- The paper introduces SCHmUBERT, a novel discrete diffusion probabilistic model that leverages masked token infilling for polyphonic symbolic music generation.
- It employs a convolutional transformer and 1D CNN to transform MIDI token embeddings into effective musical representations.
- Evaluation on the Lakh MIDI dataset shows SCHmUBERT’s superior self-similarity metrics compared to baseline methods in both unconditional generation and infilling scenarios.
Discrete Diffusion Probabilistic Models for Symbolic Music Generation
Introduction
Discrete Diffusion Probabilistic Models (D3PMs) have shown potential in generating symbolic music by applying denoising diffusion techniques to discrete domains. This paper introduces SCHmUBERT, a novel approach to symbolic music generation using D3PMs, specifically designed for Polyphonic Symbolic Music. By leveraging the benefits of discrete diffusion models, this new method achieves state-of-the-art results in both unconditional generation and infilling, outperforming models that were previously applied indirectly to symbolic music.
Background on Symbolic Music Generation
Symbolic music generation involves creating music in a discrete format such as MIDI or musicXML, offering advantages like structured representations and lightweight data encoding. The complexity of this field arises from the challenges of modeling structured sequences of notes, along with complexities inherent in capturing musical styles and compositions.
The D3PMs stem from the broader class of generative models, including DDPMs applied in continuous domains. Earlier research has adapted DDPMs to symbolic music within continuous latent spaces using autosynthetic encodings like VAEs. The symbolic music generation field benefits from leveraging both autoregressive models and more sophisticated approaches like Diffusion Models, which iteratively refine sequences via probabilistic reverse diffusion processes.
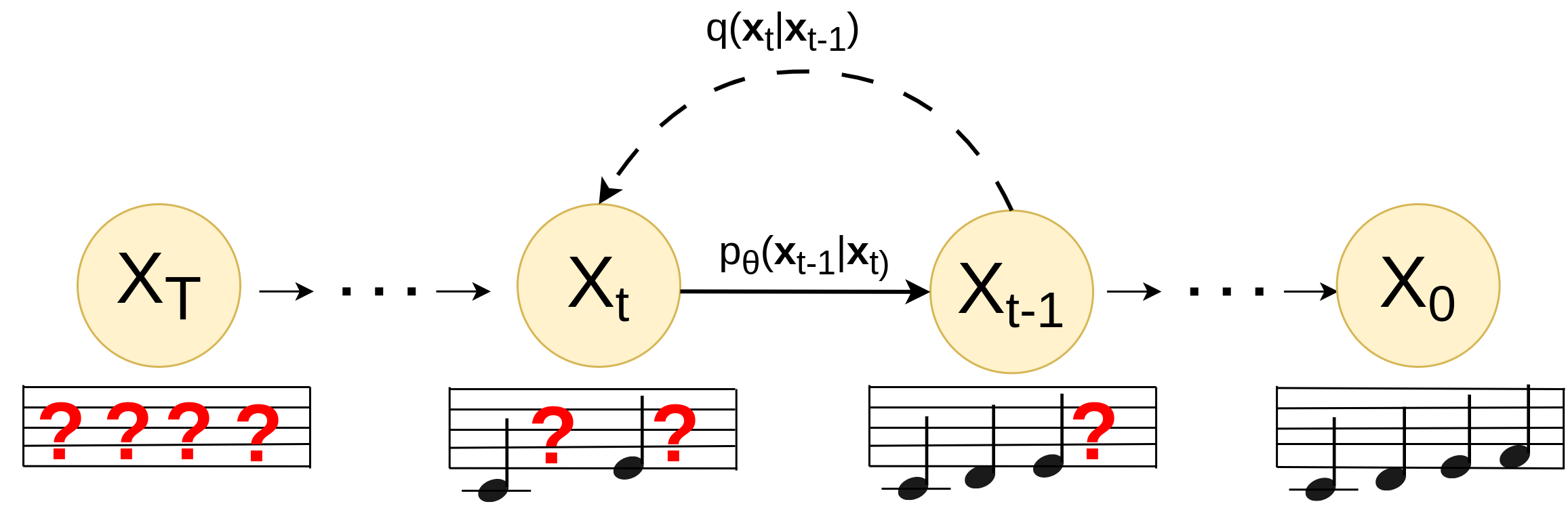
Figure 1: SCHmUBERT architecture. Four adjacent embeddings are convolved into one representation whether they encode a quarter note (such as the examples in the figure) or any other musical material.
