RRMSE Voting Regressor: A weighting function based improvement to ensemble regression
Published 11 Jul 2022 in cs.LG | (2207.04837v1)
Abstract: This paper describes the RRMSE (Relative Root Mean Square Error) based weights to weight the occurrences of predictive values before averaging for the ensemble voting regression. The core idea behind ensemble regression is to combine several base regression models in order to improve the prediction performance in learning problems with a numeric continuous target variable. The default weights setting for the ensemble voting regression is uniform weights, and without domain knowledge of learning task, assigning weights for predictions are impossible, which makes it very difficult to improve the predictions. This work attempts to improve the prediction of voting regression by implementing the RRMSE based weighting function. Experiments show that RRMSE voting regressor produces significantly better predictions than other state-of-the-art ensemble regression algorithms on six popular regression learning datasets.
The paper introduces the RRMSE Voting Regressor that dynamically weights base learners inversely to their RRMSE, enhancing prediction accuracy.
It applies a computationally efficient, scale-invariant method to assign weights based on training error across diverse datasets.
Empirical results show statistically significant improvements over traditional uniform and dynamic weighting approaches in ensemble regression.
RRMSE Voting Regressor: A Weighting Function Based Improvement to Ensemble Regression
Introduction
The paper introduces the RRMSE Voting Regressor, a novel ensemble regression method that leverages the Relative Root Mean Square Error (RRMSE) as a dynamic weighting function for integrating predictions from heterogeneous base learners. The motivation stems from the limitations of uniform weighting in standard voting regressors, which do not account for the relative predictive performance of individual models. By assigning weights inversely proportional to each learner's RRMSE, the proposed method aims to enhance predictive accuracy and robustness across diverse regression tasks.
Background: Ensemble Regression and Weighting Strategies
Ensemble learning for regression typically involves aggregating predictions from multiple base models to reduce variance and improve generalization. Two primary strategies are prevalent: averaging methods (e.g., bagging, voting) and boosting methods. The focus here is on averaging methods, particularly bagging and voting.
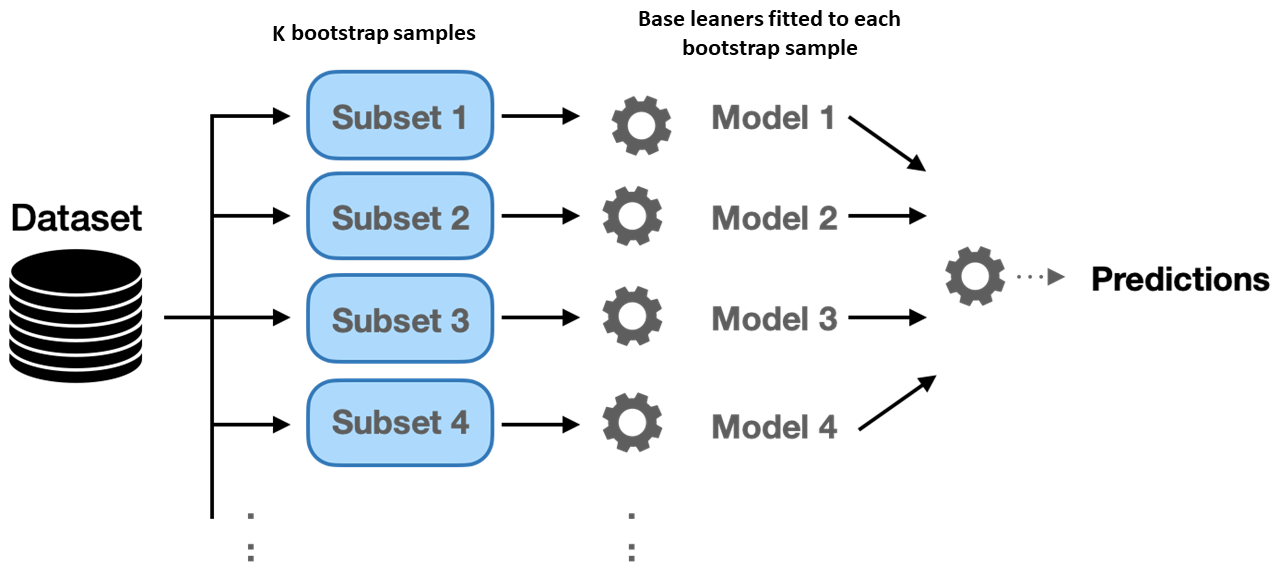
Bagging constructs multiple models on bootstrap samples and averages their outputs, primarily reducing variance (Figure 1).
