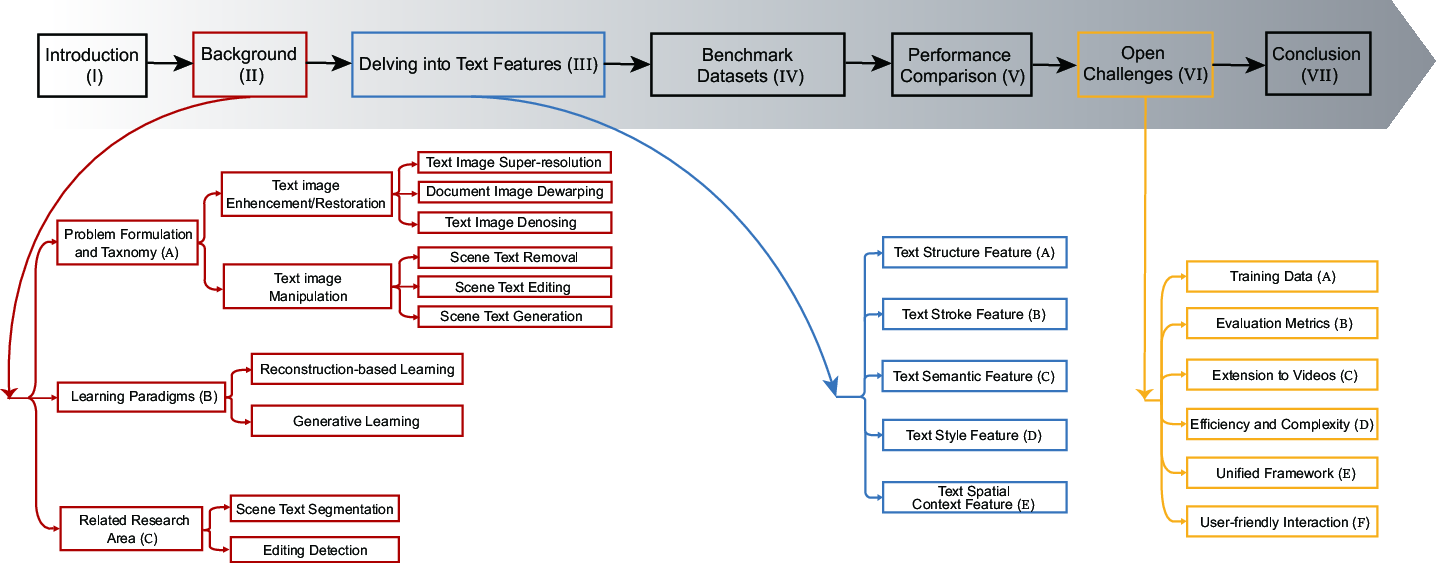
Figure 2: Main structure of this survey, detailing the hierarchical taxonomy ranging from image enhancement/restoration to image manipulation, followed by different learning paradigms.
The study identifies reconstruction-based learning and generative learning as the primary learning paradigms. Reconstruction-based methods focus on restoring text images by learning an optimal mapping function to enhance image quality. In contrast, generative learning leverages models like GANs and diffusion models to create new, realistic data, enabling robust text manipulation and generation.
Text Features in Processing
The paper emphasizes the importance of effectively integrating text-specific features—such as structure, stroke, semantics, style, and spatial context (Table 1)—in visual text processing. These features can be seamlessly integrated using various deep-learning models to enhance task performance.
Datasets and Benchmarking
A core section of the survey reviews widely-used datasets for benchmarking visual text processing methods, emphasizing the need for extensive, high-quality annotated data. The survey outlines key datasets like TextZoom for super-resolution and various synthetic datasets for manipulation tasks, highlighting the scarcity of large, annotated datasets as a critical challenge.
The survey summarizes performance metrics for benchmarking visual text processing methods. Evaluation metrics such as PSNR, SSIM, and FID are used to assess quality in enhancement/restoration and manipulation tasks, while recognition accuracy and detection results are used to gauge the effectiveness of synthetic datasets in training deep learning models.
Open Challenges
Challenges in the field include the limited availability of annotated datasets, inefficiencies in current architectures, and the need for unified frameworks that address multiple tasks simultaneously. Future directions call for improved evaluation metrics, more extensive dataset coverage, and user-friendly interfaces that tailor processing to individual needs, indicating significant potential for innovation in efficient model design and multi-task learning approaches.
Conclusion
This survey presents a comprehensive overview of the current landscape in visual text processing, underlining the importance of leveraging unique textual features within vision tasks. By establishing a structured overview of learning paradigms, datasets, and open challenges, it seeks to facilitate further advancements and inspire innovative solutions in this dynamic research area.