- The paper surveys the application of large language models, vision-language models, and embodied agents to provide guidance for visually impaired individuals.
- It benchmarks zero-shot performance using a new evaluation dataset based on VQA, assessed with both automatic metrics and human evaluations.
- Experiment results highlight GPT-4’s strong semantic abilities versus smaller models’ concise outputs, emphasizing the need for improved multimodal integration.
VIALM: A Survey and Benchmark of Visually Impaired Assistance with Large Models
Introduction
The paper, "VIALM: A Survey and Benchmark of Visually Impaired Assistance with Large Models", investigates the application of large models (LMs) in Visually Impaired Assistance (VIA), which seeks to help visually impaired (VI) individuals manage their daily activities autonomously. The study explores the capabilities of state-of-the-art (SOTA) LMs to assist VI users by providing environment-grounded and fine-grained guidance through images and linguistic inputs.
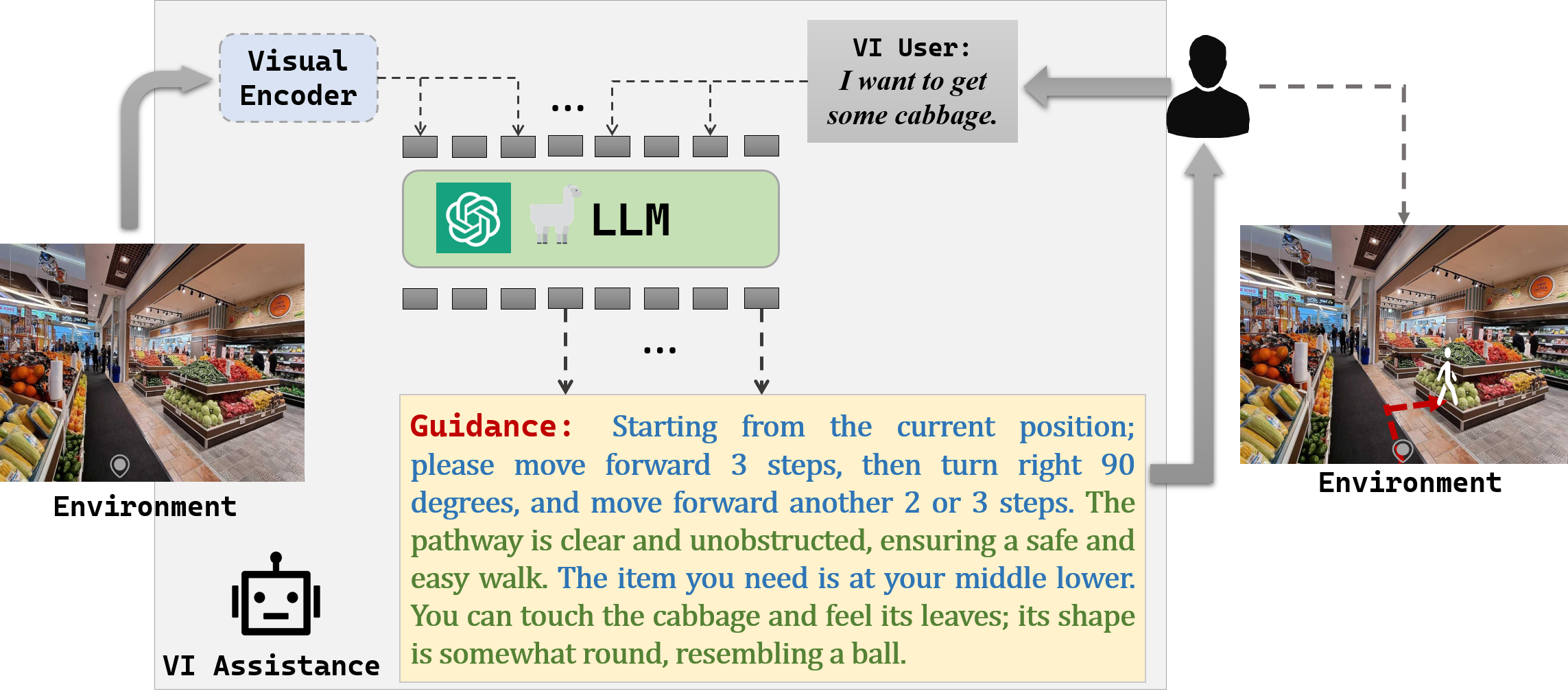
Figure 1: An illustration of VIALM input and output, showing the guidance for VI users completing tasks within an environment.
Large Models for Visually Impaired Assistance
The paper provides a comprehensive survey of LLMs, large vision-LLMs (VLMs), and embodied agents, detailing their potential applications in VIA. It highlights the roles these models play, such as processing multimodal inputs and generating accessible outputs to aid VI users.
Figure 2: A timeline of large models depicting the evolution from LLMs to VLMs and embodied agents.
LLMs
LLMs exhibit emergent abilities beneficial for VIA tasks, particularly in reasoning and decision-making. These models, which often comprise more than 10 billion parameters, demonstrate advanced instruction-tuning capabilities, allowing for improved alignment with user intentions.
Large Vision-LLMs
VLMs integrate visual and linguistic modalities, enabling them to perform tasks like image captioning and Visual Question Answering (VQA). These models are pivotal in creating accessible textual guidance for VI users by understanding and processing environmental images alongside language requests.
Embodied Agents
Embodied agents extend the utility of LMs by interacting with environments, perceiving surroundings, and executing tasks. Such agents, particularly those based on large models, leverage language comprehension to facilitate autonomous actions, with relevance to real-world applications and interactions beneficial to VI users.
