Synthetic Data Applications in Finance
Abstract: Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
- Faster rates of convergence to stationary points in differentially private optimization. In International Conference on Machine Learning, pages 1060–1092. PMLR, 2023.
- Wasserstein generative adversarial networks. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 214–223. PMLR, 06–11 Aug 2017.
- Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, oct 2016.
- Generative time-series modeling with fourier flows. In International Conference on Learning Representations, 2020.
- Generating synthetic data in finance: opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, pages 1–8, 2020.
- Multi-channel attribution: The blind spot of online advertising. Available at SSRN 2959778, 2017.
- Differentially private release of high-dimensional datasets using the gaussian copula, 2019.
- Deep neural net with attention for multi-channel multi-touch attribution. arXiv preprint arXiv:1809.02230, 2018.
- Bayesian networks for spatial learning: a workflow on using limited survey data for intelligent learning in spatial agent-based models. Geoinformatica, 23:243–268, 2019.
- Agent based modelling and simulation tools: A review of the state-of-art software. Computer Science Review, 24:13–33, 2017.
- How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. arXiv preprint arXiv:2102.08921, 2021.
- Phantom–an rl-driven framework for agent-based modeling of complex economic systems and markets. arXiv preprint arXiv:2210.06012, 2022.
- Trades, quotes and prices: financial markets under the microscope. Cambridge University Press, 2018.
- Essentially, all models are wrong, but some are useful. Statistician, 3(28):2013, 1919.
- Mads: Modulated auto-decoding siren for time series imputation. ArXiv, abs/2307.00868, 2023.
- Abides: Towards high-fidelity market simulation for AI research. arXiv preprint arXiv:1904.12066, 2019.
- How to evaluate trading strategies: Single agent market replay or multiple agent interactive simulation? arXiv preprint arXiv:1906.12010, 2019.
- Statistical inference for probabilistic functions of finite state markov chains. The annals of mathematical statistics, 37(6):1554–1563, 1966.
- Markov decision processes with applications to finance. Springer Science & Business Media, 2011.
- Paolo Brandimarte. Handbook in Monte Carlo simulation: applications in financial engineering, risk management, and economics. John Wiley & Sons, 2014.
- Domain-independent generation and classification of behavior traces. arXiv e-prints, abs/2011.02918, 2020.
- Markov decision processes in practice, volume 248. Springer, 2017.
- Simulating and classifying behavior in adversarial environments based on action-state traces: An application to money laundering. In Proceedings of the First ACM International Conference on AI in Finance, New York (EEUU), 2020. Also in: https://arxiv.org/abs/2011.01826.
- Bizgraphqa: A dataset for image-based inference over graph-structured diagrams from business domains. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023.
- David Byrd. Explaining agent-based financial market simulation. CoRR, abs/1909.11650, 2019.
- Data incubation—synthesizing missing data for handwriting recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4188–4192. IEEE, 2022.
- Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
- Finqa: A dataset of numerical reasoning over financial data. 2021.
- Dslob: A synthetic limit order book dataset for benchmarking forecasting algorithms under distributional shift, 2022.
- Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016.
- On the constrained time-series generation problem. In NeurIPS, 2023.
- D Chorafas. Financial models and simulation. Springer, 1995.
- Point processes, volume 12. CRC Press, 1980.
- Erhan Cinlar. Introduction to stochastic processes. Courier Corporation, 2013.
- Conditional generators for limit order book environments: Explainability, challenges, and robustness. arXiv preprint arXiv:2306.12806, 2023.
- Market making and mean reversion. pages 307–314, 06 2011.
- Hawkes process modeling of covid-19 with mobility leading indicators and spatial covariates. International journal of forecasting, 38(2):505–520, 2022.
- Learning continuous image representation with local implicit image function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8628–8638, 2021.
- Learning to simulate realistic limit order book markets from data as a world agent. In Proceedings of the Third ACM International Conference on AI in Finance, pages 428–436, 2022.
- David R Cox. Some statistical methods connected with series of events. Journal of the Royal Statistical Society: Series B (Methodological), 17(2):129–157, 1955.
