- The paper systematically reviews 395 studies from 2017 to 2024, providing a comprehensive overview of LLM usage in software engineering.
- The study finds that decoder-only models, such as GPT series, dominate tasks like code generation and bug detection due to their generative capabilities.
- The review emphasizes the critical role of data preprocessing and optimization methods like PEFT in enhancing LLM performance across diverse software engineering tasks.
LLMs for Software Engineering: A Systematic Literature Review
Introduction
The application of LLMs in various domains, notably Software Engineering (SE), has grown considerably. Despite the rising interest in the LLM-enhanced software engineering tasks, a holistic understanding of their implementation, impact, and potential drawbacks remains nascent. This systematic literature review (SLR) endeavors to fill this void by carefully evaluating 395 research papers published between 2017 and 2024. The focus is on addressing key research questions concerning the types of LLMs employed in SE, the data handling methods used, optimization and evaluation techniques, and the specific SE tasks addressed.
LLMs in Software Engineering
In SE, LLMs have been adapted from their typical usage in natural language processing to tackle tasks such as code generation, bug detection, and program synthesis. The review categorizes the LLMs into three architectural types: encoder-only, encoder-decoder, and decoder-only, highlighting their distinctive features and illustrating their application in SE contexts. The culmination of this categorization reveals a predisposition towards decoder-only models, such as the GPT series, in SE applications. The prominence of these models can be attributed to their capabilities in text generation, pertinent to many SE tasks.
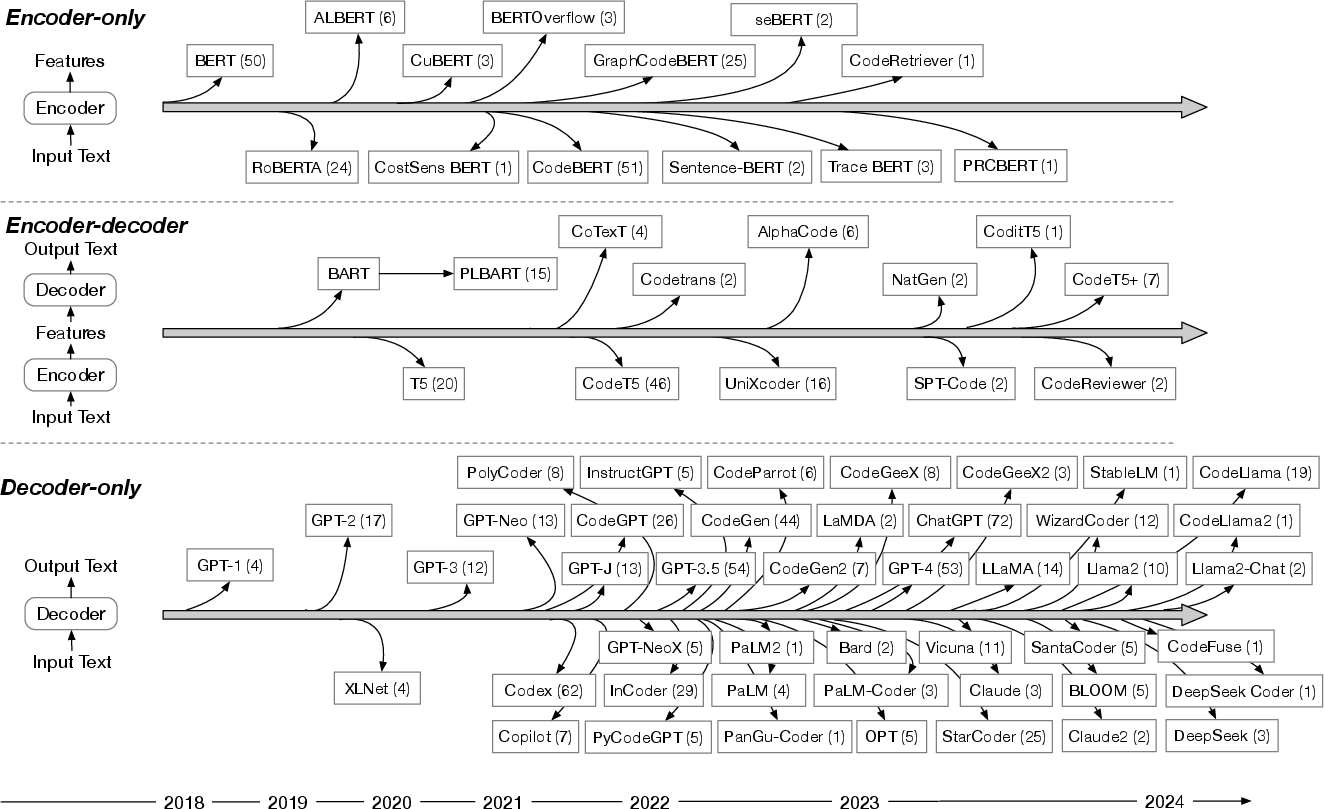
Figure 1: Distribution of the LLMs (as well as LLM-based applications) discussed in the collected papers. The numbers in parentheses indicate the count of papers in which each LLM has been utilized.