Benchmark Evaluation
The study introduces a benchmark dataset designed to evaluate the zero-shot performance of SOTA LMs in VIA tasks. The dataset follows the VQA framework, consisting of images and questions paired with guidance answers, particularly focusing on common environments like homes and supermarkets.

Figure 3: An example from the evaluation dataset, illustrating the test format with an image and a question.
Evaluation Metrics
The evaluation utilizes automatic and human metrics to analyze model outputs. Automatic metrics like ROUGE and BERTScore assess token overlap and semantic similarity, while human evaluation measures correctness, actionability, and clarity.
Experiment Results
The experiments reveal significant limitations in current models, notably their inability to produce grounded and fine-grained guidance consistently. While GPT-4 shows higher semantic capabilities, it often generates lengthy outputs that lack specific environment grounding. Conversely, smaller models excel in providing concise guidance but struggle to incorporate tactile information and detailed step-by-step processes.
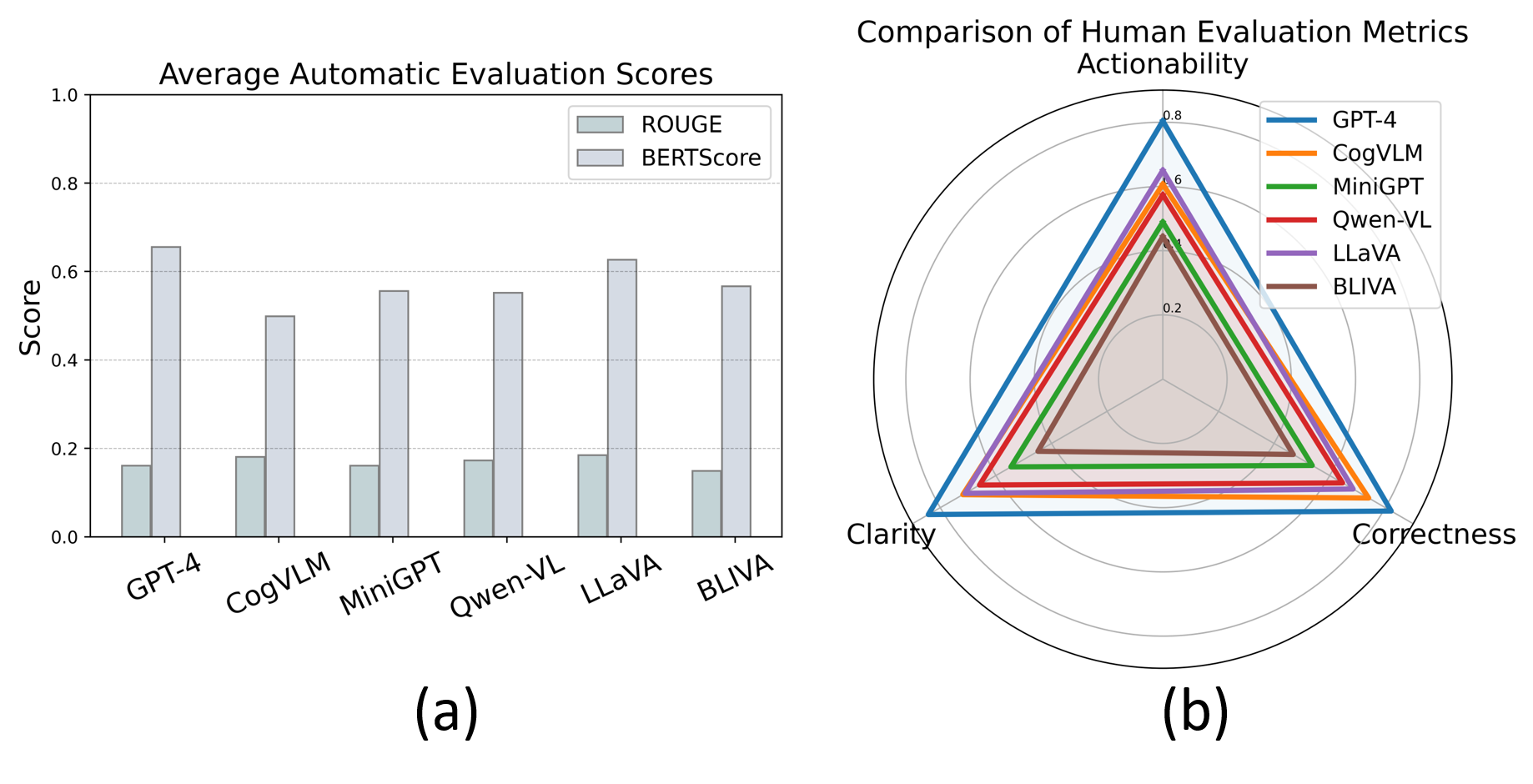
Figure 4: Evaluation results including automatic and human assessment scores across various models.
Case Study and Discussion
Analysis of model outputs indicates potential strategies for improvement. Specifically, enhancing visual capabilities and refining LLM components could address the limitations observed in grounding and fine-grained guidance generation.

Figure 5: Predictions from top models showing differences in approach, with GPT-4 generating lengthy outputs and CogVLM achieving better image grounding.
Conclusion
The paper outlines the potential and constraints of using large models in VIA applications. Future advancements in multimodal integration are essential to develop models capable of providing nuanced and environment-grounded assistance to visually impaired individuals. The study highlights the need for improved synergy between vision and language components to enhance usability for VI users.