- Towards realistic market simulations: a generative adversarial networks approach. In Proceedings of the Second ACM International Conference on AI in Finance, pages 1–9, 2021.
- Random forests for generating partially synthetic, categorical data. Trans. Data Priv., 3(1):27–42, 2010.
- Unlabeled data improves adversarial robustness. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- Style equalization: Unsupervised learning of controllable generative sequence models. In International Conference on Machine Learning, pages 2917–2937. PMLR, 2022.
- K-shap: Policy clustering algorithm for anonymous state-action pairs. arXiv preprint arXiv:2302.11996, 2023.
- Brits: Bidirectional recurrent imputation for time series. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
- Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2020.
- Timevae: A variational auto-encoder for multivariate time series generation. arXiv preprint arXiv:2111.08095, 2021.
- Efficient generation of structured objects with constrained adversarial networks. Advances in neural information processing systems, 33:14663–14674, 2020.
- Chataug: Leveraging chatgpt for text data augmentation. arXiv preprint arXiv:2302.13007, 2023.
- Implicit generation and modeling with energy based models. Advances in Neural Information Processing Systems, 32, 2019.
- Carl Doersch. Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908, 2016.
- CORE: A retrieve-then-edit framework for counterfactual data generation. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2964–2984, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.
- The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci., 9(3-4):211–407, 2014.
- An introduction to the theory of point processes: volume I: elementary theory and methods. Springer, 2003.
- Exact simulation of Hawkes process with exponentially decaying intensity. Electronic Communications in Probability, 18(none):1 – 13, 2013.
- Improving adversarial robustness via unlabeled out-of-domain data. In Arindam Banerjee and Kenji Fukumizu, editors, Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 2845–2853. PMLR, 13–15 Apr 2021.
- Real-valued (medical) time series generation with recurrent conditional gans. arXiv preprint arXiv:1706.02633, 2017.
- Real-valued (medical) time series generation with recurrent conditional gans, 2017.
- Modelling extremal events: for insurance and finance, volume 33. Springer Science & Business Media, 2013.
- Deep gaussian mixture ensembles. arXiv preprint arXiv:2306.07235, 2023.
- Styletime: Style transfer for synthetic time series generation. In Proceedings of the Third ACM International Conference on AI in Finance, pages 489–496, 2022.
- A synthetic recipe for ocr. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 864–869. IEEE, 2019.
- Generating synthetic data to match data mining patterns. IEEE Internet Computing, 12(3):78–82, 2008.
- Predicting customer goals in financial institution services: A data-driven LSTM approach. In ICAPS Planning for Financial Services Workshop, 2023.
- Scrabblegan: Semi-supervised varying length handwritten text generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4324–4333, 2020.
- Adaptive weighting scheme for automatic time-series data augmentation, 2021.
- Evaluating data augmentation for financial time series classification. arXiv preprint arXiv:2010.15111, 2020.
- Augmenting transferred representations for stock classification. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3915–3919, 2021.
- https://www.federalreserve.gov/publications/2023-stress-test-scenarios.htm.
- Knowledge based simulation: an artificial intelligence approach to system modeling and automating the simulation life cycle. Carnegie Mellon University, the Robotics Institute, 1988.
- Hypertime: Implicit neural representation for time series. ArXiv, abs/2208.05836, 2022.
- A survey of sequential pattern mining. Data Science and Pattern Recognition, 1(1):54–77, 2017.
- Synthetic data generation with probabilistic bayesian networks. Mathematical biosciences and engineering: MBE, 18(6):8603, 2021.
- Online learning for mixture of multivariate hawkes processes. In Proceedings of the Third ACM International Conference on AI in Finance, ICAIF ’22, page 506–513, New York, NY, USA, 2022. Association for Computing Machinery.
- Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pages 1050–1059. PMLR, 2016.
- Zoubin Ghahramani. Learning dynamic bayesian networks. International School on Neural Networks, Initiated by IIASS and EMFCSC, pages 168–197, 1997.
