- The paper introduces UniEval, a novel evaluation framework that converts NLG tasks into Boolean QA for comprehensive multi-dimensional analysis.
- UniEval leverages pseudo data construction and multi-task learning to robustly evaluate coherence, fluency, and relevance in text generation.
- Experimental results show a 23% improvement in correlation with human judgments in summarization and strong zero-shot evaluation capabilities.
Towards a Unified Multi-Dimensional Evaluator for Text Generation
The paper "Towards a Unified Multi-Dimensional Evaluator for Text Generation" (2210.07197) addresses the challenge of evaluating Natural Language Generation (NLG) models using a more comprehensive framework than traditional similarity-based metrics. It introduces UniEval, a unified multi-dimensional evaluator, which re-frames evaluation tasks as Boolean QA problems, enabling a single model to assess multiple dimensions like coherence and fluency.
Introduction
Traditional NLG evaluation metrics such as ROUGE and BLEU focus on lexical overlap between generated text and reference text, sometimes missing nuances of quality as models advance in capability. UniEval reimagines evaluation by converting NLG assessments into Boolean QA tasks, thus allowing for multi-dimensional and more accurate evaluations that align closely with human judgment.
Conversion of evaluation dimensions into a Boolean QA format allows UniEval to ask specific yes/no questions regarding the evaluation of dimensions like coherence ("Is this a coherent summary to the document?"). This design simplifies the use of evaluators in multi-dimensional settings and enhances the incorporation of external knowledge via intermediate multi-task learning.
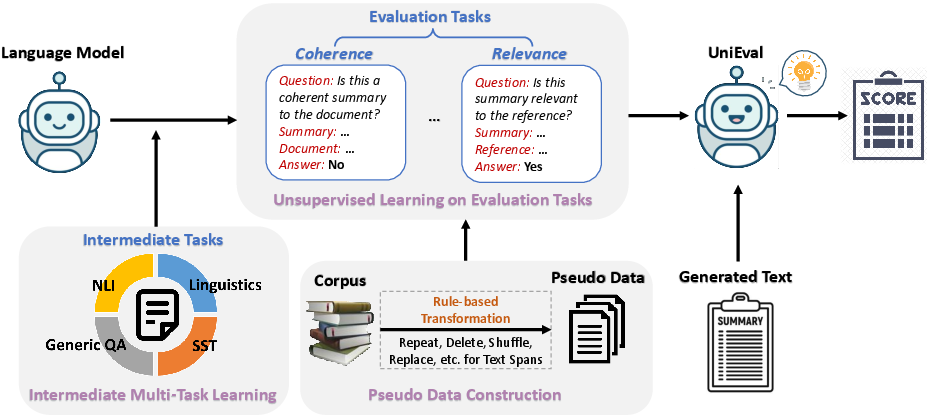
Figure 1: The overall framework of UniEval, converting NLG tasks into a unified QA format for evaluation.
Method
UniEval operates by training a model to evaluate text across different dimensions using pseudo data construction and multiple supervised stages. It constructs synthetic positive and negative samples based on designed rules to train on tasks like coherence, consistency, fluency, and relevance in NLG.
Beyond evaluation tasks, UniEval introduces intermediate multi-task learning from broader QA, linguistic, and self-supervised datasets. This stage enhances external knowledge absorption necessary for complex evaluations. By leveraging datasets including BoolQ and CoLA, UniEval increases its robustness across varied dimensions, transferring efficiently even to unseen tasks and dimensions.
Experiments and Results
UniEval demonstrates superior predictive correlation with human judgments across multiple NLG tasks compared to state-of-the-art single-dimensional and unified evaluators. In summarization, UniEval achieves a 23% higher correlation for coherence, relevancy, and fluency dimensions than BARTScore.
Furthermore, UniEval shows remarkable zero-shot learning ability, proving effective for unseen evaluation dimensions by simple question modifications. It outperforms existing evaluators in dialogue response generation tasks, achieving substantial improvements in transfer and extensibility, as exemplified by its performance in evaluation on the "understandability" dimension.
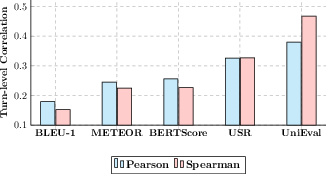
Figure 2: Zero-shot performance on the "understandability" dimension in dialogue response generation.
Conclusion
UniEval sets a new direction for developing evaluators that can accommodate various dimensions and tasks seamlessly. By unifying evaluation methods into a QA format, UniEval simplifies the model process while incorporating external knowledge from diverse datasets to improve evaluation quality. Its strong correlation with human assessments and zero-shot adaptability suggest promising advancements in deploying multi-dimensional evaluators in NLG systems.

