- The paper introduces a two-step approach using a BERT-based Zero-Cardinality Classifier to filter non-triple sentences before extraction.
- The paper reveals that including zero-cardinality sentences can degrade the F1 score by 10–15%, challenging previously optimistic benchmarks.
- The paper emphasizes the need for robust evaluation standards and heterogeneous datasets to improve practical knowledge base construction.
The paper "90% F1 Score in Relational Triple Extraction: Is it Real?" examines relational triple extraction models when evaluated under realistic experimental conditions, including sentences with zero-cardinality. This study challenges the previously optimistic performance metrics of state-of-the-art (SOTA) models by incorporating a more complex dataset structure and introducing a two-step modeling approach to enhance model efficacy.
Relational triple extraction, which involves identifying entity-relation-entity triples from textual data, is vital for constructing robust knowledge bases. Earlier models demonstrated remarkable success under restrictive settings, focusing only on sentences that predominantly contain triples. This paper emphasizes the logical necessity to extend this task to include sentences with no relational triples, as such sentences frequently occur in practical applications.
The authors conducted a thorough benchmark study using the New York Times (NYT) dataset, which revealed substantial degradation in performance indicators such as F1 scores—by up to 10-15%—when zero-cardinality sentences were included. This underscores the limitation of prior models in handling more realistic and heterogeneous datasets.
Two-Step Modeling Approach with Zero-Cardinality Classifier
To address the challenge posed by zero-cardinal sentences, the authors propose a BERT-based Zero-Cardinality Classifier (ZCC) designed to filter out sentences lacking relational triples. The model utilizes either binary classification or multi-class multi-label classification to determine the presence of triples using linguistic clues without identifying specific entities.
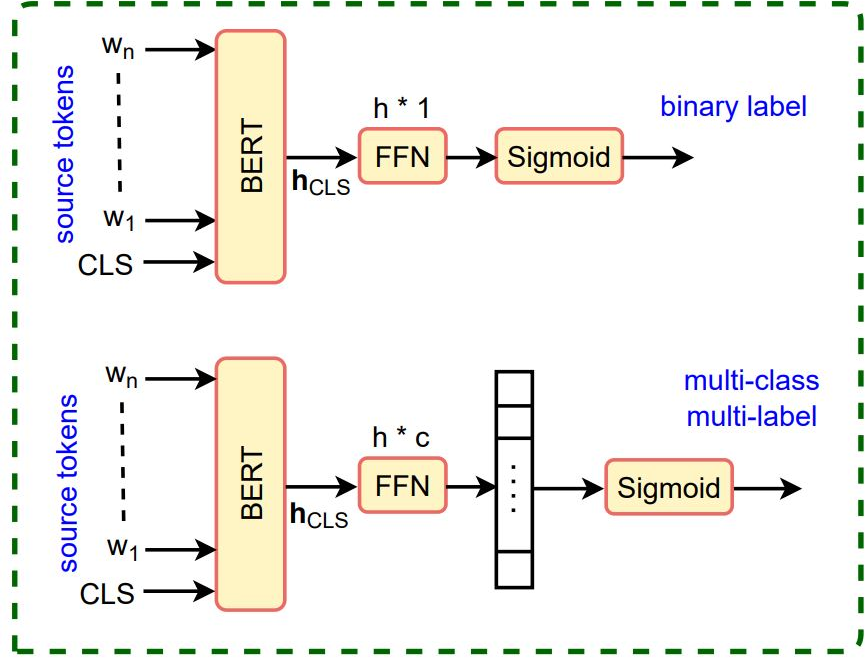
Figure 1: Architecture of our zero-cardinality classifier. c is the number of relations.
This two-step approach first applies the ZCC on the dataset to segregate sentences, followed by employing existing SOTA models for triples extraction only on sentences identified as containing relational triples. The results illustrate competitive performance compared to traditional end-to-end models, suggesting a potential operational edge in terms of training efficiency and resource management.
Experimental Setup and Results
Comprehensive experiments conducted using the NYT24* and NYT29* datasets encompass training and evaluation on both sentences with and without zero triples. These diverse test conditions evaluate the robustness of models across different real-world scenarios. The study records a significant variance in performance across test settings, reflecting previous overestimations due to simplified evaluations.
Comparison metrics included precision, recall, and F1 scores, demonstrating approximated gains of 8% in performance for models due to the novel two-step strategy. Nonetheless, further refinement is required to support consistent model performance on zero-cardinality test sets, necessitating adaptive methods for training models with heterogeneous datasets.
Implications and Future Directions
The paper presents a coherent framework for assessing relational triple extraction models that is both challenging and reflective of practical applications. It asserts that current models benefit from simplifying assumptions within existing datasets, highlighting the need for benchmark standards incorporating diverse sentence structures. This work also paves the path for future exploration into zero-cardinality sentence recognition and extraction strategies, potentially improving AI's understanding of natural language context.
Conclusion
The integration of zero-cardinality evaluation not only bridges a critical gap in relational triple extraction research but also prompts significant reconsiderations in model design and training paradigms. The proposed two-step approach demonstrates improved adaptability and efficiency in handling complex setups, suggesting its utility in advancing research in knowledge base construction. Future work could explore optimization techniques within zero-cardinality classifiers to ensure robust performance across varying dataset conditions.