- Differentially private learning of hawkes processes. 2022.
- Layouttransformer: Layout generation and completion with self-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1004–1014, 2021.
- Automated Planning. Theory & Practice. Morgan Kaufmann, 2004.
- Ian Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
- Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014.
- Generative adversarial networks, 2014.
- Alex Graves. Practical variational inference for neural networks. Advances in neural information processing systems, 24, 2011.
- Objective-reinforced generative adversarial networks (organ) for sequence generation models. arXiv preprint arXiv:1705.10843, 2017.
- Dp-merf: Differentially private mean embeddings with random features for practical privacy-preserving data generation, 2021.
- Alan G Hawkes. Spectra of some self-exciting and mutually exciting point processes. Biometrika, 58(1):83–90, 1971.
- Thomas Hegghammer. Ocr with tesseract, amazon textract, and google document ai: a benchmarking experiment. Journal of Computational Social Science, 5(1):861–882, 2022.
- Population based augmentation: Efficient learning of augmentation policy schedules. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2731–2741. PMLR, 09–15 Jun 2019.
- A supervised generative optimization approach for tabular data. In 4th ACM International Conference on AI in Finance, pages 10–18, 2023.
- Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- Stefano M Iacus et al. Simulation and inference for stochastic differential equations: with R examples, volume 486. Springer, 2008.
- An empirical survey of data augmentation for time series classification with neural networks. PLOS ONE, 16(7):e0254841, Jul 2021.
- A self-correcting point process. Stochastic processes and their applications, 8(3):335–347, 1979.
- Neural jump stochastic differential equations. Advances in Neural Information Processing Systems, 32, 2019.
- Hyperimpute: Generalized iterative imputation with automatic model selection. 2022.
- Layoutvae: Stochastic scene layout generation from a label set. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9895–9904, 2019.
- Synthetic data – what, why and how?, 2022.
- Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. Transactions of the ASME–Journal of Basic Engineering, 82(Series D):35–45, 1960.
- Jonathan Katz. Digital signatures, volume 1. Springer, 2010.
- Tabddpm: Modelling tabular data with diffusion models. In International Conference on Machine Learning, pages 17564–17579. PMLR, 2023.
- Multichannel marketing attribution using markov chains. Journal of Applied Management and Investments, 7(1):49–60, 2018.
- A watermark for large language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 17061–17084. PMLR, 23–29 Jul 2023.
- Deepfakes: Trick or treat? Business Horizons, 63(2):135–146, 2020.
- Figureqa: An annotated figure dataset for visual reasoning. arXiv preprint arXiv:1710.07300, 2017.
- Differentially private synthetic data using KD-trees. In The 39th Conference on Uncertainty in Artificial Intelligence, 2023.
- Vikram Krishnamurthy. Partially observed Markov decision processes. Cambridge university press, 2016.
- A diagram is worth a dozen images. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 235–251. Springer, 2016.
- MMD GAN: towards deeper understanding of moment matching network. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 2203–2213, 2017.
- Blake LeBaron. Agent-based computational finance. Handbook of computational economics, 2:1187–1233, 2006.
- Data augmentation approaches in natural language processing: A survey. AI Open, 3:71–90, 2022.
- Fast autoaugment. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32, pages 6665–6675. Curran Associates, Inc., 2019.
- Graphmaker: Can diffusion models generate large attributed graphs? arXiv preprint arXiv:2310.13833, 2023.
- Graph neural networks for temporal graphs: State of the art, open challenges, and opportunities. Transactions on Machine Learning Research, 2023.
- An empirical analysis of synthetic-data-based anomaly detection. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction, pages 306–327. Springer, 2022.
- Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017.
- Fairgan: Gans-based fairness-aware learning for recommendations with implicit feedback. In Proceedings of the ACM Web Conference 2022, pages 297–307, 2022.
- A survey of transformers. AI Open, 2022.
- Summary statistic privacy in data sharing, 2023.