Figure 1: Bagging consists in fitting several base models on different bootstrap samples and building an ensemble model that averages the results of these base learners.
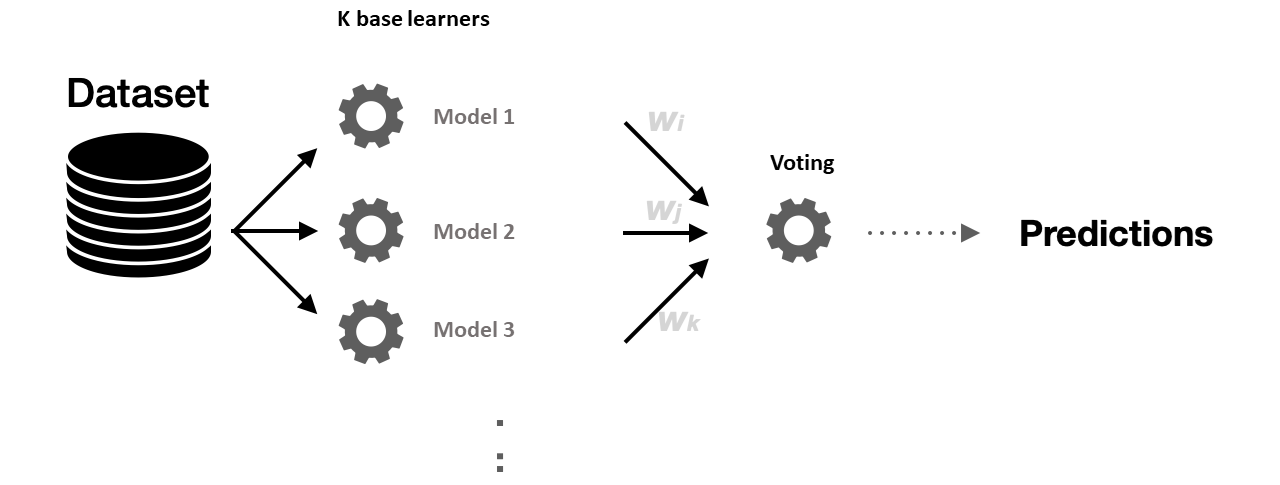
Voting regression, in contrast, fits each base model on the entire dataset and combines their predictions, often using uniform weights (Figure 2).
Figure 2: Voting consists in fitting several base models on the whole dataset and building an ensemble model that averages the results of these base learners.
The integration step in ensemble regression can utilize constant or non-constant weighting functions. Constant weights (e.g., uniform averaging) are simple but ignore model-specific performance. Non-constant (dynamic) weights can be static (based on prior knowledge) or adaptive (based on model performance, e.g., local accuracy or error metrics).
RRMSE Voting Regressor: Methodology
The RRMSE Voting Regressor introduces a dynamic weighting scheme based on the RRMSE of each base learner. RRMSE is defined as:
This metric normalizes the RMSE by the squared sum of predictions, providing a scale-invariant measure of error. The algorithm proceeds as follows:
Constant Calculation: Compute a small constant to prevent division by zero in subsequent steps.
RRMSE Computation: For each base learner, calculate its RRMSE on the training set.