Dataset Handling and Preprocessing
The acquisition and preprocessing of datasets are crucial for optimizing the LLMs used in SE. The review identified that most studies relied on open-source and collected datasets, emphasizing the significant role of data availability and processing in maximizing LLM utility. Text-based datasets, in particular, have been extensively used, underscoring the models' ability to manage natural language-related tasks like code documentation and bug descriptions. Data preprocessing steps such as tokenization and segmentation have been vital in refining data inputs for the models.
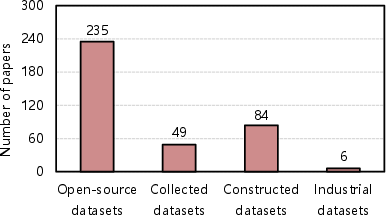
Figure 2: The collection strategies of LLM-related datasets.
Optimization and Evaluation Techniques
The deployment of LLMs in SE is enhanced through specialized optimization techniques, notably Parameter Efficient Fine-Tuning (PEFT). This includes methodologies such as Low-Rank Adaptation and prompt tuning, which refine model outputs efficiently without extensive retraining costs. Additionally, the study addresses the prompting techniques like few-shot and zero-shot prompting that significantly influence tasks such as code generation and automation.
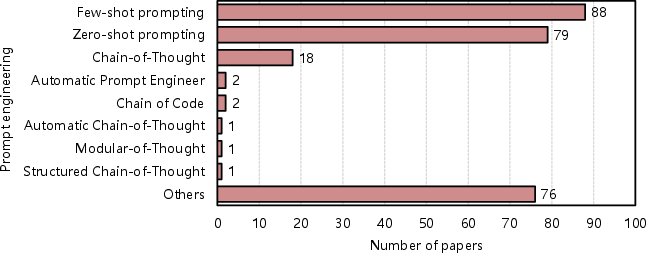
Figure 3: The prompting engineering techniques used in LLMs for SE tasks.
Evaluating the effectiveness of LLMs in SE demands a nuanced approach. The review identifies various metrics tailored to specific SE tasks, such as BLEU scores for generation tasks and Precision/Recall for classification tasks. These metrics provide a framework for assessing model performance rigorously.
Software Engineering Tasks Addressed
LLMs have been effectively utilized across a broad spectrum of SE tasks, conventionally grouped into activities such as requirements engineering, software design, and maintenance. Code generation emerges as a particularly popular application, reflective of the LLMs' strengths in developing executable code from natural language specifications. In program maintenance, tasks like bug fixing and vulnerability detection benefit from the models' ability to understand and analyze code patterns.
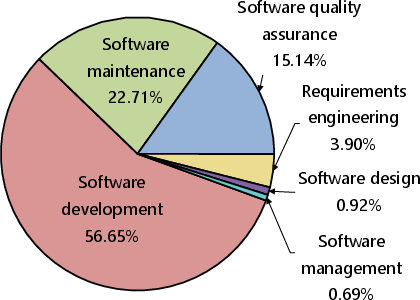
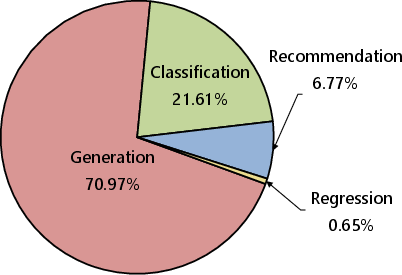
Figure 4: Distribution of LLM utilization across different SE activities and problem types.
Conclusion
This comprehensive review of LLMs' application in software engineering not only categorizes the LLM architectures and datasets used but also underscores the promising advancements and ongoing challenges in this domain. Future research may focus on improving data quality, model interpretability, and broader applicability in less explored SE areas such as software management and design. As LLMs continue to evolve, their incorporation into SE practices promises to enhance efficiency, adaptability, and innovation within the software development lifecycle.