- The paper introduces Defense-Prefix, a novel token-based mechanism that counters typographic attacks on CLIP without modifying model parameters.
- The methodology leverages Defense and Identity Losses to align text features and maintain semantic consistency, achieving up to 17.70% boost on real-world datasets.
- When applied to RegionCLIP, the approach enhances object detection resilience to adversarial text without fine-tuning, ensuring robust zero-shot learning.
Defense-Prefix for Preventing Typographic Attacks on CLIP
Introduction
The paper "Defense-Prefix for Preventing Typographic Attacks on CLIP" addresses the susceptibility of Vision-Language Pre-trained (VLP) models, specifically CLIP, to typographic attacks. Typographic attacks involve manipulating text within images to elicit misclassifications by the model. The authors introduce a method called Defense-Prefix (DP) to mitigate this vulnerability by enhancing the robustness against such attacks without altering the underlying model parameters. This novel approach leverages a token-based prefix strategy that can be seamlessly integrated into downstream tasks like object detection.
Problem Statement
VLP models like CLIP are known for their high accuracy in zero-shot learning across diverse vision-language tasks. However, they are vulnerable to typographic attacks, where textual content within images leads to misclassification (Figure 1). Traditional defenses modify model parameters through methods such as fine-tuning or architectural changes, which can degrade performance and complicate downstream task integration.
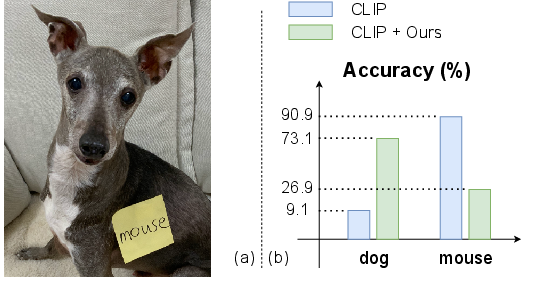
Figure 1: (a) Image of a dog with a yellow tag that states ``mouse''. (b) Misclassification in CLIP against the image.
Defense-Prefix Methodology
Defense-Prefix introduces a token, [DP], appended before class names in text prompts processed by CLIP's text encoder. This strategy builds on class-prefix learning, commonly used in subject-driven image generation, to create text features resistant to typographic manipulation. The proposed DP learning involves two key components:
- Defense Loss: This cross-entropy loss ensures the learned DP token effectively neutralizes typographic attacks by aligning text features (Figures 2 and 3).
- Identity Loss: Utilizes KL-divergence to maintain semantic consistency between original and altered text features, preserving the model's classification accuracy on unaltered datasets (Figure 2).
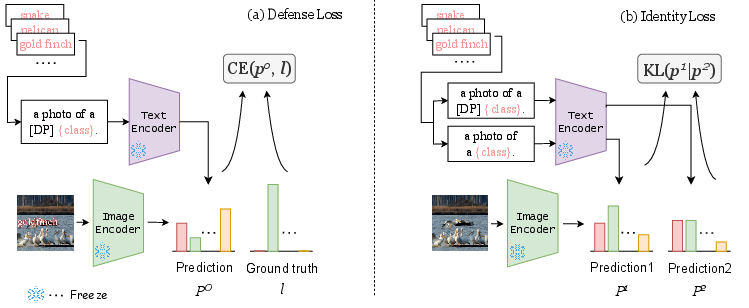
Figure 2: Method overview. We keep the image encoder and text encoder of CLIP frozen. Our method trains only the DP vector, which is a word embedding for [DP].

Figure 3: Typographic attack datasets. (Left: a sample from synthetic typographic attack datasets, Right: a sample from our real-world typographic attack dataset.)
Experimental Results
The authors validate their approach using both synthetic and real-world typographic attack datasets. The Defense-Prefix demonstrates significant performance improvements, with typographic attack accuracy increasing by 9.61% on synthetic datasets and 17.70% on real-world datasets while maintaining nearly unchanged accuracy on original datasets.
The RTA-100 dataset, curated for the study, provided a robust real-world typographic dataset for training and evaluation, further proving DP's effectiveness (Figure 4).

Figure 4: Images sampled from our typographic attack COCO dataset. The dataset consists of images from COCO with synthesized text.
Application to Object Detection
By applying DP in the RegionCLIP framework for object detection, the method shows substantial resilience against typographic attacks without compromising accuracy in standard inference scenarios. The implementation does not require fine-tuning RegionCLIP, emphasizing the method's compatibility with existing VLP applications (Figure 5).

Figure 5: Visualization of RegionCLIP and RegionCLIP+Ours zero-shot inference on the typographic attack COCO dataset.
Conclusion
Defense-Prefix presents a scalable, non-intrusive solution to enhance VLP model robustness against typographic attacks without sacrificing original performance. The proposed method preserves zero-shot learning efficacy, requires minimal computational adjustments, and is applicable across various downstream tasks. Future work could explore similar strategies against other adversarial attack forms on VLP models.
This paper elucidates a versatile approach, contributing significantly to secure and reliable real-world implementations of VLP models.