- Differentially private synthesization of multi-dimensional data using copula functions. Advances in database technology : proceedings. International Conference on Extending Database Technology, 2014:475–486, 2014.
- Multi-task multi-dimensional hawkes processes for modeling event sequences. In Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’15, page 3685–3691, 2015.
- Layoutgan: Synthesizing graphic layouts with vector-wireframe adversarial networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(7):2388–2399, 2020.
- Sync: A copula based framework for generating synthetic data from aggregated sources. In 2020 International Conference on Data Mining Workshops (ICDMW), pages 571–578. IEEE, 2020.
- On the usefulness of synthetic tabular data generation, 2023.
- Odile Macchi. The coincidence approach to stochastic point processes. Advances in Applied Probability, 7(1):83–122, 1975.
- Infographicvqa. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022.
- A look into causal effects under entangled treatment in graphs: Investigating the impact of contact on MRSA infection. In KDD Conference. Applied Data Science Track, 2023.
- A taxonomy of sequential pattern mining algorithms. ACM Computing Surveys (CSUR), 43(1):1–41, 2010.
- Takanobu Mizuta. A brief review of recent artificial market simulation (agent-based model) studies for financial market regulations and/or rules. Available at SSRN 2710495, 2016.
- Ornstein–uhlenbeck processes and extensions. Handbook of financial time series, pages 421–437, 2009.
- A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6):1–35, 2021.
- Generate your counterfactuals: Towards controlled counterfactual generation for text. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13516–13524, 2021.
- Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- Kevin Patrick Murphy. Dynamic bayesian networks: representation, inference and learning. University of California, Berkeley, 2002.
- Gaussian copula marginal regression. 2012.
- Paul Newbold. Arima model building and the time series analysis approach to forecasting. Journal of forecasting, 2(1):23–35, 1983.
- How to break anonymity of the netflix prize dataset, 2007.
- Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
- Deep generative models: Survey. In 2018 International conference on intelligent systems and computer vision (ISCV), pages 1–8. IEEE, 2018.
- Yosihiko Ogata. On lewis’ simulation method for point processes. IEEE transactions on information theory, 27(1):23–31, 1981.
- Yosihiko Ogata. Space-time point-process models for earthquake occurrences. Annals of the Institute of Statistical Mathematics, 50:379–402, 1998.
- Dynamic data augmentation with gating networks for time series recognition. In 2022 26th International Conference on Pattern Recognition (ICPR), pages 3034–3040, Los Alamitos, CA, USA, aug 2022. IEEE Computer Society.
- OpenAI. Gpt-4 technical report, 2023.
- Semi-supervised knowledge transfer for deep learning from private training data, 2017.
- Dynamic calibration of order flow models with generative adversarial networks. In Proceedings of the Third ACM International Conference on AI in Finance, pages 446–453, 2022.
- Quantum quantile mechanics: solving stochastic differential equations for generating time-series. arXiv preprint arXiv:2108.03190, 2021.
- Automatic generation of scientific papers for data augmentation in document layout analysis. Pattern Recognition Letters, 167:38–44, 2023.
- Mutually exciting point process graphs for modeling dynamic networks. Journal of Computational and Graphical Statistics, pages 1–15, 2022.
- Data synthesis based on generative adversarial networks. Proceedings of the VLDB Endowment, 11(10):1071–1083, jun 2018.
- Finrddl: Can ai planning be used for quantitative finance problems? FinPlan 2023, 2023.
- Datasynthesizer: Privacy-preserving synthetic datasets. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management, pages 1–5, 2017.
- Model explanations with differential privacy. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1895–1904, 2022.
- Martin L Puterman. Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014.
- The synthetic data vault. In 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pages 399–410. IEEE, 2016.
- The synthetic data vault. In 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pages 399–410, 2016.
- Alex Reinhart. A review of self-exciting spatio-temporal point processes and their applications. Statistical Science, 33(3):299–318, 2018.
- Self-exciting point processes with spatial covariates. Journal of the Royal Statistical Society. Series C (Applied Statistics), 67(5):1305–1329, 2018.