Weight Assignment: Assign each learner a weight inversely proportional to its RRMSE, normalized so that the weights sum to one.
Prediction Integration: For each test instance, compute the final prediction as the weighted sum of base learner outputs.
This approach ensures that models with lower relative error contribute more to the ensemble prediction, dynamically adapting to the strengths of individual learners.
Experimental Evaluation
The RRMSE Voting Regressor was evaluated on six regression datasets: Abalone, Car, Diamond, Airfoil, Smart Grid Stability, and Elongation. The base learners included Linear Regression, K-Nearest Neighbors, Stochastic Gradient Descent, and Random Forest, all implemented using default hyperparameters in Scikit-Learn.
Comparisons were made against three ensemble baselines:
VRU: Voting Regressor with Uniform Weights
BR: Heterogeneous Bagging Regressor with Uniform Weights
Performance was assessed using MAE, MSE, RMSE, and R2 metrics. Statistical significance was evaluated using the Friedman aligned rank test and post-hoc pairwise comparisons.
Results and Analysis
The RRMSE Voting Regressor achieved the best or second-best performance across all datasets and metrics, outperforming BR and DWR with statistical significance (p<0.05) and showing marginal but consistent improvements over VRU. Notably, on five out of six datasets, RRMSE achieved the top rank, with only the Abalone dataset favoring VRU.
Key findings include:
Consistent superiority over DWR and BR: RRMSE outperformed these methods on all datasets, with highly significant p-values (p<0.01).
Marginal improvement over VRU: While the difference with VRU was not always statistically significant, RRMSE achieved the best average rank overall.
Robustness across domains: The method demonstrated effectiveness on datasets with varying sizes, feature counts, and domains, indicating strong generalizability.
Practical Implications and Implementation Considerations
The RRMSE Voting Regressor is straightforward to implement in any ensemble regression pipeline. The weighting mechanism is computationally efficient, requiring only a single pass over the training data to compute RRMSE for each base learner. The method is agnostic to the choice of base learners and can be integrated with any regression model supporting the standard fit/predict interface.
Resource Requirements: The method incurs negligible overhead compared to standard voting, as RRMSE computation is lightweight. The main computational cost remains in training the base learners.
Scalability: The approach scales linearly with the number of base learners and data points. For large ensembles or datasets, parallelization of base learner training is recommended.
Limitations: The method assumes that RRMSE on the training set is a reliable proxy for generalization error. In cases of severe overfitting or data drift, this assumption may not hold, potentially degrading performance.
Theoretical and Practical Implications
Theoretically, the RRMSE Voting Regressor provides a principled mechanism for weighting ensemble members based on relative predictive error, addressing the limitations of uniform weighting. It aligns with the bias-variance decomposition, as it adaptively reduces the influence of high-error models, potentially lowering both bias and variance in the ensemble prediction.
Practically, the method is attractive for real-world regression tasks where base learners exhibit heterogeneous performance. It is particularly beneficial in scenarios lacking domain knowledge for manual weight assignment and where model diversity is high.
Future Directions
Potential avenues for further research include:
Automated base learner selection: Integrating model selection strategies (e.g., random search, Bayesian optimization) to optimize the ensemble composition.
Extension to local weighting: Adapting the RRMSE weighting to be instance-specific, potentially leveraging local error estimates.
Robustness to data drift: Investigating mechanisms to update weights dynamically as new data arrives or distribution shifts occur.
Application to other ensemble paradigms: Exploring the use of RRMSE-based weighting in boosting or stacking frameworks.
Conclusion
The RRMSE Voting Regressor offers a simple yet effective improvement to ensemble regression by dynamically weighting base learners according to their relative predictive error. Empirical results demonstrate statistically significant gains over established ensemble methods across diverse datasets. The approach is computationally efficient, model-agnostic, and readily deployable in practical regression pipelines. Future work may focus on automated model selection, local weighting strategies, and adaptation to non-stationary environments.