- The paper introduces a unimodal-supervised contrastive method that leverages weak supervision to guide effective feature alignment.
- It combines aggregation and alignment fusion strategies to mitigate sensor noise and enhance multimodal classification accuracy.
- Experimental validation on image-text datasets shows significant performance gains, with ablation studies confirming each component’s contribution.
UniS-MMC: Unimodality-supervised Multimodal Contrastive Learning
This paper introduces UniS-MMC, a novel approach to multimodal classification that leverages unimodal supervision for multimodal contrastive learning, aiming to address inherent challenges in traditional fusion methods.
Introduction to Multimodal Learning
Multimodal learning strives to replicate how humans utilize complementary information from diverse modalities for various tasks. Despite advancements in extracting effective unimodal features with pre-trained models such as BERT and ViT, fusion of these unimodal features to create robust multimodal representations remains a complex problem. Typically, aggregation-based methods combine features or decisions across modalities but fail to adequately model inter-modality relationships, leading to performance degradation due to sensor noise and equal treatment of all modalities, regardless of their effectiveness.
UniS-MMC Methodology
UniS-MMC introduces a supervised contrastive method to enhance multimodal learning by aligning unimodal representations with more effective modalities. The approach incorporates unimodal prediction results as weak supervision to evaluate and guide the effectiveness of each modality. The framework learns reliable multitask-related unimodal representations, aligns them contrastively, and optimizes under the supervision of unimodal predictions.
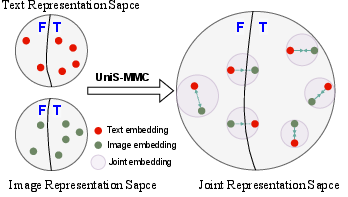
Figure 1: Unimodal representation of a single modality can be either effective or not. The effectiveness of different unimodal representations from the same sample also varies.
Framework and Fusion Strategy
The UniS-MMC framework integrates both aggregation-based and alignment-based fusion strategies. An encoder extracts unimodal features fed into unimodal classifiers, providing predictive supervision that guides modality effectiveness assessment. The proposed contrastive loss considers modality-specific prediction results, defining positive, semi-positive, and negative pairs depending on prediction consistency.
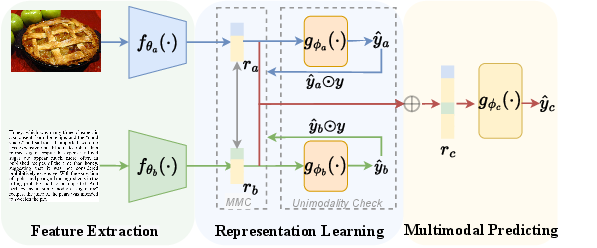
Figure 2: The framework for our proposed UniS-MMC.
Contrastive Loss
UniS-MMC designs a multimodal contrastive loss to align unimodal representations based on prediction results:
Lmmc=∑Lb−mmc(mi,mj)
This loss ensures that effective representations consistently influence the multimodal learning process, leveraging weak supervision to navigate sensor noise and achieving complementary information capture.
Experimental Validation
UniS-MMC was validated on image-text classification datasets UPMC-Food-101 and N24News, showing superior performance compared to state-of-the-art methods. Extensive experiments demonstrated its ability to handle noisy data and enhance classification accuracy significantly.
Ablation Studies
Ablation experiments highlighted the contribution of each UniS-MMC component, such as unimodal prediction tasks and various pair settings, to improve multimodal representation effectiveness and model performance. Incorporating weak supervision from unimodal predictions further optimized alignment in troubled samples.
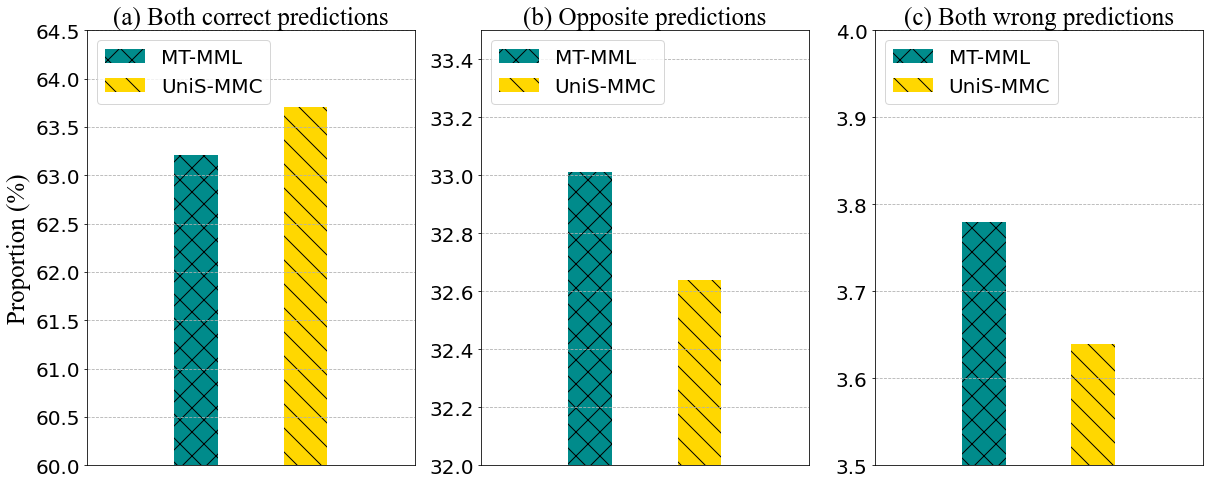
Figure 3: Consistency comparison of unimodal prediction between MT-MML and the UniS-MMC.
Conclusion
UniS-MMC offers a reliable strategy to create trustworthy multimodal representations by smartly aligning unimodal features towards more predictive modalities, reducing biases from ineffective senses. The methodology provides a new avenue for multimodal learning that prioritizes effectiveness under sensor noise, paving the way for more robust AI systems in real-world applications. While not universally applicable to cross-modal retrieval tasks, it excels at multimodal classification challenges reliant on joint representation accuracy.