- Epistemic parity: Reproducibility as an evaluation metric for differential privacy. arXiv preprint arXiv:2208.12700, 2022.
- An introduction to hidden markov models. ieee assp magazine, 3(1):4–16, 1986.
- Hawkes processes for events in social media. In Frontiers of multimedia research, pages 191–218. 2017.
- Differentially private synthetic data: Applied evaluations and enhancements, 2020.
- Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- Spatially-adaptive pixelwise networks for fast image translation. In Computer Vision and Pattern Recognition (CVPR), 2021.
- Synthetic document generator for annotation-free layout recognition. Pattern Recognition, 128:108660, 2022.
- Rare event simulation using Monte Carlo methods, volume 73. Wiley Online Library, 2009.
- Scott Sanner et al. Relational dynamic influence diagram language (rddl): Language description. Unpublished ms. Australian National University, 32:27, 2010.
- Assessing generative models via precision and recall. Advances in neural information processing systems, 31, 2018.
- An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11):2298–2304, 2016.
- Neural stochastic agent-based limit order book simulation: A hybrid methodology. arXiv preprint arXiv:2303.00080, 2023.
- When flue meets flang: Benchmarks and large pretrained language model for financial domain. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2322–2335, 2022.
- Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
- Fairness gan: Generating datasets with fairness properties using a generative adversarial network. IBM Journal of Research and Development, 63(4/5):3–1, 2019.
- Falsification of learning-based controllers through multi-fidelity bayesian optimization. In 2023 European Control Conference (ECC), pages 1–6. IEEE, 2023.
- Implicit neural representations with periodic activation functions. In Proc. NeurIPS, 2020.
- Robust learning meets generative models: Can proxy distributions improve adversarial robustness? In International Conference on Learning Representations, 2022.
- Membership inference attacks against machine learning models. CoRR, abs/1610.05820, 2016.
- Extended k-anonymity models against sensitive attribute disclosure. Computer Communications, 34(4):526–535, 2011. Special issue: Building Secure Parallel and Distributed Networks and Systems.
- Adversarial attacks against deep generative models on data: A survey. IEEE Transactions on Knowledge and Data Engineering, 35(4):3367–3388, apr 2023.
- Fair generative models via transfer learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 2429–2437, 2023.
- Privacy-preserving energy-based generative models for marginal distribution protection. Transactions on Machine Learning Research, 2023.
- Flowchartqa: The first large-scale benchmark for reasoning over flowcharts. In The 3rd Workshop on Document Intelligence. KDD, 2022.
- pyrddlgym: From rddl to gym environments. arXiv preprint arXiv:2211.05939, 2022.
- Knowledge-based regularization in generative modeling. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 2390–2396, 2021.
- Benchmarking differentially private synthetic data generation algorithms, 2022.
- Differentially private synthetic mixed-type data generation for unsupervised learning. Intelligent Decision Technologies, 15(4):779–807, 2021.
- Energy-based models for sparse overcomplete representations. Journal of Machine Learning Research, 4(Dec):1235–1260, 2003.
- On the theory of the brownian motion. Physical Review, 36(5):823, 1930.
- Decaf: Generating fair synthetic data using causally-aware generative networks. Advances in Neural Information Processing Systems, 34:22221–22233, 2021.
- Get real: Realism metrics for robust limit order book market simulations, 2019.