SCHmUBERT Architecture
SCHmUBERT employs an Absorbing State D3PM that capitalizes on the masked token infilling capacity, making it highly suitable for polyphonic symbolic music generation. The model architecture consists of a convolutional transformer that processes embeddings at multiple hierarchy levels. Initially, embedding layers transform input indices into 128-dimensional vectors, followed by a 1D CNN that reduces sequence length while expanding the embedding dimension, effectively capturing quarter notes or other structured units. A stack of 24 transformer layers processes these expanded representations, ensuring the model's ability to handle complex music patterns effectively.
Training and Evaluation
The model is trained on the Lakh MIDI dataset, exploiting its diverse collection of symbolic music examples for both monophonic and polyphonic samples. Notably, SCHmUBERT achieves remarkable sample quality with a considerably smaller parameter set compared to competing models, highlighting its efficiency.
Tests conducted across unconditional generation and infilling scenarios demonstrate SCHmUBERT's superiority in self-similarity metrics. These metrics are derived from Gaussian overlapping areas, evaluating consistency and variance relative to ground truth musical sequences. The results affirm SCHmUBERT's capability to produce musically coherent and diverse samples with high fidelity, as evidenced by its metrics surpassing those of baseline models.
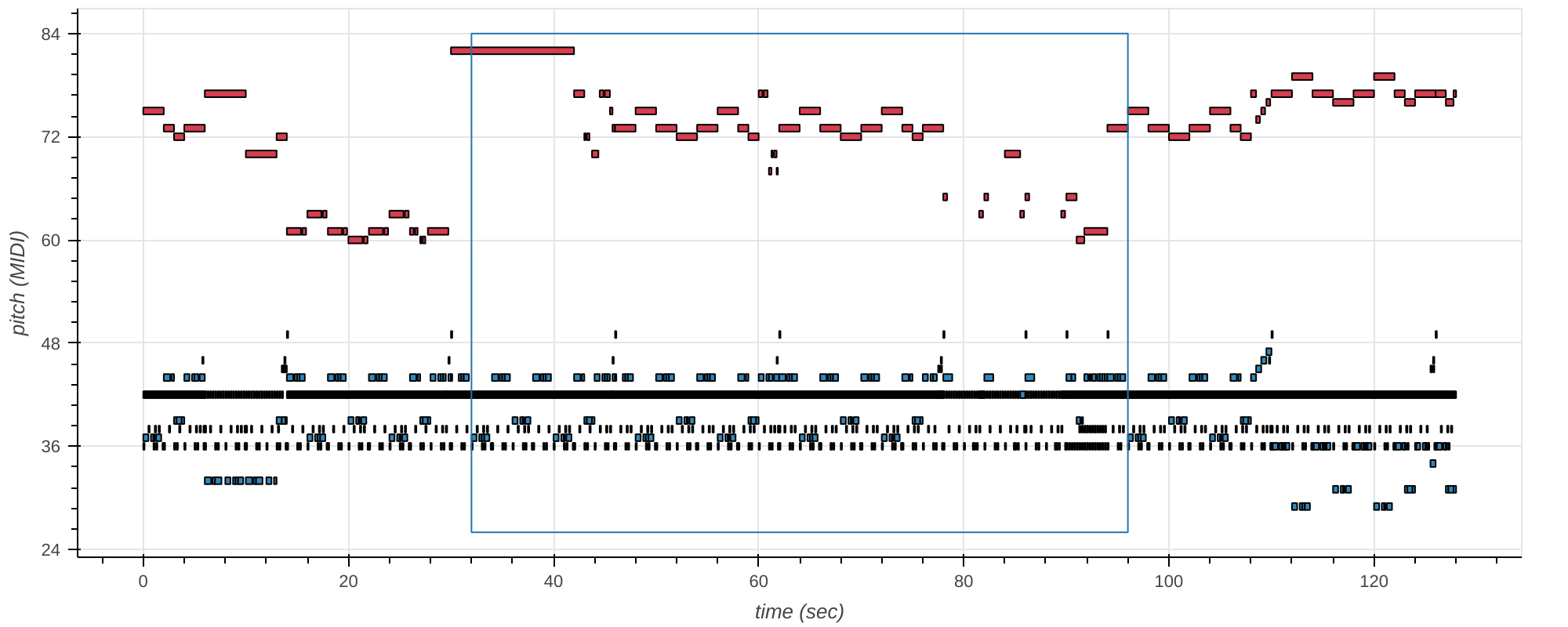
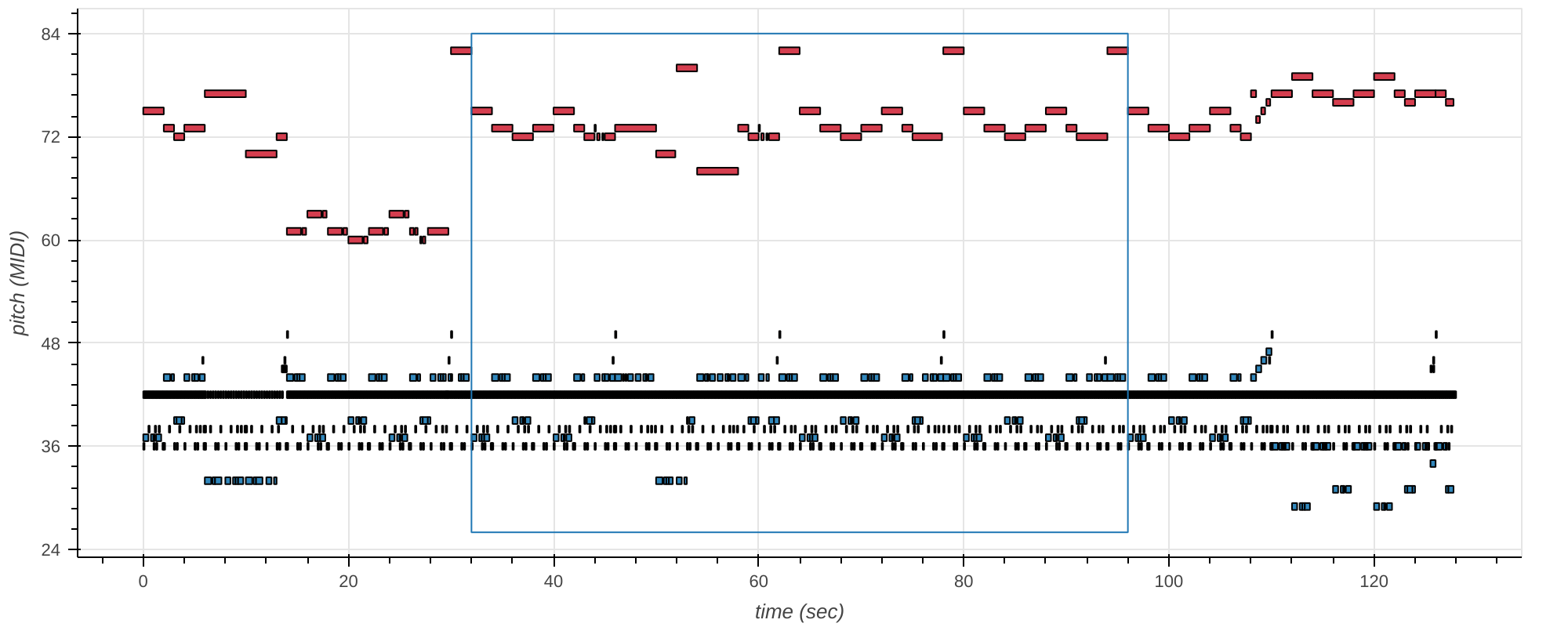