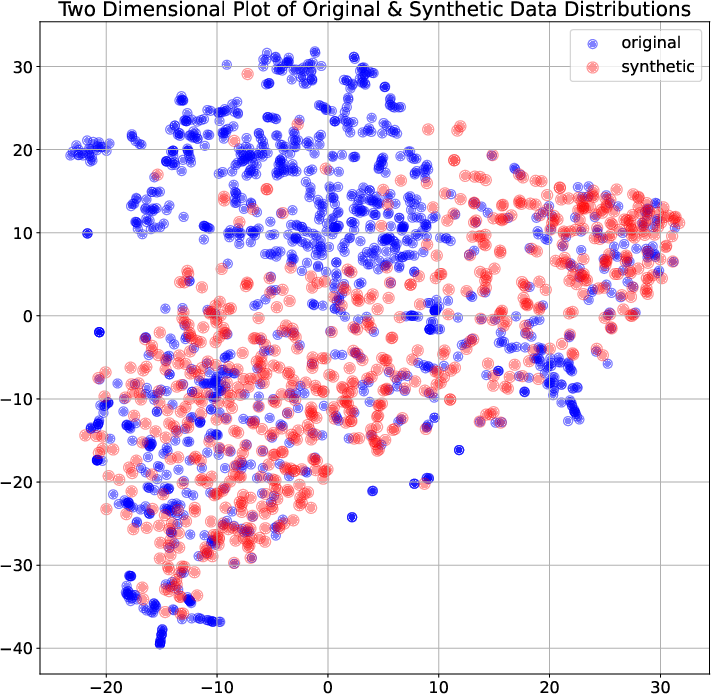
- Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(86):2579–2605, 2008.
- Conditional image generation with pixelcnn decoders. Advances in neural information processing systems, 29, 2016.
- Rory Van Loo. Technology regulation by default: Platforms, privacy, and the cfpb. 2018.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Paul Voigt and Axel Von dem Bussche. The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10(3152676):10–5555, 2017.
- An introduction to the kalman filter. 1995.
- Douglas J White. Real applications of markov decision processes. Interfaces, 15(6):73–83, 1985.
- Quant gans: deep generation of financial time series. Quantitative Finance, page 1–22, Apr 2020.
- On the inherent privacy properties of discrete denoising diffusion models. arXiv preprint arXiv:2310.15524, 2023.
- Time series data augmentation for deep learning: A survey. In International Joint Conference on Artificial Intelligence, 2020.
- Goodness-of-fit test for mismatched self-exciting processes. In International Conference on Artificial Intelligence and Statistics, pages 1243–1251. PMLR, 2021.
- Fair wasserstein coresets, 2023.
- Wasserstein learning of deep generative point process models. Advances in neural information processing systems, 30, 2017.
- Differentially private generative adversarial network, 2018.
- Why do artificially generated data help adversarial robustness. Advances in Neural Information Processing Systems, 35:954–966, 2022.
- Modeling tabular data using conditional gan. Advances in neural information processing systems, 32, 2019.
- Achieving causal fairness through generative adversarial networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, 2019.
- Fairgan: Fairness-aware generative adversarial networks. In 2018 IEEE International Conference on Big Data (Big Data), pages 570–575. IEEE, 2018.
- Fairgan+: Achieving fair data generation and classification through generative adversarial nets. In 2019 IEEE International Conference on Big Data (Big Data), pages 1401–1406. IEEE, 2019.
- A semantic loss function for deep learning with symbolic knowledge. In International conference on machine learning, pages 5502–5511. PMLR, 2018.
- Time-series generative adversarial networks. In NeurIPS, 2019.
- PATE-GAN: Generating synthetic data with differential privacy guarantees. In International Conference on Learning Representations, 2019.
- A review of recurrent neural networks: Lstm cells and network architectures. Neural computation, 31(7):1235–1270, 2019.
- A non-parametric approach to the multi-channel attribution problem. In Web Information Systems Engineering–WISE 2015: 16th International Conference, Miami, FL, USA, November 1-3, 2015, Proceedings, Part I 16, pages 338–352. Springer, 2015.
- A survey on differential privacy for unstructured data content. ACM Computing Surveys (CSUR), 54(10s):1–28, 2022.
- Privbayes: Private data release via bayesian networks. ACM Transactions on Database Systems, 42:1–41, 10 2017.
- Fast learning of multidimensional hawkes processes via frank-wolfe. arXiv preprint arXiv:2212.06081, 2022.
- Transformer Hawkes process. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 11692–11702. PMLR, 13–18 Jul 2020.
- Self-attentive hawkes processes. arXiv preprint arXiv:1907.07561, 2019.
- Differentially private estimation of hawkes process. arXiv preprint arXiv:2209.07303, 2022.
- PrivSyn: Differentially private data synthesis. In 30th USENIX Security Symposium (USENIX Security 21), pages 929–946. USENIX Association, August 2021.
- Adversarial autoaugment. In International Conference on Learning Representations, 2020.
- Deeplob: Deep convolutional neural networks for limit order books. IEEE Transactions on Signal Processing, 67(11):3001–3012, 2019.
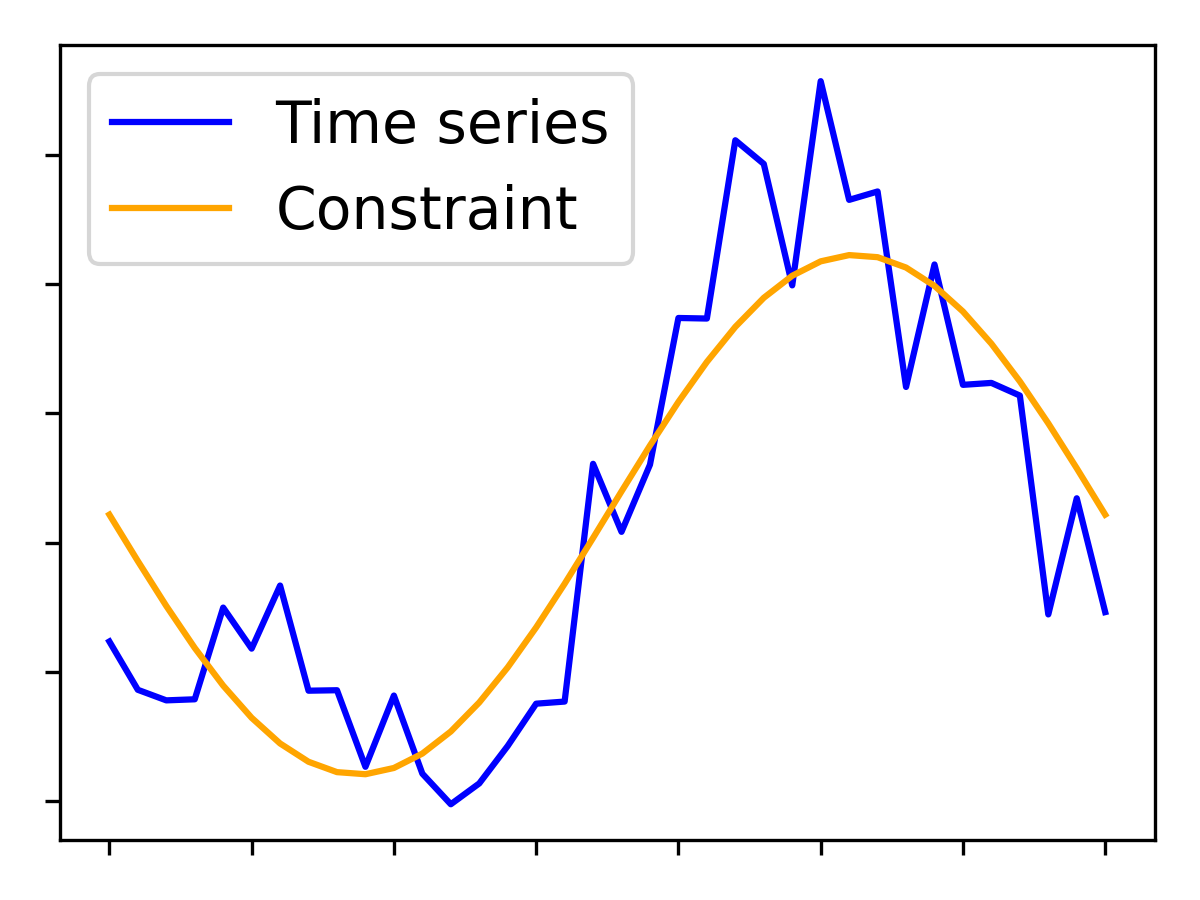
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