Figure 2: Trio infilling scenario: The top plot shows an original validation sample. The central 512 tokens (blue box) were masked out in all tracks and filled in again by SCHmUBERT (bottom). The tracks are color-coded (red=melody, blue=bass, black=drum). Bass and drum tracks lie in similar pitch regions of the piano roll due to standard MIDI drum encoding.
Discussion on Metric Limitations
While the paper demonstrates noteworthy progress, it also highlights the limitations of current statistical evaluation metrics, which may fail to fully encapsulate the musical quality and fidelity in generated samples. For instance, a simulated annealing approach can yield spurious samples with misleadingly satisfactory metrics due to these metrics' broad aggregation. Thereby, care must be taken when interpreting these scores as definitive indicators of musical excellence.
Conclusion
SCHmUBERT represents an advancement in the field of symbolic music generation, utilizing D3PMs to achieve flexible and interactive generation capacities. The model's ability to perform under both unconditional and conditional infilling tasks marks a significant step toward more dynamic music generation technologies. Future endeavors can further refine evaluation processes and explore novel interaction patterns, maximizing both the qualitative evaluation and the practical utility of the generated music.
The findings hold promise for additional research in fine-tuning D3PMs and enhancing recursive and interactive generation methods, thereby expanding the landscape of creative AI applications in music technology.